IMA4 2017/2018 P40
Sommaire
- 1 Présentation générale
- 2 Analyse du projet
- 3 Préparation du projet
- 4 Réalisation du Projet
- 5 État de l'art
- 5.1 Présentation générale
- 5.2 Au cœur de l'oignon
- 5.3 Un peu de statistiques
- 6 Expérimentations
- 7 Annexes
- 8 Bibliographie
- 9 Documents Rendus
Présentation générale
Description
Notre projet s’intitule "Exploration du réseau d'anonymisation Tor" et consiste à découvrir le principe de fonctionnement de ce dit réseau pour ensuite le mettre en pratique et enfin l’analyser en profondeur. Tor (Acronyme de "The Onion Router", le routage en oignon), est un réseau mondial décentralisé apparu en 2002 en version alpha et qui permet de lutter contre la surveillance et la censure. Sous le terme décentralisé se cache des milliers de serveurs mis à disposition par des bénévoles. Ces machines, appelées nœuds, agissent comme des relais pour permettre une anonymisation des connexions internet. Lorsqu’on fait référence à Tor, l’amalgame est souvent fait avec le logiciel Tor Browser, qui lui n’est qu’un navigateur (basé sur Firefox) qui envoie les connexions dans le réseau Tor. L'appellation du protocole “routage en oignon” fait référence à la manière dont les données sont encapsulées puis “épluchées” au cours d’un trajet dans un circuit tor.
Tor est utilisé dans deux situations :
- Accéder au web "normal" : la requête émise par l'utilisateur est transférée jusqu'au serveur ciblé par un circuit composé de trois nœuds.
- Accéder aux services cachés : l'utilisateur et le serveur ciblé s'entendent sur un point de rendez-vous pour communiquer.
Objectifs
Ce projet peut se découper en trois grandes parties. En premier lieu, nous commencerons par un travail bibliographique afin de nous forger des connaissances solides sur le réseau Tor. Suivra une partie où nous mettrons en application notre savoir au travers de trois expériences qui seront : la navigation sur Internet avec le réseau Tor, la création d’un noeud et finalement l’hébergement d’un service caché. La troisième partie sera consacrée à des tests d’efficacité du réseau. Nous visualiserons les requêtes reçues par un serveur web (sous notre administration) lorsqu’on accède à celui-ci via Tor. Nous évaluerons ensuite la vulnérabilité des nœuds du circuit. Enfin, nous nous attaquerons à une autre particularité de Tor, à savoir les services cachés. A nouveau, nous testerons les limites de cette fonctionnalité pour voir par exemple s’il est possible de déterminer la localisation du serveur hébergeant le service. Evidemment, s'agissant d'un projet d'exploration, cette liste d’objectifs est sujette au changement et pourra se voir allongée par la suite, du moins nous l'espérons.
Analyse du projet
Positionnement par rapport à l'existant
A l’heure d’aujourd’hui, quand on parle d’anonymisation, Tor est souvent le seul service évoqué. Bien que ce ne soit pas le cas, il est vrai qu’il possède une place de leader dans son domaine. Ce qui le rend si populaire est sans doute la simplicité des applications gravitant autour de ce réseau, le tout accompagné d’une communauté très active. Pour ne citer qu’un exemple, Tor Browser s’installe en quelques minutes de la même manière que Firefox. Sa seconde force réside dans sa capacité à pouvoir accéder au web "normal" sans que le serveur ciblé ne connaissent l’origine de la connexion. Tor a été conçu pour ce genre d'utilisation, c’est pour cela que les connexions aux services cachés sont plus lentes que sur d'autre réseau d'anonymisation. Mis à part les aspects purement techniques et les raisons ci-dessus, rien d'autre ne pourrait distinguer Tor de ses concurrents.
Analyse du premier concurrent
I2P et Tor sont conçus pour permettre la mise en relation de deux machines sans révéler leur adresse IP réelle et sont donc assez similaire sur le principe. Bien qu’il soit également possible d’accéder au web "normal" avec I2P, ce n’est pas son but premier. Ce réseau privilégie l’utilisation des services cachés, de ce fait il est plus rapide d’y naviguer dessus. En termes de différence technique, on peut citer le fait que les tunnels (équivalent des circuits Tor) sont unidirectionnels contrairement à Tor.
Analyse du second concurrent
Freenet possède quant à lui un autre type d’usage en proposant le partage de fichiers de manière anonyme et résistante à la censure. En effet, contrairement à Tor et I2P, Freenet assure la pérennité des données grâce à une redondance des fragments de fichiers. Freenet est sur ce point similaire au protocole BitTorrent puisqu’un utilisateur téléchargeant un fichier est susceptible de le redistribuer plus tard à condition de toujours l’avoir en cache. En plus de sa bande passante, l’utilisateur est libre d’allouer une partie de son disque dur pour stocker les fichiers du réseau. Un fichier populaire, de par ce procédé, a plus de chance de rester disponible. Pour garantir l’anonymat, un client possède une liste de vingt nœuds qu’il peut interroger. Si aucun des nœuds ne possède ce fichier, ces vingt nœuds interroge à leur tour leurs voisins et ainsi de suite. Ainsi quand le fichier transite vers le client, aucun nœud ne sait si celui qui le précède est le demandeur.
Scénario d'usage du produit ou du concept envisagé
Alice est une journaliste dans un pays où les libertés individuelles sont bafouées, mais elle souhaite partager avec le reste du monde son quotidien en s’assurant que, dans un premier temps son gouvernement ne sache pas ce qu’elle envoie comme information, mais aussi qu’il ne sache pas à qui elle les envoie.
Alice peut donc utiliser le réseau Tor, afin dans un premier temps de crypter sous plusieurs couches SSL son message, mais également en passant par plusieurs nœuds pour brouiller les pistes qui voudraient remonter à elle ou au serveur avec qui elle communique.
Seulement, deux problèmes se posent à Alice, si elle communique avec Bob sur un réseau Tor Web classique, alors tout le trafic entre le nœud 3 et Bob sera en clair (il peut être crypté via https bien évidemment, mais il ne sera pas crypté d’un point de vue Tor), ainsi, on peut lire le contenu du message envoyé à Bob, et le corréler avec le contenu qui trafique dans les nœuds Tor pour remonter à Alice.
Ensuite, les nœuds du réseau sont publics, un gouvernement peut donc très bien en bloquer l’accès, voire pire, le rendre illégal et imposer des sanctions lourdes en dissuasion. Pour régler ce problème, Tor Project propose d’envoyer dans un premier temps le software par un média non suspect (CD par exemple), et aussi dans un second temps d’allouer à Alice un bridge, un nœud d’entrée Tor complètement secret, réservé pour l’accès au réseau Tor dans les pays peu libres.
Ainsi, du point de vue du gouvernement qui essaierait de sniffer les paquets envoyés et reçus par Alice, ils ne verraient que du charabia sous SSL entre elle et un serveur qui n’a rien de suspect si c’est un bridge.
Réponse à la question difficile
La question difficile posée durant la présentation orale de notre sujet nous amène à analyser le comportement de Tor concernant le ciblage publicitaire mis en oeuvre par l’utilisation des cookies. Premièrement, il est bon de savoir que ce navigateur n'est qu'un fork du très connu Mozilla Firefox sur lequel il est possible d'utiliser le réseau d'anonymisation TOR. Rien que par ce premier point, on comprend rapidement que le réseau en tant que tel n'est nullement responsable du ciblage publicitaire. Tor n'est qu'un réseau permettant l'acheminement de paquets TCP, paquets pouvant encapsuler entre autres du HTTP/S. Il est donc tout à fait possible de retrouver une en-tête HTTP/S de type Set-Cookie ou Cookie qui permettra dans le meilleur des cas de faciliter la navigation de l'utilisateur ou pire de le cibler. Le ciblage, opéré principalement par les régies publicitaires, utilise ce que l'on appelle les cookies tierce partie. Lorsqu'on se connecte à une page web, notre client effectue des requêtes au serveur web qui sont dites internes quand le domaine correspond à celui sur lequel on se trouve ou tierce partie quand la cible est un domaine différent. Les cookies tierce partie désignent donc les cookies envoyés par ce tiers. Dès lors, peu importe le site consulté, le client sera en état de transmettre des infos d'un site interrogé auparavant à condition qu'ils aient la même régie. Les navigateurs Internet actuels permettent de désactiver les cookies tierce partie et Tor Browser a fait ce choix par défaut, n'autorisant que les cookies internes.
Préparation du projet
Cahier des charges
Choix techniques : matériel et logiciel
Ce projet purement informatique ne nécessite aucun matériel à l'exception d'un serveur connecté sur le réseau de l'école et ayant accès à la ligne SDSL. Du côté des logiciels, nous commencerons par exploiter Tor Browser et Firefox afin de naviguer sur Internet en passant par le réseau Tor. Nous verrons ainsi l'utilité d'utiliser le navigateur de la fondation Tor. Dans un second temps, nous créerons des machines virtuelles sur le serveur Chassiron afin d'ajouter un nœud au réseau Tor ou encore d’héberger un service caché (sur un serveur web tel que Nginx ou Apache). La mise en place de ces machines nécessitera les logiciels Xen (pour la virtualisation) et LVM (pour la création de volume logique). Finalement, nous installerons Tor pour être en mesure de communiquer sur ce réseau que nous contrôlerons totalement, et nous pourrons réaliser divers test (tcpdump par exemple) sur les machines virtuelles.
Concernant la partie analyse et sécurité, Wireshark ou tcpdump se révéleront être des outils pratiques pour analyser les paquets reçus sur une interface réseau.
Liste des tâches à effectuer
- État de l'art technique : les recherches documentaires s’effectueront tout au long du projet mais beaucoup d'importance y sera consacré dans un premier temps. 🔨
- Installation de Tor Browser et comparaison avec un Firefox classique. ✅
- Création et configuration d'une machine virtuelle connectée sur la ligne SDSL. ✅
- Ajout d'un nœud au réseau. ✅
- Installation d'un serveur web sur une autre VM pour héberger un service caché. ✅
- Mise en place d'un réseau privé Tor pour avoir la main sur l'ensemble de la chaîne de transmission. ✅
- Réalisation d'un serveur web permettant de connaitre l'IP qui l'a contacté. ✅
- Script pour automatiser la capture des paquets avec tcpdump. 🔨
- Programme C pour contrôler et configurer Tor à la volé. 🔨
- Programme C (Bash ?) pour choisir le pays du nœud de sortie. ✅
Calendrier prévisionnel
Faire un Gantt
Réalisation du Projet
La segmentation en semaine ne se prêtant pas très bien à ce genre de projet, nous avons choisi de rester synthétique dans cette partie. Tous les points sont ou seront évidements explicités dans la suite de Wiki, ce listing permet juste de faire une chronologie des tâches effectuées et de décrire les problèmes rencontrés accompagnés de réponses courtes.
Feuille d'heures
| Tâche | Prélude | Heures S1 | Heures S2 | Heures S3 | Heures S4 | Heures S5 | Heures S6 | Heures S7 | Heures S8 | Heures S9 | Heures S10 | Heures S11 | Heure S12 | Heure S13 | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Analyse du projet | 20 | ||||||||||||||
| Rédaction du wiki | 2 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | |||||||
| Documentation après prologue | 4 | 4 | 6 | 4 | 4 | 6 | 6 | 8 | 4 | ||||||
| Installation d'une VM avec Xen | 2 | ||||||||||||||
| Configuration de la VM | 2 | 2 | |||||||||||||
| Ajout d'un nœud Tor | 2 | ||||||||||||||
| Serveur Web sur la VM | 4 | ||||||||||||||
| Mise en place du service caché | 2 | ||||||||||||||
| Mise en place du réseau privé | 3 | 4 | 4 | 4 | 2 | 4 | 1.5 | ||||||||
| Programme de contrôle pour Tor | 2 | ||||||||||||||
| Service WEB pour connaitre son IP | 1.5 | ||||||||||||||
| Analyse des paquets sur le réseau privé | 2 | ||||||||||||||
| Script BASH choix pays de sortie | 4 | ||||||||||||||
| Total | 22 | 9 | 13 | 8 | 5 | 8 | 10 | 12 | 14 | 6 | 6 | 7 | 4 |
Prologue
Nous avons passé de nombreuses heures à nous documenter et à rassembler des documents sur le design de Tor.
Semaine 1
Suite à une conversation avec M. Redon, il nous a été conseillé d'utiliser le serveur Chassiron, dédié à la spécialité GIS mais non utilisé à cette période de l'année académique, afin d'héberger nos tests ainsi que notre futur réseau privé de test Tor sur des machines virtuelles. A l'aide d'un sujet de tutorat GIS nous avons débuté l'installation de notre première machine virtuelle à l'aide de Xen, cependant, notre curiosité et notre incompréhension à propos de Xen, de la virtualisation en général, ainsi que sur les bridges et vlan côté machine nous a emmené à nous documenter sur ce sujet passionnant et donc à un peu mettre de côté la partie applicative durant cette séance le temps de clarifier les choses. Une fois notre machine virtuelle crée, il s'en est suivi une étape de configuration au sein des fichiers de Xen afin de créer des interfaces réseaux virtuelles associées à un brigde de Chassiron. Enfin notre machine virtuelle était enfin connectée sur la ligne SDSL de l'école.
Semaine 2
- Configuration de la carte réseau virtuelle de la VM pour se connecter à la ligne SDSL
- Installation de quelques paquets : Lynx, TCPdump
- Installation d'Apache2
- Installation de Tor Browser sur tutur02
- Comparaison Tor / Web classique avec Wireshark
- Mise en place d'un service caché sur la VM
Semaine 3
- Problème : le serveur web de la VM est accessible de l'extérieur du réseau Lille 1 mais pas de l'intérieur (problème indépendant de notre volonté et résolu dans la semaine)
- Documentation en liens avec Tor et la sécurité. Nous avons trouvé beaucoup de publications sur : https://www.freehaven.net/anonbib/
- Mise en place d'un nœud public sur une VM.
Semaine 4
- Analyse des trames émises / reçues avec Wireshark
- Comparaison Tor Browser / Firefox classique en passant par Tor : Fuites DNS si l'on oublie de rediriger les requêtes DNS par le proxy SOCKS
- Lecture d'articles de recherche
Semaine 5
- Lecture de documentation sur la création de circuit
- Recyclage de 3 VMs sur Chassiron pour bâtir le réseau privée Tor. Deux seront des nœuds et la troisième sera à la fois un nœud, un serveur web et un directory server
- Passage des IPs en statiques : 172.26.145.31-32-33
- Installation de Tor sur les 3 VMs
- Mise en en place du directory server, du relay et serveur web apache2 sur grolem
- Configuration du relay sur grodoudou et goupix en spécifiant l'adresse du directory server (grolem)
- Le réseau est en place, manque plus qu'à configurer le torrc du client, une tutur par exemple
Semaine 6
- Le client est configuré
- Lecture du Tor Design
- Problème au niveau de l'implémentation du réseau privé (non résolu)
- Le client communique bien avec le processus Tor sur le SocksPort 9011 comme configuré
- Le client communique avec le Directory Server sur le port 7000 mais jamais avec un nœud sur le port 5000 (Wireshark)
- En revanche, le nœud Grolem effectue des connexions avec deux autres nœuds
- Pourquoi un tel manque de sens ?
Semaine 7
Nous rencontrons les mêmes problèmes que durant la semaine 6 à savoir que le client n'arrive toujours pas à établir un circuit. En revanche les nœuds du réseau entretiennent une connexion TCP entre eux ce qui selon nous est insensé si le réseau possède des milliers de nœuds. On a également remarqué que chaque nœud écoute sur un port UDP mais aucune documentation nous a éclairé sur l'utilité de ceci. Pour comparer avec un nœud public, nous avons relancé notre première VM (DurotDuq). Comme la capture d'écran le montre, nous remarquons que notre nœud est bel et bien utilisé par le réseau (écoute sur le port 9001 et connexion avec des IPs qui sont des nœuds). Nous faisons donc parti de quelques circuits mais nous n'avons pas de milliers de connexions établies. De plus, Tor n'écoute sur aucun port UDP. Nous essayerons de tirer au clair ces différences la semaine prochaine.
En parallèle nous continuons à nous documenter, notamment sur le rôle des deux paires de clés privés/public par nœud, sur le protocole TLS et les certificats numériques.
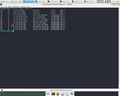
Sockets ouvertes (nœud public)
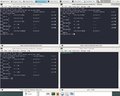
Sockets ouvertes (Réseau privé)


Semaine 8
Pour revenir sur le port UDP ouvert, nous avons eu un début de réponse sur le Stack Exchange de Tor qui nous disait de regarder au niveau des requêtes DNS. Il s'avère que notre nœud public (ne pouvant pas être utilisé en sortie d'un circuit) n'écoute pas sur un tel port. En revanche, nous n'avons pas imposé cette politique de sortie sur les VMs du réseau privé. On en déduit que par défaut les nœuds ouvrent un port UDP pour résoudre les domaines dans l'éventualité où ils seraient utilisés en sortie. Étrangement, et sans rien avoir changé, les nœuds n'établissent plus de connexion TCP entre eux. Ce résultat est rassurant et rentre en concordance avec les documents étudiés. Ce comportement semble néanmoins être celui du réseau il y a quelques années comme expliqué dans le Tor Design.
Le nombre de nœuds ayant explosé, le fonctionnement a dû être changé afin d'éviter des milliers de connexions TCP établies. Nous avons également fait des recherches sur le protocole TLS employé pour les échanges client-nœud et nœud-nœud. Nous avons par la suite cherché les raisons de son utilisation. Celle-ci est claire pour la partie "création de circuits" en revanche nous avons encore quelques interrogations sur son utilité quand il s'agit de transmettre des données par le circuit.
Notre réseau privé Tor a toujours un comportement étrange :
Les machines semblent se parler alors que nous ne demandons pas de création de circuit, et le routage des messages au travers Tor semble étrange.
Nous nous sommes rendus compte que les machines virtuelles ne font pas tourner la même version de Tor malgré une installation à la même période. Il s'agit d'une piste de réflexion à creuser pour la semaine prochaine.
Suite à une incompréhension du comportement de notre réseau privé, et après de la lecture sur Internet, nous nous résignons à utiliser Chutney pour la semaine prochaine, qui est vivement conseillé.
Cette semaine, encore plus de documentation a été réalisée sur Diffie-Hellman et TLS suite à une compréhension partielle antérieure.
Semaine 9
Au vu des problèmes que nous rencontrons sur notre réseau privé, nous avons commencé à nous intéresser à l'alternative Chutney qui semble être très appréciée des utilisateurs qui souhaitent tester des réseaux Tor privés. Des alternatives existent (ExperimenTor, Shadow), mais elles sont bien trop ambitieuses pour nous, ces dernières sont plus utiles pour simuler un réseau Tor à très large échelle, ce qui sort du cadre de notre utilisation car nous souhaitons uniquement déployer un réseau minimaliste.
Chutney est un outil en python développé par le Tor Project (en partie par Nick Mathewson, un ténor de l'équipe de Tor, présent depuis le début, co-auteur du "Tor design") qui permet la configuration, le lancement, et les tests sur un réseau Tor de test en local. Il fonctionne assez simplement en lançant plusieurs processus Tor liés sur le localhost à des ports différents, et en les faisant communiquer entre eux. (source de Chutney : https://gitweb.torproject.org/chutney.git/ )
Afin de tester Chutney dans un premier temps sans perturber notre réseau déjà en place (non fonctionnel, mais tout de même en place) nous avons récupéré la machine virtuelle "dracofeu" que nous avons connecté sur bridgeInfostud avec l'adresse IP 172.26.145.34. Pour parvenir à faire fonctionner Chutney il faut la dernière version de Tor(0.3.4.0), or cette version n'étant pas disponible sur les dépôts Debian de l'école, nous avons donc récupéré le code source de Tor sur la même source git officielle. La compilation, bien que relativement longue, n'a pas été très ardue du fait de la présence d'outil Makefile et de script shell automatisés et adaptés en fonction de notre architecture; bien que quelques bibliothèques en version -dev furent nécessaires afin d'assurer la bonne compilation du logiciel.
Chutney étant en état de marche, il nous permet très facilement d'avoir un réseau Tor fonctionnel suivant un certain patron qu'on impose via une api Python. On peut ainsi créer facilement un réseau de N nœuds, avec X clients, Y authority servers, Z services cachés. Chutney génère les torrc pour ces composants dans un répertoire. Nous avons ainsi pu avoir en peu de temps un réseau disponible selon notre demande et nous avons pu constater son bon fonctionnement via des analyses de paquets (capturées par tcpdump sur la machine virtuelle, puis analysés sur un ordinateur avec un serveur graphique permettant l'utilisation de Wireshark, oui, c'est de la faiblesse :)). Nous avons pu constater en particulier un trafic classique de Tor, en cellules fixes, et avec des requêtes HTTP en clair aux authority server.
Il est intéressant de noter que du point de vue de Wireshark (du fait que nos processus Tor utilisent les ports 500X en tant que Onion Router port pour communiquer), le transit de données Tor est assimilé à du Radio Link Protocol (RSL), ainsi, les données interprétés par Wireshark n'ont strictement aucun sens, ce qui amène à des situations où d'après Wireshark, nous envoyons des trames GSM sur une interface localhost, c'est assez puissant.
Même si Chutney nous permet de réaliser facilement un réseau fonctionnel, et avec une plus grande souplesse qu'avec des machines virtuelles, le fait que tout transite par le localhost rend cependant difficile l'interprétation des paquets, il faut garder en tête le port de destination, de source, savoir à qui appartient quel port source etc... Suite à cette pénibilité de lecture, nous avons décidé de reprendre le simple réseau constitué par Chutney (en exportant les torrc de chaque acteur du réseau), et de les copier/coller dans nos machines virtuelles. En soit, cela ne change pas beaucoup de ce que nous avions fait initialement, mais au moins, nous sommes sûr que les torrc générés sont fonctionnels, contrairement à notre ancien réseau tor privé qui avait des torrc que nous avions renseignés à la main, sachant qu'en plus, tous les nœuds n'avait précisément pas la même version de Tor, comme énoncé dans la semaine précédente.
Ainsi nous avons compilé et installé Tor sur la grolem, la grodoudou ainsi que la goupix, à l'instar de ce que nous avions fait sur la dracofeu, avant d'y mettre nos torrc.
Enfin, conjointement nous sommes en train de rédiger une partie du wiki sur le protocole TLS que nous pensons nécessaire pour la compréhension globale de Tor.
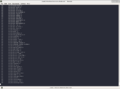
Compilation de Tor

Semaine 10
Nous avons commencé la séance en copiant les différents torrc générés par Chutney sur nos VMs. Nous aurons à présent la configuration suivante :
- Goupix : nœud + directory server
- Groudoudou : nœud de sortie
- Grolem : noeud + directory server
- Dracofeu : client
Les différentes IPs nous éviteront les confusions de lecture des paquets sur le localhost.
Aussi, nous avons évoqué le fait d'exploiter la socket de contrôle de Tor. L'idée serait de réaliser un programme en C permettant de configurer notre instance de Tor (suppression/création de circuits, modification du torrc à la volée, visualisation de statistiques/données ...).
La réalisation du programme a débuté. L'utilisateur lance l'utilitaire en spécifiant grâce à l'option --port ou -p le port de contrôle spécifié dans le torrc. Il lui est ensuite demandé d'entrer le mot de passe qu'il aura défini postérieurement en configurant Tor. Si le mot de passe est correct, une liste d'actions lui est proposée. Cette ébauche permet pour le moment de n'afficher que la liste des circuits et des streams. D'autres fonctionnalités seront rajoutées par la suite. L'avantage de ce programme est de faciliter l'usage de ce port de contrôle.
Une autre idée de programme a émergé dans nos têtes, avec nos 4 machines virtuelles afin de nous simplifier la vie, actuellement si nous devons faire des analyses de paquets, il faut lancer tcpdump, lancer Tor, puis stopper tcpdump ( et stopper Tor également ) et ce pour les 4 machines virtuelles. Enfin, il faudra faire un scp sur chaque machine virtuelle pour récupérer nos fichiers pcap de capture. Cette méthode étant très fastidieuse et répétitive, nous avons réalisé un script shell simpliste sur chaque VM qui lance tcpdump puis lance Tor, et un autre script shell qui stoppe tcpdump et Tor avant de faire un scp du fichier pcap sur Chassiron. L'idée maintenant, si on veut tout automatiser, est de faire en sorte qu'un simple script sur Chassiron exécute les deux scripts de chaque machine virtuelle afin qu'en définitive, on fasse la capture de paquet et la centralisation des fichiers de capture sur Chassiron dans un tout en un. Nous pensons que la meilleure manière pour communiquer entre deux machines virtuelles connectées sur le même réseaux est par socket, ainsi, nous aurons un programme côté machine virtuelle qui sera un serveur TCP lié à un port quelconque, qui attendra une commande de type "capture" en chaîne de caractère par exemple, et exécutera le script de capture, et même chose pour la commande "stop", qui stoppera les captures et enclenchera le processus scp.
Enfin, un gros travail sur le wiki reste à faire, et nous nous excusons de l'aspect un peu ... "brouillon" de celui-ci, nous avons des difficultés à mettre sous forme littéraire et cohérente tout ce que nous savons. Nos sources étant parfois contradictoires ou bien obsolètes. Un nombre important de questions restent sans réponses (et n'ont étonnamment, jamais été posées sur Internet), notamment au niveau de cette mystérieuse "Clef de connexion" qui rentre en conflit avec notre compréhension de TLS. De plus, le protocole de Tor prévoit une authentification du relai lors de la création de circuit par exemple, sauf que ce même protocole Tor fonctionne sur un lien TLS déjà établi. Nous n'avons toujours pas compris pourquoi un tel besoin de redondance dans l'authentification. Et nous pensons que certaines questions resteront sans réponses, sauf peut-être si nous posons ces questions directement aux ténors du Tor Project bien sûr. Il nous reste encore beaucoup de travail sur la compréhension fine et technique des spécifications de Tor, c'est autant formateur que ça en donne des maux de cranes.
Semaine 11
- Lancement de toutes les VMs
- Changement de la configuration du torrc de la tutur pour l'incorporer au réseau privé
- Configuration de Firefox avec le proxy SOCKS5
- Le réseau privé semble fonctionnel
- Analyse des résultats avec Wireshark (cohérent) - on peut également faire fuiter les DNS si la case sur Firefox n'est pas cochée
- On va maintenant créer un serveur web (en C) qui affichera l'IP de sortie (locale) qui consulte le service : une fois terminé, on remarque bien que l'IP affichée n'est pas celle de la tutur mais bien d'une VM
- Il reste à peaufiner le serveur WEB pour avoir un code tout de même présentable (fait rapidement en fin de séance)
- Parti d'une idée de M. Vantroys, nous allons créer un utilitaire permettant de choisir le pays du nœud de sortie
- Nous avons analysé les paquets transitant de la tutur au serveur WEB. On constate en effet que le nœud de sortie effectue la requête GET au serveur (d'ailleurs reconnu seulement comme étant du TCP sur Wireshark)
Semaine 12
En cette semaine 12, nous avons en plus des recherches habituelles, élaboré un script Bash permettant à un utilisateur naviguant sur Tor de choisir le pays du nœud de sortie. Au départ nous étions partis sur un programme écrit en C puis après réflexion il s'est avéré que le Bash était plus pratique. L'idée de départ nous est venue de M. Vantroys qui avait besoin d'un proxy en Belgique. Nous nous sommes rappelés qu'il était possible de forcer des noms de nœuds de sortie dans le torrc et que le consensus les affichait en plus de leur localisation. La première idée a donc été de parser ce fichier selon un critère géographique afin de dresser une liste de nœuds correspondants. Mais en fouillant les paramètres possibles du torrc, nous sommes tombés sur deux paramètres : ExitNodes et StrictExitNodes. ExitNodes permet en effet de renseigner des noms de nœuds mais chose que nous ne savions pas, il est possible de donner directement un ou plusieurs codes pays sous la forme {fr,us}. StrictExitNodes permet quant à lui de s'assurer que le nœuds de sortie fera partie de l'ensemble ExitNodes même si aucun nœud n'est disponible au risque de ne pas pouvoir naviguer sur le réseau.
Notre problème s'est donc simplifié. Il suffit maintenant de trouver une liste des codes pays et de changer le torrc en fonction du choix de l'utilisateur s'il est correct.
A défaut d'expliquer en détail le script, voici quelques captures d'écrans montrant l'efficacité et les fonctionnalités du script.
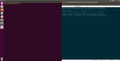
torrc initial
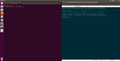
torrc complété par défaut
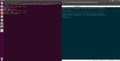
Ajout pays
Vérification sur Tor Browser
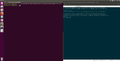
Désactivation
.png)
.png)
.png)
.png)
.png)
Semaine 13
Après une conversation avec M.Redon au sujet de l'accès des machines via un réseau externe (pour utiliser notre réseau Tor pendant les vaccances via une machine de notre domicile), nous mis les machines virtuelles sur la VLAN 110 (BridgeOpenInter), sur le réseau 193.48.57.160/27.
Nous avons donc mis :
- Goupix : 193.48.57.161
- Grodoudou : 193.48.57.162
- Grolem : 193.48.57.163
Ces machines étant routées, il est donc possible d’accéder à notre réseau privé depuis n'importe où, et ce même réseau peut sortir sur n'importe où. Il est très facile d'éditer le fichier torrc du client afin de le faire se connecter à Goupix et Grolem, nos Directory servers.
Nous avons eu cependant plusieurs problèmes qui ont nuit à la bonne communication entre nos machines virtuelles, d'une part, l'une des machines avait une utilisation de disque de 100 %, causée par 5 Go de logs qui se sont accumulés (ca fait beaucoup de texte depuis le début du projet), autre problème, une des machines avait une horloge décalée de 30 secondes par rapport aux autres, ce qui empêchait la récolte des consensus par Tor.
Ces problèmes réglés, notre réseau privé fonctionne à merveille.
Les ip routées en public nous ont causé plus tard cette semaine des attaques sur le port 22 d'ip Chinoises. Suite à ce danger d'attaque en force brute nous avons décidé de changer la politique d'authentification sur nos machines virtuelles. Ainsi, nous avons désactivé l'authentification par mot de passe et nous avons ajouté une authentification par clefs RSA 2048 bits générés par nos ordinateurs personnels. Le tout fonctionne parfaitement, et on a plus à se fatiguer à écrire le mot de passe.
- Dans le fichier /etc/ssh/sshd_config, on ajoute :
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
PasswordAuthentication no
- Dans le fichier /root/.ssh/authorized_keys on ajoute nos clefs (publiques, bien entendu):
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCxwBib0nTe/Un28WPQaLhwp7KidnRDdCN1/TDW5a/TkDnKfhpIIprzgFzTRSK5OQGltc+gBqEbCpeu1Cs3hBbzI+IiAFJk4CQdAt53058bAekKG63o8ksKuAYMcU4dcNhtCcQSuvtntLVtbLzyBmK3hWuOmXKwiu6qQaSidGvA25E5X2YbBHJhA3/L4oVwUEY0H2of/XzWtQ3hrRhFhSHWblXLsYNl4jwIf94zTcz5tlbC+J7wH4McjzxvCJsN/lCiStv1IdxU8k6YGAsS8CwhYiwDs6K+YLTSpjC0Pe4fEfcAQlmUWb3CGo6wrY/UxAO9FPMj3avRMY7LNCaLhvd/ anthony@anthony-Lenovo-Z710
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCdFdiiCwXHcTWv0zYCiw+7YP/N6W+JbegT0qPs0gR3kSbSm1dLgjEtabR6Yj6+3/nDmZyhVuQ8Nhs7geKt/gBHVEN1ghp1QH1IOxMp1eT2Zc42v5teyXeop8Ql7O05PL1JGG2s+6c3HQg0jtccSu47fTd3U8DkQHoRZzOJ4eaNGSs7ZrbhjPl78H9Sjf4PvVCq2OokE6TiE30DygvsN4PhspVIgTWGb2t17chFq2Ir0ZfT5VQ4phsJ17pdNY5OjFtVPfWyN2RwyBxlywBr+t+5KR6ySGZL1DRp3ka4gkbyu14H8NfTsayukFqH1nMXU15PXRa0gXTjfZCnXpuziGXH antoine@antoine-VirtualBox
De plus, du fait que ces derniers temps, la version de Tor tournant sur notre machine virtuelle DurotDuq (notre noeud public) est dépréciée car sujette à des failles de sécurités, nous avons entamé une compilation de la dernière version de Tor, flambant neuve.
État de l'art
Présentation générale
Rédaction en cours
Tor est à la fois un logiciel libre et un réseau de surcouche distribué en nœuds sur la base du volontariat. Il est sorti en 2001, et son design a été écrit par Roger Dingledine, Nick Mathewson de Freehaven ainsi que Paul Syverson de la Navy, il a pour but aujourd'hui de se défendre contre la surveillance et la censure qui menacent les libertés individuelles et l'intimité en anonymisant et en chiffrant les applications basées sur TCP comme la navigation sur le web, les connexions SSH, et les discutions instantanées. Bien qu'il soit rentré dans le domaine public, il faut tout de même dire que les origines de Tor remontent bien évidemment à des problématiques militaires.
Tor a été conçu à l'origine dans l'optique de respecter les considérations suivantes :
- Déployabilité : Tor doit être déployable et utilisé dans le monde réel. Ainsi, il ne doit pas être coûteux (par exemple en demandant plus de bande passante que les volontaires sont prêts à céder), ne doit pas être difficile d'implémentation (par exemple en nécessitant des mises à jour de noyaux, ou en nécessitant des proxy séparés pour chaque protocole), ne doit pas être un fardeau pour les volontaires, et enfin il ne faut pas que les partis non anonymes (comme les serveurs web) aient besoin d’exécuter Tor.
- Utilisabilité : Un système difficile à utiliser a tout logiquement moins d'utilisateurs, et parce que les systèmes d'anonymisation cachent les utilisateurs parmi les autres utilisateurs, un système avec moins d'utilisateurs est donc mathématiquement moins anonyme. Ainsi, l'utilisabilité n'est pas seulement un confort pour le client, elle est une réelle nécessité de sécurité. A ce titre, Tor ne doit pas nécessiter de modification d'applications, ne doit pas introduire de délais trop importants rendant impossible pour le client d'avoir une utilisation "confortable". Finalement, à l'instar de l'item Déployabilité, le client ne doit pas avoir à modifier son système d'exploitation. Tor doit être le plus multi-plateforme possible (il est actuellement disponible sur Linux, Solaris, BSD, MacOS X, Windows, Android et enfin iOS, on peut estimer que cet item est validé)
- Flexibilité : Le protocole de Tor doit être flexible et bien spécifié, de telle manière à ce que Tor puisse servir de base à de la recherche. L'idée est que les futurs systèmes d'anonymisation n'aient pas besoin de réinventer la roue (ie le Tor Design). Tor veut s'imposer comme un standard (et c'est tout de même assez le cas actuellement).
- Conception simple : Le protocole et les paramètres de sécurité doivent être bien compréhensibles. Des fonctionnalités supplémentaires imposent des coûts d'implémentation et de complexité. Ajouter des techniques non-prouvées au Tor Design menace la déployabilité, la lisibilité, et la "facilité" de l'analyse de sécurité. Tor a pour but de déployer un système simple et stable qui intègre les meilleures approches pour protéger l'anonymat.
Dans la logique de la portabilité, Tor repose sur l'utilisation de SOCKS, qui est un protocole standard qui permet de faciliter le routage de paquets entre les applications client/serveur via un serveur proxy. Dans le cas de Tor, il joue le rôle de proxy pour le client. Les applications souhaitant utiliser Tor n'ont qu'à être configurées pour utiliser ce serveur SOCKS proxy. Par exemple on peut "torrifier" très facilement du trafic HTTP sur un navigateur web.
Les nœuds au sein de Tor peuvent être de plusieurs types :
- Les Onion Router (OR, aussi appelés relais) : Ce sont les nœuds qui constituent les circuits utilisés au travers du réseau, ils sont le cœur fonctionnel de Tor, ce sont eux qui font transiter les paquets au travers du nuage Tor.
- Les Nœuds clients (aussi appelés onions proxies, OP, par abus de langage) : Ce sont les nœuds qui se connectent au réseau, ou plus précisément les clients logiciels Tor.
- Les Directory Servers (aussi appelés authority Servers) : Il s'agit des serveurs qui référencent les OR connus, ils sont les annuaires du réseau.
Par abus de langage, le terme "nœud" dans ce wiki sera à comprendre au sens de "relais", et sera utilisé pour éviter les redites. Pour les "nœuds" qui ne sont pas des "relais" on précisera explicitement clients (ou proxy Oignon) et serveurs d'annuaires. Cet abus de langage est assez commun dans la littérature de recherche sur Tor, c'est pourquoi nous nous permettons de nous l'approprier.
La communication au travers du réseau Tor fonctionne en routant les paquets au travers d'un circuit de relais entre le client et le serveur, en pratique, ce circuit a pour longueur trois relais, que l'on nomme Gardien - Nœud intermédiaire - Nœud de sortie. Chaque nœud partage avec le client une clef de chiffrement symétrique, et le message est donc enveloppé de trois couches de chiffrement, à la manière d'un oignon.
Ce circuit ainsi crée réduit drastiquement les risques d'analyses de trafic en disséminant les communications entre plusieurs endroits de l'Internet. On ne peut donc pas en observant un seul point, associer l'utilisateur à son destinataire. Métaphoriquement, cela revient à utiliser un chemin tortueux et difficile afin de "semer" et de mener en confusion un "poursuivant". Au lieu d'emprunter un itinéraire direct entre la source et la destination, les paquets suivent une trajectoire qui semble aléatoire à travers plusieurs relais, de plus, les données étant chiffrées, personne ne peut savoir qui parle et ce qu'il dit dans le nuage.
En pratique, lorsqu'un client désire communiquer avec un serveur externe au travers du nuage Tor, le client va construire un circuit entre lui et sa destination. Ainsi l'OP du client va consulter les Directory Servers afin de connaître la liste des OR, avec diverses informations à leur sujet, notamment leur adresse IP, leur vitesse de connexion etc...
Le client va choisir 3 relais qui constitueront le circuit. Il va inspecter la liste des nœuds pour choisir le nœud de sortie adéquat (en effet, ces derniers ont des politiques de sorties et n'acceptent que certains ports)

Ensuite, le client va construire un circuit entre lui et le serveur, chaque nœud apportant son chiffrement.

Une fois le circuit établi, il peut être utilisé pour anonymiser une application TCP, comme du trafic web, de la messagerie instantanée, des connexions SSH, etc... De plus, plusieurs streams TCP peuvent partager un même circuit.

On peut noter que la liaison nœud de sortie <=> Serveur n'est pas chiffrée par Tor, ce qui implique qu'elle n'a que le chiffrement propre au protocole utilisé, plus simplement, utiliser du HTTP sans TLS ne procure aucune confidentialité, avec ou sans Tor. De plus on remarque que si un attaquant observe la liaison Client <=> Gardien et la liaison nœud de sortie <=> serveur, il sera capable de tracer le client. Ce genre d'attaque est appelée "analyse de trafic" et est l'attaque la plus communément mentionnée dans la recherche.
Services cachés
Les services cachés permettent d'anonymiser le côté destiné d'une connexion TCP. Dans ce que nous avons vu jusqu'à maintenant, seule la source était cachée du destinataire. Les services cachés permettent de cacher la destination. Cependant il faut noter que s'il n'est possible de cacher que la source d'une connexion TCP avec Tor, il n'est pas possible de ne cacher que la destination. En effet, l'utilisation des services cachés impose également la dissimulation de la source, ainsi, il est obligatoire d'utiliser Tor pour accéder aux services cachés.
Les services cachés fonctionnent sur l'utilisation de "point de rendez-vous" : le client choisit un point de rendez-vous qui sera communiqué de manière indirecte au service caché, et les deux communiqueront via ce point de rendez-vous. Autrement dit, c'est comme si la communication entre Alice et Bob se faisait via une sorte de boite aux lettres, ni Alice ni Bob ne se connaissent, pourtant, ils peuvent communiquer. Seulement, il se pose le problème de savoir comment le client peut-il communiquer le point de rendez-vous au serveur, s'il ne connaît pas le serveur justement.
Un service caché doit donc afficher son existence dans le nuage Tor avant que des clients puissent le contacter. Pour ce faire, le service caché choisi des routeurs oignons, construit des circuits vers eux, et leur demande de se comporter comme étant des points d'introduction en leur fournissant sa clef publique. L'utilisation d'un circuit Tor rend difficile d'associer un serveur à ses points d'introduction. Et bien que les points d'introduction disposent de la clef publique identifiant le service caché, ils n'ont aucune idée de l'IP de ce même service.
Il est important de noter que dans les schémas suivants, les liens en vert sont à comprendre comme des circuits et non comme des connexions directes.

Le service caché construit ensuite un descripteur de service caché contenant sa clef publique et un résumé de chaque point d'introduction qu'il signe avec sa clef privée. Il stocke ce descripteur sur un ensemble de serveurs d'annuaire, encore une fois en utilisant un circuit Tor complet afin de cacher le lien entre le serveur d'annuaire qui stocke le descripteur et l'adresse IP du service caché. Le descripteur sera trouvé par les clients qui recherchent XYZ.onion où XYZ est un nom de 16 caractères de long qui peut seulement être dérivé de la clef publique du service grâce à un hash. Une fois cette étape achevée, le service caché est démarré.

Le client qui souhaitera alors contacter le service caché doit d'abord connaître son adresse onion. Après cela, le client peut lancer une tentative de connexion en téléchargeant le descripteur des serveurs d'annuaires. S'il y a un descripteur pour XYZ.onion, le client crée alors un circuit vers un autre nœud au hasard et lui demande d'agir comme un point de rendez-vous en lui communiquant un secret partagé.

Une fois que le descripteur est présent et que le point de rendez-vous est créé, le client génère un message de bienvenue (chiffré avec la clef publique du service caché, pour être sûr que lui seul puisse le lire) incluant l'adresse IP du point de rendez-vous et le secret partagé. Le client envoie ce message à l'un des points d'introduction en lui demandant de le délivrer au service caché. Encore une fois la communication a lieu dans un circuit de manière à ce que personne ne puisse faire le lien entre le message de bienvenue et l'adresse IP du client, assurant l'anonymat de celui-ci.

Le service caché déchiffre le message de bienvenue du client et y trouve l'adresse du point de rendez-vous ainsi que le secret partagé. Le service caché crée alors un circuit vers le point de rendez-vous et lui envoie le secret partagé dans un message rendez-vous.
A ce moment, il est primordial que le service caché conserve le même ensemble de nœuds gardiens pour créer de nouveaux circuits. Autrement, un attaquant pourrait utiliser son propre relais et forcer le service caché à créer un nombre arbitraire de circuit dans l'espoir que le relais corrompu puisse être désigné comme un nœud d'entrée et par conséquent récupérer l'adresse IP du serveur.

Dans la dernière étape, le point de rendez-vous indique au client que la connexion a bien été mise en place. Après cela, le client comme le service caché peuvent utiliser leurs circuits jusqu'au point de rendez-vous pour communiquer l'un avec l'autre. Le point de rendez-vous relaye simplement (chiffré d'un bout à l'autre) les messages du client vers le service et vice-versa.
Une des raisons de ne pas réutiliser la connexion créée auparavant via le point d'introduction pour une communication réelle est qu'aucun relais unique ne doit apparaître comme responsable d'un service caché donné. C'est pourquoi le point de rendez-vous ne connaît jamais rien sur l'identité du service caché.
En définitive la communication entre le client et le serveur se fait au travers de six relais, trois d'entre eux sont choisis par le client, avec le dernier comme point de rendez-vous, et les trois autres étant affectés par le service caché.

Au cœur de l'oignon
Les circuits en détail
Nous avons vu précédemment qu'un circuit était établi pour accéder à la destination voulue. Nous n'avions pas alors détaillé la construction et le fonctionnement de ce circuit. Avant d'aborder leur réalisation technique, précisions quelques points.
La construction d'un circuit est très coûteuse, ceci est dû aux mécanismes mis en place pour assurer la sécurité du circuit établi. Afin de limiter cet impact sur l'utilisation, et à la place de créer un circuit par flux de données, donc par application, plusieurs flux de données sont multiplexés sur un même circuit. Ce circuit est changé périodiquement, toutes les 10 minutes environ, afin de limite la fenêtre de temps qui permettrait à un attaquant identifier l'utilisateur.
Les circuits sont crées avant leur utilisation, afin de limiter une latence due à la construction du circuit lors de sa première utilisation. Ceci rentre dans la logique de réseau à faible latence dont nous avons déjà parlé.
Le proxy oignon (qui est le nœud "client", ou plus spécifiquement le client logiciel Tor qui tourne avec son interface SOCKS) construisent de nouveaux circuits périodiquement, nous l'avons vu. Les circuits ne sont supprimés que s'ils ont été utilisés. Lorsque Tor n'est pas utilisé, de nouveaux circuits ne sont pas établis. La construction de circuit se fait en parallèle de l'utilisation, afin d'assurer une meilleure qualité de service : lorsque la construction d'un nouveau circuit échoue, l'utilisateur continue d'utiliser le précédent.
De plus, les connexions présentées entre les noeuds ne sont pas de simples connexions, il s'agit de connexion TLS qui permettent :
- D'assurer le chiffrement des données, et donc leur confidentialité. Seuls les deux nœuds sont capable de lire les données échangées
- D'assurer l'intégrité des données échangées. Une modification des données échangées par un tiers n'est pas possible
- D'assurer l'authentification du prochain nœud dans le circuit. En effet les serveurs d'annuaire présentent le certificat TLS des relais, permettant d'assurer leur identité.
Il faut donc comprendre Tor comme reposant sur TLS, nous y reviendrons dans la partie de construction de circuit.
Cellules
Nous ne l'avons pas encore abordé, mais la communication au sein du réseau Tor se faire à l'aide de cellules de taille fixe 512 octets. Chaque circuit, au niveau d'un nœud est identifié par un CircID unique, précisé dans la cellule. Cette nécessité d'identifier le circuit a du sens si on suppose que plusieurs circuits peuvent être multiplexés sur une même connexion TLS. Cependant, le CircID n'est qu'un identifiant au niveau du nœud, ainsi en pratique, un circuit effectif aura en réalité 3 CircID, un par relais.

En fonction du champ CMD, on distingue deux types de cellules :
- Cellules de contrôle
- Cellules de données
Cellules de contrôle
Les cellules de contrôle sont interprétées par les nœuds qui les reçoivent. Leur champ CircID permet de définir sur quel circuit effectuer la commande, le champ CMD spécifie la commande, et le champ DATA est utilisé pour faire transiter les données inhérentes aux commandes concernées (dans le cas de CREATE, on y trouvera l'échange Diffie-Hellman dont nous parlerons plus en détail ci-après).
Les types de commandes possibles sont les suivants, en fonction du champ CMD, cette liste est exhaustive:
- 0 : PADDING : utilisée pour le keep-alive.
- 1 : CREATE : permet la construction d'un circuit avec le CircID correspondant. (TAP)
- 2 : CREATED : acquittement de la construction d'un circuit avec le CircID correspondant. (TAP)
- 3 : RELAY : identifie une cellule de relais, voir la section ci-après.
- 4 : DESTROY : détruit le circuit spécifié par CircID.
- 5 : CREATE_FAST : utilisée pour ne pas authentifier le nœud, en pratique utilisé pour les nœuds d'entrés, déjà authentifiés par TLS
- 6 : CREATED_FAST
- 7 : VERSION
- 8 : NETINFO
- 9 : RELAY_EARLY
- 10 : CREATE2 (ntor)
- 11 : CREATED2 (ntor)
- 12 : PADDING NEGOTIATE
- 128 : PADDING
- 129 : CERTS : demande le certificat RSA 1024 ou ED25519
- 130 : AUTH CHALLENGE
- 131 : AUTHENTICATE
- 131 : AUTHORIZE
La liste est voulue exhaustive, mais en réalité, pour comprendre Tor et faire son état de l'art, seules les premières sont utiles. Si il y en a autant, c'est pour plusieurs raisons, avec le temps, il y a eu un autre protocole d'authentification de Tor : ntor (comprendre "new Tor") pour remplacer l'ancien TAP (Tor Authentification Protocol). La différence réside dans l'utilisation de clefs ED25519 et non de RSA 1024 bits. Elle est donc purement technique, et importe au final assez peu pour parler du protocole en lui même. De même, une version 2 des cellules existent, mais les changements sont mineurs, ou pas encore utilisés à grande échelle.
Cellules de relai
Les cellules de relais contiennent des données effectives qui transitent sur le réseau lors d'une utilisation d'un circuit par un client pour naviguer sur le Web par exemple. Dans le cas échéant, le champ DATA comprendra la requête HTTP dans son stream TCP. Ces cellules sont donc ainsi simplement transmises au relais suivant. Au même titre que les cellules de contrôle, les cellules de relais contiennent leur champ. Le champ StreamID défini quel flux est concerné par la cellule, le champ Digest permet d'effectuer du contrôle d'intégrité à base de fonction de hachage, le champ LEN précise la taille des données contenues dans le champ DATA, et enfin le champ CMD indique une commande à exécuter.
Les types de commandes possibles sont les suivants :
- 1 : RELAY BEGIN : utilisée pour créer un flux
- 2 : RELAY DATA : utilisée afin de suivre des données
- 3 : RELAY END : utilisée pour fermer un flux
- 4 : RELAY CONNECTED : utilisée pour acquitter de la création d'un flux
- 5 : RELAY SENDME : utilisée pour le contrôle de congestion
- 6 : RELAY EXTEND : utilisée pour étendre le circuit d'un saut (TAP)
- 7 : RELAY EXTENDED : utilisée pour acquitter de l'extension (TAP)
- 8 : RELAY TRUNCATE : utilisée pour tronquer un circuit à un certain relais et le changer
- 9 : RELAY TRUNCATED : atteste de la troncature
- 10 : RELAY DROP : utilisée pour clore un flux
- 11 : RELAY RESOLVE : utlisée pour demander une résolution de nom
- 12 : RELAY RESOLVED : utilisée pour répondre à la résolution de nom
- 13 : RELAY BEGIN DIR : utilisée pour télécharger le consensus via Tor
- 14 : RELAY EXTEND2 (ntor)
- 15 : RELAY EXTENDED2 (ntor)
Relais
Les relais sont, comme nous l'avons vu précédemment, l'élément essentiel de Tor. En pratique, un relais se présente sous la forme d'un programme qui ouvre un port pour la communication et le fonctionnement de Tor. Ce port se nomme "ORPort", il est renseigné dans le fichier de configuration torrc du client Tor qui tourne sur le relais.
Pour assurer la sécurité et l'authentification des Relais, ces derniers possèdent tout un ensemble de clefs :
- En RSA 1024 bits :
- "Clef d'identité" : Une clef de signature à longue durée de vie utilisée pour signer les documents et les certificats, elle établit l'identité du relais.
- "Clef oignon" : Une clef qui permet de déchiffrer les commandes, telles que les commandes de création de circuit. Sa durée de vie est moyenne.
- "Clef de connexion" : Utilisée pour négocier les connexions TLS. En pratique, cette clef doit être changée une fois par jour d'après la tor-spec.
- En Ed25519 (EdDSA sur la courbe elliptique 25519) :
- "Clef d'identité maître" : Cette clef ne change jamais, elle n'est utilisée que pour signer les "clefs de signatures" ci-après.
- "Clef de signature" : Cette clef est signée par la clef d'identité maître. Une nouvelle doit être générée périodiquement.
- "Clef d'authentification" : Cette clef est signée par la clef de signature, et elle est utilisée pour authentifier la poignée de main. Elle doit être régénérée fréquemment.
Ouverture de flux coté client
On parle de flux lorsqu'une application a besoin d'une connexion TCP. L'application de l'utilisateur, lorsqu'elle a besoin de se connecter à un serveur externe, demande au proxy oignon de lui fournir une connexion : Cette demande se fait en utilisant le protocole SOCKS.
Le proxy oignon choisit le dernier circuit créé (ou en créé un, mais à priori, il y a toujours un circuit disponible). Il envoie alors une cellule de relais de type BEGIN avec un nouvel identifiant de flux aléatoire. Le nœud de sortie répond par une cellule de relais de type CONNECTED après avoir initialisée la connexion TCP avec le serveur externe.
Enfin, le proxy oignon notifie l'application, via SOCKS de la création du flux, celui-ci est alors capable de relayer les données vers le serveur en utilisant des cellules de relais de type DATA.
Établissement d'un circuit

Le proxy oignon du client va tout d'abord devoir négocier des clefs symétriques avec les trois nœuds du circuit qu'il souhaite créer. Pour se faire, les clefs vont être négociées les unes après les autres.
Dans un premier temps, Alice va créer un circuit qui se terminera à OR 1. Elle va commencer par envoyer une cellule de contrôle CREATE demandant le création d'un circuit entre Alice et OR 1 avec un identifiant c1. Cette cellule contient dans son champ DATA la première partie de la négociation Diffie-Hellman, c'est à dire g^x1. Cette donnée sera chiffrée grâce à la clef publique de OR1.
OR 1 répond alors par une cellule CREATED qui contient la deuxième partie de la négociation : g^y1, ainsi qu'un hash de la clef symétrique calculée. A ce moment, Alice et OR 1 partagent la même clef symétrique.
Deux choses peuvent être remarquées :
- Alice envoie sa première partie de la négociation chiffrée. Ceci permet d'assurer deux choses. La première est une authentification unilatérale. Dans l'exemple, Alice sait qu'elle a eu affaire à OR 1 car elle a utilisé sa clef publique (Onion key) pour chiffrer les données que lui seul peut déchiffrer grâce à sa clef privée (de plus, le tout est établi sous couvert d'un lien TLS qui assure également l'identité de OR 1 à Alice dans le cas présent). Ce recours au chiffrement asymétrique permet également d’empêcher une attaque de type Man-In-The-Middle auquel la négociation de clef Diffie-Hellman est vulnérable.
- OR 1 envoie un condensat de la clef symétrique qu'il a calculé. Ceci prouve que c'est bien lui qui a reçu la première partie de la négociation (g^x1), mais aussi que c'est bien lui qui a choisi y1.
A l'issue de cette première étape, et suite à cet échange de cellules de contrôle CREATE/CREATED, un circuit a été créé. Ce circuit a alors pour origine Alice et pour fin OR 1. Chacun de ces deux nœuds est alors capable d'identifier ce circuit, grâce à c1 qui est unique dans la connexion Alice/OR 1. Ils sont également les seuls à connaître la clef de session qu'ils ont établi lors de la négociation Diffie-Hellman.
Le premier tronçon du circuit ayant été construit. Alice demande à OR 1 d'étendre le circuit d'un saut. Pour cela, elle utilise une cellule de type relais, qu'elle indique comme étant destinée au circuit c1. Les données contenues dans le champ DATA sont chiffrées avec la clef de session K1, entre Alice et OR 1. Ces données contiennent :
- Le type de la commande à exécuter, ici EXTEND, qui indique à OR 1 qu'il devra étendre le circuit.
- Le nœud vers lequel le circuit doit être étendu, ici OR 2.
- La première partie de la négociation Diffie-Hellman entre Alice et OR 2, chiffrée avec l'Onion Key de OR 2.
OR1, à réception de cette cellule de relais, ne sait pas directement que la commande lui est destinée. Il va d'abord déchiffrer les données avec sa clef de session AES, puis vérifier le champ Digest et sa cohérence par rapport aux données transportées. Ici, il va constater que la valeur de Digest correspond bien à la somme de contrôle des données et traiter la commande EXTEND.
Pour se faire, il va créer le tronçon entre lui et OR 2 de la même façon qu'Alice avait créé le tronçon entre elle et lui. Il va utiliser une cellule de contrôle de type CREATE en fournissant un identifiant c2 qu'il sait unique entre lui et OR2 (remarque : c2 n'a pas besoin d'être connu d'Alice, et rien n'empêche que c2 soit égal à c1), et fournir la première partie de la négociation Diffie-Hellman fournie par Alice dans la cellule de relais qu'il a reçue, soit g^x2 chiffré avec l'Onion Key de OR2. Cette cellule est suivie d'une réponse sous la forme d'une cellule de contrôle CREATED, indiquant la deuxième partie de la négociation Diffie-Hellman que seule Alice pourra exploiter puisque la première partie n'est connue que d'elle et OR 2.
Une remarque importante se doit d'être faite, un lien TLS existe entre OR 1 et OR 2 permettant d'identifier OR 2 avec sûreté pour OR 1, mais ce lien n'existe pas entre OR 2 et Alice. Ainsi, si Alice ne chiffre pas avec l'Onion Key sa partie du Diffie-Hellman, rien n’empêche à OR 1 de rediriger Alice vers un nœud malveillant.
Afin de communiquer à Alice la réponse d'OR 2, OR 1 utilise une cellule de relai dont les données chiffrées correspondent à une commande de type EXTENDED, acquittant de l’extension du circuit, et faisant suivre les informations fournies par OR 2 concernant la fin de la négociation Diffie-Hellman.
Pour le troisième nœud, on agit exactement de la même façon, mais on va l'oublier dans le schéma, car le considérer n'apporte aucun intérêt pour comprendre le protocole de Tor.
Alice souhaite maintenant établir un flux afin de pourvoir accéder à son site Web par exemple de destination. Elle veut donc communiquer à OR 2 (dans la pratique, à OR 3) l'ouverture de ce flux. Afin de garantir la confidentialité de ce qu'elle transite, elle va chiffrer itérativement les données de la cellule de relais qu'elle va envoyer à OR2, d'abord avec la clef de session qu'elle partage avec OR 2, puis avec celle qu'elle partage avec OR 1. Les données de la cellule de relais, en parcourant le circuit, seront successivement déchiffrées par les nœuds rencontrés, soit, dans l'ordre, OR 1, puis OR 2.
C'est de cette succession de déchiffrement que vient l'analogie à l'oignon, dont Tor tient son nom.
Ainsi lorsque la source d'un circuit va vouloir envoyer des données à l'autre bout du circuit, on obtiendra, de façon imagée, ceci :

Il s'agit bien évidemment d'une image : les couches ne sont pas ajoutées, ce sont des chiffrements successifs.
La cellule de relais envoyée par Alice contient des données indiquant qu'il s'agit d'une commande BEGIN, et que le serveur externe à contacter est situé à l'adresse <website> (qui pourrait être rex.plil.fr pour n'en citer qu'un), sur le port 80. Lorsque OR 2 reçoit cette cellule, il constate que sa commande lui est destinée (la somme de contrôle étant vérifiée), et initie une connexion TCP vers <website> sur le port indiqué. Une fois cette initialisation terminée, il répond à Alice par une commande CONNECTED au sein d'une cellule de relais. L'acheminement de cette cellule étant vers la source du circuit, les données sont chiffrées par chaque nœud au lieu d'être déchiffrés. Alice, à la réception de la cellule, déchiffre alors itérativement les données pour prendre connaissance de la réussite de l'ouverture de la connexion TCP.
La connexion TCP étant initialisée, Alice veut accéder à des données sur le serveur externe. Elle va donc envoyer une cellule de relais avec pour commande DATA, et les données TCP à faire parvenir au serveur externe Le cheminement de cette cellule de relais est le même que celui de la cellule de relais envoyée par Alice pour initialiser la connexion : Alice commence par chiffrer itérativement les données, et à chaque nœud traversé, un déchiffrement est opéré.
La cellule ayant atteint OR 2, celui-ci fait parvenir les données au serveur externe et achemine progressivement la réponse fournie par le serveur en utilisant lui aussi une cellule de relais de type DATA contenant cette réponse.
Les serveurs annuaires (Directory Servers)
Les directory serveurs sont les nœuds spécifiques qui ont le rôle d'annuaire au sein du réseau. Ils sont redondants, et présentent les mêmes informations. Leur fonction est de référencer les OR connus, en présentant leur descripteur de routeur. Ces descripteurs regroupent des informations telles que ses clefs publiques, sa politique de sortie, son adresse IP, sa bande passante, la version de Tor utilisée, etc...
Les proxy oignon doivent vérifier la cohérence des données présentées, en validant la similitude des données présentées sur d'autres annuaires. Ces annuaires sont disponibles en HTTP, et sont utilisés pour amorcer Tor. L’amorçage (ou bootstrapping) est une nécessité dans ce genre de réseau : il permet aux clients d'initialiser leur vue du réseau, et les noeuds qu'ils connaissent.
Par exemple, ce lien permet de télécharger le consensus de notre réseau Tor privé : http://193.48.57.163:7000/tor/status-vote/current/consensus.
Dans ce consensus, on trouve la liste des routeurs oignons, en particulier on trouve grodoudou, notre nœud de sortie au sein de notre réseau privé. On y retrouve ici son descripteur de routeur :
r grodoudou XGT8eVzVGcHRbQuyUQeZhmbQoIM pnHEEAUmmrhMTz+1E1fZ2XFyM1Q 2018-05-13 06:19:23 193.48.57.162 5000 7000
s Exit Fast Guard HSDir Running Stable V2Dir Valid
v Tor 0.3.4.0-alpha-dev
pr Cons=1-2 Desc=1-2 DirCache=1-2 HSDir=1-2 HSIntro=3-4 HSRend=1-2 Link=1-5 LinkAuth=1,3 Microdesc=1-2 Relay=1-2
w Bandwidth=6490 Unmeasured=1
p accept 1-65535
En pratique, le client ne télécharge pas tous le consensus à chaque fois. En réalité à chaque routeur oignon est associé un condensat. Ce condensat est indexé dans les serveurs d'annuaires par un identifiant de routeur. Ainsi, si les condensats sont différents, le client ira télécharger le nouveau descripteur de routeur grâce à son identifiant. En définitive, le client ne télécharge que les routeurs qu'il n'a pas, et non ceux de tout le consensus.
Cela implique donc que le consensus soit gardé en cache chez le client, en pratique dans /var/lib/tor/cached-microdesc.
Pour les adresses IP des serveurs d'annuaires, elles sont codées en dur dans le client Tor, ou bien elles peuvent être mises manuellement dans le fichier de configuration de Tor, le .torrc, situé dans /etc/tor/.torrc.
Politiques de sortie
Afin d'améliorer le confort d'utilisation des personnes souhaitant mettre en place des relais Tor, des politiques de sortie ont été mises en place. L'idée étant de permettre de restreindre les opérations possibles à partir de ce nœud que représente le serveur.
Des types de routeurs oignon ont été définis :
- Open exit nodes : Ces nœuds permettent de sortir vers des serveurs externes.
- Middleman nodes : Ces nœuds ne peuvent être utilisés que pour construire des circuits, ils ne peuvent pas être utilisés comme point de sortie.
- Private exit nodes : ces nœuds ne permettent l'accès qu'à des réseaux locaux.
D'autres paramètres de configuration sont également possibles, comme la restriction de services. Par défaut, le port SMTP (25) est bloqué pour éviter l'utilisation du réseau pour des pratiques de spam de mail.
Contrôles réseaux
Certains contrôles sont souvent souhaitable au sein d'un réseau. Parmi ces contrôles on peut citer les contrôles d'intégrité, les contrôles de congestion ou encore les contrôles de débit. Nous avons déjà évoqué le cas des contrôles d'intégrités assurés à laide de TLS et de TAP (ou ntor), à l'aide notamment du champ Digest qui contient une somme de contrôle, assurant l'intégrité des cellules. Ainsi lorsque la somme de contrôle calculée par chaque nœud n'est jamais égale à la valeur de champ, le dernier nœud a la responsabilité de jeter ce paquet et de fermer le circuit.
Contrôle du débit
Nous avons parlé de la présence d'une valeur de bande passante dans les descripteurs de routeurs associés aux nœuds. Il est en effet possible de spécifier une bande passante maximale à utiliser, pour minimiser la charge du serveur. Cela permet en partie d'assurer que le volontaire qui héberge le nœud ne donne pas plus que ce qu'il souhaite donner. Ce qui cultive la confiance envers Tor pour les hébergeurs.
Cette limitation se fait en utilisant un token bucket. Cette technique consiste à modéliser la bande passante disponible sous forme de sceau, où régulièrement sont versés des jetons, qui peuvent s'accumuler jusqu'à une certaine limite, et d'où les jetons sont tirés à chaque donnée transitée. Le débit moyen s'en trouve limité, tout en permettant des pointes de débit temporaires pour répondre à des instants bien spécifiques.
[Inserer screenshot]
Ce contrôle permet de fournir un service préférentiel aux services interactifs qui n'ont pas besoin de beaucoup de débit mais d'une latence faible.
Contrôle de congestion
La congestion est une situation d'utilisation du réseau défavorable où trop d'activités sur les connexions amènent à leur détérioration en termes de qualité de service. Elle peut arriver par exemple lorsque trop d'utilisateurs utilisent un même nœud, rendant sa bande passante insuffisante et faisant apparaître un goulot d'étranglement. Tor utilisant le protocole TCP, le séquencement et le renvoi sont délégués à celui-ci. Une partie du problème est alors gérée par TCP.
L'autre partie du problème est gérée au sein du réseau Tor d'une manière similaire à TCP en utilisant des fenêtres. En effet, un problème se présente dans la mesure où la bande passante doit être régulée au niveau global, au niveau du circuit. TCP ne peut donc pas être utilisé directement pour cela. Cet aspect de la congestion n'est appliqué que pour les cellules de relais de type DATA : ce sont elles qui génèrent le plus de trafic.
Deux niveaux de congestion sont identifiés : au niveau des circuits, et au niveau des flux. Dans les deux cas, on utilise des fenêtres à la manière de TCP. Expliqué simplement, ce processus se résume à suivre le nombre de cellules que l'on est prêt à envoyer. On distingue donc deux fenêtres :
- La packaging window qui représente la quantité de cellules que le nœud est prêt à relayer vers le proxy oignon depuis un flux TCP
- La delivery window qui représente la quantité de cellules relayable vers un flux TCP
Lorsqu'une cellule est envoyée, la fenêtre correspondante est décrémentée. Lorsque la fenêtre est vide, plus aucune cellule n'est envoyée. Lorsque suffisamment de cellules ont été reçues, une cellule de relais de type SENDME est envoyée. A la réception de cette cellule, la fenêtre est augmentée d'un nombre arbitraire. Lorsque la fenêtre concernée est celle des circuits, un identifiant de flux de 0 est utilisé. Lorsque la fenêtre concernée est celle des flux, le nœud attend le flush sur le flux TCP avant de comptabiliser la cellule comme reçue.
Attaques et défenses
Maintenant, parlons des attaques possibles sur Tor et comment les contrer. Ces attaques se distinguent en quatre sous parties, les attaques actives et les attaques passives. Les attaques actives impliquent que l'attaquant, que l'on appellera Eve peut intervenir sur quelque chose, tandis qu'une attaque passive n'implique que de l'observation et de l'analyse. Enfin, on distingue également les attaques d'annuaires, et les attaques de services cachés.
Attaques passives
- Observer le contenu de l'utilisateur : Même si le contenu utilisateur est chiffré, le contenu qui sort du nuage Tor ne l'est pas (en effet, un site web peut être malveillant). Même si le filtrage du contenu n'est pas un objectif principal de Tor, Tor utilise Privoxy pour anonymiser les flux de données applicatif. Privoxy permet également de d'assurer qu'il n'y ait pas de "fuites DNS", cela se produit lorsque la résolution de nom ne passe pas par Tor, et donc peut mettre à mal l'anonymat d'Alice.
- L'usage d'options : Tor permet aux clients de choisir des options de configuration via le torrc. Par exemple, les clients se sentant concernés par les attaques de localisation peuvent choisir de changer de circuit plus régulièrement que les autres. Cette possibilité de configurer Tor est attractive pour des utilisateurs ayant des besoins divers, mais certains clients minoritaires peuvent perdre de l'anonymat car ils seront plus distinguables que les autres.
- Corrélation de bout-en-bout temporelle : Il s'agit de la bête noire de Tor. Un attaquant qui peut observer des patterns de trafic entre Alice et OR 1 et entre OR 3 et le serveur peut, à l'aide d'outils mathématiques établir une corrélation avec une forte probabilité, violant ainsi l'anonymat d'Alice. Au final, la seule défense absolue de cela est de cacher la connexion entre le client et le premier nœud. Il est donc fortement conseillé aux utilisateurs souhaitant un anonymat pratiquement absolu d’héberger leur propre nœud Tor sur leur machine, et de l'utiliser comme nœud d'entrée.
- Empreintes web : Il s'agit de quelque chose de très commun aujourd'hui, et un sujet de recherche très actif. Un site web peut garder une base de données d'empreintes web (nommé "website fingerprinting" dans la littérature) qui constituent un ensemble de données envoyées par le navigateur web, souvent à l'insu de l'utilisateur. Par exemple, avec les entêtes HTTP (essentiellement le user-agent), et divers informations recueillies à l'aide de Javascript, un utilisateur peut être aisément tracké, et ce, sans même l'utilisation de cookies que l'utilisateur pourrait supprimer. En pratique, pour répondre à ces attaques, très présentes, le "Tor browser" tend à avoir une empreinte unique à l'aide de divers plugin limitant l'action de "sniffers Javascript". In fine, deux utilisateurs du "Tor browser" seront pratiquement indiscernables, là où deux utilisateurs de Firefox, même sous le même système d'exploitation, avec la même version de Firefox, peuvent être trackés suivant les informations différentes renvoyées par le moteur Javascript.
Attaques actives
- Compromission de clefs : Un attaquant qui apprend la clef TLS de liaison peut lire les cellules de contrôle et les cellules de relais pour chaque circuit au sein de cette connexion. S'il apprend en plus la clef de session d'un circuit, cela lui permet de retirer une couche de chiffrement. Un attaquant qui apprend la clef TLS privée d'un nœud peut usurper l'identité de celui-ci pour la durée de vie de la clef TLS, mais il doit également connaître la clef Oignon de ce nœud afin de déchiffrer les cellules CREATE. En pratique, cette attaque est détournée en effectuant une rotation des clefs assez régulièrement. De plus, un attaquant qui apprend la clef d'identité du nœud peut indéfiniment usurper l'identité du nœud en modifiant son descripteur de routeur aux serveurs d'annuaire, et ainsi héberger un nœud malveillant en lieu et place d'un autre, sans que personne ne le sache.
- Compromission de proxy oignon : En pratique, le proxy oignon est hébergé en local sur la machine client qui utilise Tor, mais il peut arriver que ce proxy soit hébergé sur un serveur distant (dans un réseau limitant les droits individuels des utilisateurs sur leur machines par exemple), dans ce cas, un danger de compromission du proxy oignon existe, ce qui permet de mettre au clair tous les streams ouverts par le client, et donc de briser son anonymat.
- Déni de service sur les nœuds : Tor étant un service souhaitant être le plus rapide possible afin d’être "séduisant" pour les utilisateurs, il tend à utiliser les nœuds les plus rapides afin de créer un circuit. Ainsi, si on suppose un hébergeur malveillant de plusieurs nœuds, il est possible qu'il puisse perpétrer des attaques de type déni de service sur les autres nœuds afin d'assurer qu'il soit l’hébergeur de la majorité des nœuds utilisés. Ainsi, si les trois nœuds d'Alice appartiennent à Eve (l'attaquante), Eve sera capable de détruire l'anonymat d'Alice. De plus, il est possible de faire un déni de service "CPU", on peut par exemple inonder un routeur oignon en démarrant beaucoup de connexions TLS, ce qui coûte très cher en ressources CPU pour calculer la moitié du Diffie-Hellman correspondante. Ce problème est réglé en obligeant les clients à résoudre une sorte de puzzle, difficile à résoudre, mais simple à vérifier, afin de limiter la quantité de connexions TLS possibles dans le temps.
- Remplacement de contenu de protocoles non authentifiés : Lorsqu'un nœud de sortie relaie du trafic HTTP, il peut par exemple usurper l'identité du serveur web afin de forger une réponse malicieuse au client. En pratique, on bannira tout trafic non authentifié sur Tor.
- Attaques de réputation : Un utilisateur peut utiliser le nuage Tor afin de perpétrer des opérations illégales causant des saisies judiciaires de certains nœuds de sortie et affaiblissant Tor. En pratique, la politique de sortie des nœuds peut limiter cela, mais il s'agit quand même d'un problème insoluble, les hébergeurs de nœuds de sortie doivent s'attendre à avoir des soucis politiques et judiciaires car ils sont officiellement responsable de ce que leur adresse IP fait transiter.
- Distribution de code malicieux : Un attaquant peut piéger les utilisateurs en fournissant une version malveillante du code source de Tor, qui n'anonymise pas leur trafic par exemple, ou encore pire, piéger des nœuds pour faire tourner une version alternative faible de Tor tout en étant indétectable. En pratique, ce problème est réglé par le Tor Project qui distribue le code source sous licence GPL, donc libre, qui encourage fortement les audits de code, et fournit un condensat du code source ainsi qu'une clef gpg pour prouver l'authenticité et l'intégrité du code. Tor Project encourage de ne pas faire confiance aux logiciels Tor fournis sans code source et encourage la compilation personnelle et non l'installation par paquets.
Attaques d'annuaires
- Neutraliser les serveurs d'annuaires : Si quelques serveurs d'annuaires disparaissent, les autres vont toujours décider d'un consensus. Mais si la moitié des serveurs d'annuaires sont neutralisés, le consensus n'aura pas la majorité du vote et ne sera donc jamais publié ni considéré comme de confiance par les clients. Par conséquent, cela bloquerait l'intégralité du nuage Tor.
- Usurper une majorité de serveur d'annuaires : Si un attaquant usurpe les identités d'une majorité de serveurs d'annuaires, il peut influencer le consensus final en donnant une vue du nuage malicieuse en incluant autant de nœuds malicieux qu'il le souhaite. En pratique, cette attaque est très peu probable, le Tor Project s'assure que les serveurs d'annuaires soient tous hébergés dans des pays différents, par des entreprises indépendantes. Ainsi, à priori, aucun gouvernement ni conglomérat d'entreprises ne pourrait contrôler une majorité des serveurs d'annuaires.
Attaques de services cachés
- Déni de service : Un attaquant peut réaliser une attaque de type déni de service en faisant des requêtes sur les points d'introduction du service caché hébergé par Bob. En pratique, Bob peut restreindre la quantité de calcul pour les requêtes reçues par ses points d'introduction. De plus, un service caché est attaché à sa clef d'identité et non à ses points d'introductions. Le service peut ainsi se ré-identifier avec des points d'introductions différents et donc contrer cette attaque.
- Compromission du point de rendez-vous : Du fait que le point de rendez-vous n'est autre qu'un nœud classique, il est sujet à toutes les attaques de nœuds. Ainsi, ce nœud peut être malicieux bien que les données échangées soient complètement chiffrées de bout-en-bout.
- Compromission d'un point d'introduction : Un attaquant qui contrôle un point d'introduction peut inonder Bob de requêtes d'introduction (provoquant un déni de service de Bob) ou bien même empêcher les requêtes d'introduction des clients de parvenir à Bob.
- Être le premier nœud : Supposons un attaquant faisant une requête sur le service caché de Bob. Si ce même attaquant contrôle assez de nœuds de manière à ce que le point de rendez-vous choisi soit contrôlé par lui-même et qu'au moins un des nœuds composant le circuit entre le service caché et le point de rendez-vous soit à lui, alors avec des outils de corrélation de timing il peut déterminer qu'un paquet de réponse du service caché arrivant à son point de rendez-vous soit passé par un de ses nœuds. Ainsi, il sait déterminer si un de ses nœuds fait partie du circuit Bob <=> Rendez-vous et donc il aura l'adresse IP du nœud avant lui et après lui. A partir de là, il suffit de faire assez de requêtes, récupérer les cas où le nœud fait partie du circuit Bob <=> rendez-vous, et en toute logique, deux IP devraient émerger plus souvent que les autres : l'IP du point de rendez-vous ou l'IP du service caché. Ainsi, il est potentiellement possible de briser l'anonymat d'un service caché. En pratique, cette méthode fonctionnait de manière très effective aux débuts de Tor, lorsque qu'il y avait peu de nœuds et qu'il était facile de contrôler une majorité de nœuds. Aujourd'hui, avec 6000 nœuds, c'est globalement beaucoup moins probable. De plus, suite à la menace de cette attaque, Tor a inclus le concept de "Entry guard" : le choix du premier nœud est plus restrictif que les autres et ce nœud sera plus rarement changé que les autres. Ainsi, faire N requêtes à un service caché n'assure pas la création de N circuits passant à priori par N différents nœuds d'entrés limitant drastiquement cette attaque.
Bonus : Comment la Chine bloque Tor ?
La censure en chine n'est pas limitée qu'au Web. En effet "The Great Firewall of China" (GFC) empêche les utilisateurs de Tor d’accéder à son réseau. Tout commence le 4 Octobre 2011 lorsqu'un utilisateur publie sur le "Tor bug tracker" que les bridges ont soudainement cessé de fonctionner. Pour rappel, les bridges sont les nœuds "privés" de Tor, il s'agit des nœuds qui ne sont pas référencés dans le consensus. Ces nœuds sont obtenables via une demande spécifique au Tor Project qui est très entrain à en fournir aux victimes de la censure. Il est donc étrange que ces bridges soient bloqués, empêchant tout accès à Tor depuis la Chine qui avait une liste noire de tous les nœuds publics, bien entendu.
En réalité, il se trouve que les ports utilisés par les nœuds Tor ne sont pas toujours des ports recensés pour des activités "acceptables" bien qu'il soit tout à fait possible (et vivement conseillé) d’héberger un nœud Tor fonctionnant sur le port 443, cachant Tor sous couvert d'un trafic HTTPS. D'autre part, il se trouve que le TLS Client.hello, qui initialise le lien TLS, est unique à Tor.
Les autorités Chinoises ont donc juste à interdire les connexions TLS sur un port autre que 443, et pour ces connexions, tenter de faire une connexion TLS suivant le modèle de Tor et commencer à créer un circuit. Si le serveur renvoie une cellule de type CREATED, GFC déduit en toute logique que c'est un nœud Tor et donc banni l'adresse IP.
Ceci montre à quel point malgré tous les efforts mis en place, Tor ne peut pas fonctionner dans une logique d'adversaire aussi global et puissant qu'un gouvernement qui contrôle tout.
Un peu de statistiques
Parce qu'un peu de graphes n'ont jamais fait de mal à personne, et même si cette partie statistique ne rentre pas dans notre travail sur l'état de l'art technique, nous pensons qu'il est important de s'y intéresser.
Lorsqu'on s’intéresse aux données publiées gratuitement et en accès libre par le Tor Projet, on se rend compte à quel point Tor est un logiciel populaire, malgré la mauvaise réputation dont il est sujet.

A l'heure de la rédaction de ce wiki, on compte pas moins de 2 000 000 d'utilisateurs, mais si on analyse la courbe, deux pics ressortent nettement, un en 2013, où le nombre d'utilisateurs de Tor est multiplié par 6, mais retombe rapidement, comme si ce n’était qu'un effet de mode. Il se trouve que cette date de 2013 n'est pas anodine, il s'agit de l'année des révélations d'Edward Snowden sur la surveillance de masse aux Etats-Unis, et aussi du suicide de Aaron Swartz, hacktiviste très renommé et apprécié, victime de pression judiciaires importantes. Ainsi, on peut comprendre cette mode de Tor soudaine en 2013.
Un autre pic émerge, en Janvier 2018, le nombre d'utilisateurs de Tor double, nous n'avons pas trouvé de raison apparente, mais si on la compare à l'évolution du Bitcoin pendant cette même période on remarque une chose étrange :

Le bitcoin passe de 6 000 $, à 20 000 $ sur la même période, nous n'avons pas encore trouvé de cause, mais cela nous intrigue.
Toujours est-il que malgré les effets de mode, Tor a tendance à toujours revenir à sa stabilité de 2 000 000 d'utilisateurs, sûrement des utilisateurs de longue date.

Nombre de relais

Système d'exploitation des relais

Type de relais



Lorsqu'on s’intéresse aux relais, on remarque une évolution, mais pas forcément spectaculaire sur les deux périodes citées précédemment. Ce fut donc une affluence d'utilisateurs non volontaires pour héberger un nœud. Tor culmine aujourd'hui a un peu moins de 7 000 nœuds qui sont, sans surprise, tous sur un système Linux. On remarque également que sur tous les nœuds, une minorité sont des nœuds de sortie, ce qui a pour effet de ralentir le nuage Tor par manque de ces mêmes nœuds de sortie. Enfin, une écrasante majorité des nœuds ont le drapeau "Fast", comme le nôtre, ce qui peut indiquer des critères d'obtention relativement bas.
Une autre chose intéressante à voir, c'est le trafic de Tor mondial, la société Uncharted (https://uncharted.software/), spécialisée dans la représentation de données, a établi un site web représentant de manière visuelle le trafic de Tor. Il n'a malheureusement pas été mis à jour depuis 2015 (TorFlow : https://torflow.uncharted.software).

Chaque point bleu est une cellule allant d'un nœud à un autre, on constate quand même que la concentration de trafic cellulaire Tor est très importante en Europe de l'Ouest, ceci est confirmé par un zoom sur l'Europe :

Expérimentations
Pour naviguer sur le réseau Tor, nous avons téléchargé la dernière version de Tor Browser disponible sur le site web de la fondation :
Il s'agit de la méthode la plus simple d'obtenir un ordinateur connecté à Tor de la manière la plus sécurisée possible. Tor Browser est un clone du projet Firefox de Mozilla, sous licence GPL. Il s'agit d'un simple navigateur modifié pour tout faire transiter par Tor.

En pratique, Tor Browser va faire transiter les requêtes par un proxy SOCKS version 5 sur le localhost via le port 9050, sur lequel tourne le logiciel d'onion routing (tor en lui même). En plus du navigateur, Tor Browser inclut divers logiciels purement sécuritaires, comme Privoxy, un proxy HTTP qui va filtrer toutes les fuites HTTP qui pourraient ne pas transiter par Tor, et par conséquent compromettre l'anonymat de l'utilisateur. Ce navigateur est également pourvu de deux extensions nativement : NoScript et HTTPS Everywhere. Par défaut, NoScript bloque l'exécution des scripts JavaScript, Java, Flash, Silverlight et les autres contenus exécutables mais l'utilisateur est libre de les réactiver sur les site qu'il estime de confiance. Nous verrons dans une autre partie de ce Wiki, pourquoi certains scripts peuvent se révéler dangereux pour l'anonymat. HTTPS Everywhere permet quant à lui de forcer l'usage du protocole HTTPS quand le site consulté utilise encore le HTTP par défaut.
Première remarque, il ne faut pas être pressé lorsqu'on navigue sur Tor. C'est loin d'être inutilisable mais il faut bien entendu oublier les téléchargements de fichiers lourds. A titre de comparaison, les deux images ci-dessous montre la différence de temps de téléchargement pour un fichier de 5 MiB hébergé sur un serveur public et sur un service caché. On constate des temps respectifs de 25s contre 70s, ce qui donne des débits de 210 ko/s et 75 ko/s. Si l'on rapporte ces temps pour le chargement d'une page web, comme par exemple le site duckduckgo (468 Ko environ pour la page d'accueil), on obtient un délai de réponse de 2.2s. A l'heure d'aujourd'hui cela peut paraître ridicule néanmoins de tels débits suffisent pour de la navigation classique. Cette faiblesse s'explique en partie par le fait que le nombre d’utilisateurs est passé en un an de 2 millions à 4 millions alors que le nombre nœuds a régressé. Pour ne rien arranger, la dernière image montre une baisse en 2017 et 2018 de la bande passante théorique disponible. Nous avons fait quelques recherches pour voir si ce constat tenait la route et il s’avère que de nombreux utilisateurs se plaignent sur les forums de discussion de la lenteur du réseau ces derniers mois. Enfin, l'implémentation de Tor, de par la création de circuits, rend les communications variables. Il suffit d'un nœud avec une bande passante très faible pour ralentir toute la chaîne de transmission.

Vitesse de téléchargement - Serveurs publics

Vitesse de téléchargement - Services cachés

Bande passante théorique et consommée



Nous avons ensuite visité le hidden wiki, service caché dont l'adresse est trouvable publiquement et qui référencie les principaux sites en .onion, qu'ils soient légaux ou non. On y retrouve beaucoup de forums, de réseaux sociaux, des plateformes de e-commerce centré sur le marché noir mais également des sites dont la pérennité est en danger tels que KickassTorrents ou ThePirateBay. D'autres services comme Facebook ont fait le choix de mettre en place un service caché. Venant d'une entreprise qui vit grâce à nos informations, on est en droit de se demander l’intérêt d'une telle initiative. La réponse est pourtant simple, Facebook a développé ceci pour permettre aux habitants des pays encore censurés de naviguer sur Facebook sans restriction. Pour faciliter la mémorisation du nom de domaine en .onion (facebookcorewwwi.onion), ils ont du déployer une importante puissance de calcul. En effet, les 16 caractères visibles proviennent de la moitié du hash (avec SHA-1) de la clé RSA 1024 bits du service caché passé en base 32. A titre informatif, Scallion permet grâce à la puissance des GPUs de générer entre autre des noms de domaine en .onion suivant un certain paterne. Une formule statistique annonce une durée de 1min30 (avec une GTX 1080) pour un pattern de 8 caractères. Ce temps monte à 27h pour 10 caractères. D'après les dires d'Alec Muffett, ingénieur logiciel en charge du déploiement du service caché, seul le pattern facebook était recherché, le reste se devait simplement d'être mémorisable, chose faite avec corewwwi.
Recentrons nous un peu. Après avoir regardé la configuration réseau de Tor Browser, nous nous sommes dits qu'il devait être possible de naviguer sue Tor via n'importe quel navigateur prenant en charge le SOCKS4/5. Sans grande surprise, cela s'est avéré fonctionnel. Il faut cependant faire preuve de vigilance. En configurant le proxy rapidement, on s'est aperçu que notre processus Firefox, plus précisément notre onglet, utilisé deux sockets. Le premier était effectivement à destination du processus Tor sur son port d'écoute (SocksPort) 9050 alors que le second avait établi une connexion UDP avec le serveur DNS de l'école. On appelle cela une fuite DNS. Nous avons ensuite découvert une option à cocher permettant la résolution de domaine par le proxy, ce qui a résolu ce soucis d'anonymat. A noter également, que la version 4 de SOCKS ne permet pas cette option. Pour résumer, il est plus simple et sûr pour un utilisateur lambda d'utiliser le logiciel fournit par le projet Tor : Tor Browser, qui inclut un tout-en un de sécurité.
Ajout d'un nœud
Nous avons ajouté un noeud Tor directement relié à la ligne SDSL de Polytech, pour ce faire, comme annoncé dans l'introduction, nous avons réalisé une machine virtuelle sur la machine Chassiron qui était libre et reliée à la ligne SDSL.
Création de la machine virtuelle
Avant de s’intéresser à notre nœud, il nous faut créer une machine virtuelle qui va le contenir, pour ce faire nous utilisons les logiciels Xen ainsi que lvm. Xen est un hyperviseur de type un "bare-metal", il s'agit d'une couche entre le hardware et le kernel. Xen va être une sorte de passerelle, qui permet donc de faire tourner plusieurs versions de kernel en parallèle.
Pour la création de la machine virtuelle, nous utilisons Xen, avec la commande suivante :
xen-create-image --hostname=DurotDuq --dhcp --size=10Gb --swap=128Mb --lvm=gis4-pokedex
Cette commande crée deux volumes logiques : DurotDuq-disk et DurotDuq-swap sur le volume de groupe gis4-pokedex, de taille 10Gb et 128Mb respectivement. Ces volumes logiques vont servir de disque pour la machine virtuelle. A savoir que nous aurions très bien pu créer les volumes virtuels en amont. Une swap n'étant pas forcément nécessaire, nous aurions pu avoir strictement le même résultat en rentrant la commande :
lvcreate -L10 -nDurotDuq-disk gis4-pokedex
Puis en utilisant la partition ainsi réalisée dans la configuration de la machine virtuelle. La machine virtuelle étant créée, on peut la configurer via le fichier "/etc/xen/DurotDuq.cfg", où on peut modifier les interfaces réseaux de la machine virtuelle, leurs adresses mac, etc ... En particulier, nous connectons la carte réseau virtuelle sur le bridgeAlternate, qui contient la Vlan47 sur laquelle est la ligne SDSL.

Volumes logiques sur Chassiron

Configuration de la machine virtuelle


Il ne nous reste plus qu'à modifier le fichier /etc/network/interfaces de la sorte :
auto eth0 iface eth0 inet static address 5.23.44.84 netmask 255.255.255.248 gateway 5.23.44.81
Notre VM est maintenant connecté à Internet sans passé par le réseau interne de la FAC.
Ajout du nœud effectif
Pour que notre machine virtuelle fonctionne comme un nœud, il faut premièrement installer Tor sur la machine. Pour se faire, nous avons récupéré le package Tor via les dépôts officiels Debian. Pour être reconnu comme un nœud Tor, il faut qu'elle communique diverses informations aux serveurs d’autorité de Tor, comme son nom, son adresse IP, sa politique (ports TCP autorisés) ...
Voici un exemple de configuration, celui que nous avons utilisé, du fichier /etc/torrc :
SocksPort 0 #1 DataDirectory /var/lib/tor Nickname nom_au_choix #2 Address ip_publique #3 ContactInfo ail@domaine.tld #4 ORPort 9001 #5 RelayBandwidthRate 20 KBytes #6 RelayBandwidthBurst 35 KBytes #7 ExitPolicy reject *:* #8

Dans le cas d'un nœud, le SocksPort (1) peut être mis à 0 car aucun autre processus de la machine ne va communiquer avec Tor. Le Nickname est le nom qui sera attribué à notre nœud, celui sera visible sur les annuaires de recherche de relais comme sur le site officiel Tor Metrics. En (3), nous retrouvons l'IP publique de la machine et en (4) éventuellement une adresse mail afin que le Project Tor puisse nous contacter. Ensuite, ORPort (5) représente le port sur lequel on va communiquer avec notre nœud. L’échange de clefs Diffie-Hellman et le trafic Tor passeront par ce nœud et auront pour destination ce port. Pour limiter ce trafic justement, il nous est possible de choisir la bande passante moyenne et maximale que l'on accorde à notre nœud. En revanche, il faut savoir que la bande passante minimale est de 75 ko/s. Nous indiquons finalement (8) que nous ne souhaitons pas être un nœud de sortie car ce sont les plus vulnérables dans la mesure où ce sont eux qui se connectent "effectivement" aux sites.
Après cette opération effectuée, il faut compter quelques heures pour que le consensus soit mis à jour au niveau des serveurs d'autorité. Mais en pratique, notre nœud a peu de chance d’être choisi lors du routage, il doit d'abord faire ses preuves.
Au bout de quelques heures, notre descripteur de routeur est ajouté au consensus, comme nous pouvons le voir ci-après :
r PopoTor lbW800xEXtwqP3D27GVYf/OAqjo vEfvItA2UJqRVvMnYTo4Gb9pM1g 2018-05-12 15:24:09 5.23.44.84 9001 0
s Fast Running Stable Valid
v Tor 0.2.5.16
pr Cons=1 Desc=1 DirCache=1 HSDir=1 HSIntro=3 HSRend=1 Link=1-4 LinkAuth=1 Microdesc=1 Relay=1-2
w Bandwidth=21
p reject 1-65535
Comme nous pouvons le voir sur la capture de droite ci-dessous, notre nœud est impliqué dans différents circuits. On remarque des sockets ouvertes dans les deux sens, de 9001 (notre ORPort) vers un socket aléatoire (celui d'un autre nœud) et dans l'autre sens. Cette expérience ci ne nous permettra pas de capturer des paquets vers un site web car nous avons refusé d'être un nœud de sortie. C'est pourquoi nous avons fait le choix de mettre en place notre propre réseau privé Tor.
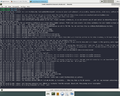
Publication de notre descripteur de routeur
Fiche Tor Atlas de notre nœud
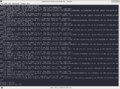
Capture des paquets transitant sur notre nœud



Retour sur la vie du nœud en fin de projet
En fin de projet, notre nœud a été présent sur le nuage Tor pendant plus de 100 jours durant lesquels il a fait transité des données diverses et variées, légales ou non, on peut représenter un bilan sous forme de graphes ci-dessous, on remarque que la probabilité d'être choisi comme relais est toujours inférieure à 0.0002% cela s'explique par le fait qu'il y ait 6000 relais Tor d'une part, et d'autre part, parce que notre débit annoncé est de 100 KiB/s, ce qui ne joue pas en notre faveur, car le client Tor a tendance à aller chercher les nœuds les plus rapides pour assurer un service de la meilleure qualité possible. De plus, on remarque que la probabilité d'être choisi comme nœud de sortie est de 0, sans surprise, nous avions explicité que nous ne souhaitions pas être nœud de sortie dans notre politique.
Fiche Tor Atlas de notre nœud en fin de projet

Bande passante effective au cours du projet

Probabilité d’être choisi lors de la construction d'un circuit



On remarque tout d'abord que contrairement au début du projet, nous avons dorénavant le drapeau "Stable", car notre relais est assez ancien. Ce drapeau "Stable" nous octroie un poids supplémentaire, augmentant nos chances d'être choisis. Plus étonnant, nous avons un drapeau "Fast", ce qui est étrange dans la mesure où notre débit annoncé est de 100 KiB/s, qui est assez peu comparé aux autres relais. Enfin, nous avons obtenu un drapeau "Not recomended" que nous avions pas au début du projet, ce drapeau qui affaiblit grandement nos chances d'être choisis, témoigne d'une version de Tor jugée trop ancienne par le Tor project, ainsi, elle est considérée comme potentiellement dangereuse car manquant de mise à jour de sécurité.
Comme indiqué dans le calendrier des semaines, nous avons mis à jour cette version de Tor en compilant la dernière version, directement depuis le git
Et concrètement, qu'est-ce que cela donne ?
Création d'un service caché
Ajouter des images
Pour cette partie, nous travaillons toujours sur notre VM DurotDuq avec le paquet Tor installé. La première étape consiste à y installer un serveur web, Apache 2 dans notre cas, sans configuration particulière. Nous avons ensuite déposé un simple fichier html de test dans le dossier défaut utilisé par Apache, à savoir /var/www/html. Vient ensuite la configuration du torrc, pour lequel il faut décommenter les lignes suivantes en y ajoutant nos paramètres :
HiddenServiceDir /var/lib/tor/hidden_service/ HiddenServicePort 80 127.0.0.1:8080
La première ligne sert à attribuer un dossier où seront stockés les quelques fichiers liés à notre service caché. La seconde ligne est plus importante. Le premier paramètre est le port sur lequel tor va écouter les connexions extérieures. Le deuxième doit correspondre à l'adresse du serveur web où est stocké le site. Ici, le site étant hébergé sur la même machine, on y indique l'IP de loopback. Le port qui suit est le port d'écoute d'Apache configuré au dessus. De cette façon, c'est le programme tor qui va forger la requête HTTP/S à destination d'Apache. Nous verrons en effet par la suite que ce qui arrive sur le port 80, bien qu'Apache ne soit pas configuré pour utiliser SSL/TLS, est tout de même chiffré.
Pour rafraîchir la configuration, on relance le service : service tor reload
Ceci étant fait, Tor va générer dans le dossier /var/lib/tor/hidden_service/ deux fichiers, hostname et private_key. Ce qui nous intéresse dans cette partie, c'est de récupérer le nom de domaine en .onion de notre service caché situé dans le fichier hostname.
Il ne reste plus qu'à configurer Apache en faisant en sorte qu'il n'écoute que les communications provenant du processus tor, empêchant ainsi l'accès à quiconque de l'extérieur souhaitant accéder au site par son IP.
Dans le fichier /etc/apache2/ports.conf, nous avons changé la ligne Listen 80 par Listen 127.0.0.1:8080. On fait de même pour la configuration du site hébergé par défaut /etc/apache2/sites-enabled/000-default.conf en remplaçant <VirtualHost *:80> par <VirtualHost 127.0.0.1:8080>. Finalement, on ajoute la ligne facultative ServerName unpfl3zm4h577ds3.onion pour se souvenir du domaine. Remarque, le port choisi est totalement arbitraire.
Après un redémarrage du service apache2, le service caché est opérationnel.

Nous pouvons maintenant regarder de plus près ce qu'il se passe au niveau du serveur hébergeant notre service caché. Pour cela nous avons fait une capture de paquets avec tcpdump que l'on a ensuite analysé avec Wireshark pour faciliter la lecture.

Nous avons pu constater et vérifier que les données qui arrivent sur le port 80 de la machine sont chiffrées. Ensuite, on voit bien la communication entre Apache et Tor (requête et réponse HTTP) et finalement tor qui acheminent la réponse jusqu'au premier nœud.
Réseau privé Tor et analyse de la sécurité
L'état de l'art du réseau Tor passe par une analyse de la sécurité. De par l'architecture de Tor, nous avons su de nous-même déterminer des potentielles failles dans le fonctionnement du réseau. Par la suite, nous avons consulté des articles de recherche portant sur le sujet qui nous ont appris bien d'autres vulnérabilités toujours d'actualité ou non. Pour vérifier ces théories, nous avons eu l'idée de mettre en place un réseau privé Tor sur Chassiron. En effet, ceci nous donnera accès à tous les acteurs de la transmission du client vers le serveur web (par exemple) avec notamment un contrôle total des nœuds depuis lesquels nous pourront analyser les entrées / sorties de données.
Du point de vue technique, des solutions existantes répondent à nos attentes comme Chutney et Shadow mais nous avons trouvé préférable et plus confortable de bâtir le nôtre. Sur le serveur Chassiron, nous avons "recyclé" 3 VMs existantes. Les VMs occupent plusieurs rôles dans ce réseau, pour rappel :
- Goupix : nœud + directory server
- Groudoudou : nœud de sortie
- Grolem : noeud + directory server + serveur web

Dans un premier temps, nous avons installé Tor sur les 4 machines du réseau sans s'occuper de la configuration. Au fil des semaines, comme détailler dans le descriptif des semaines, nous avons tenté de bâtir ce réseau en modifiant nous même les torrc. Sans vraiment d'explications concrètes, il n'a jamais eu le comportement souhaité. Nous nous sommes donc servi de Chutney pour construire les torrc des machines virtuelles et finalement avoir notre réseau privé fonctionnel.
Afin de tester son fonctionnement, nous avons tout d'abord configurer le torrc d'une tutur pour la connecter à notre réseau. Une fois le proxy firefox correctement configuré nous étions en mesure de naviguer sur Internet en faisant passer le trafic par nœuds. Pour nous convaincre du réel fonctionnement, nous avons créé un serveur web retournant une page html composée de l'IP l'ayant contactée. Cet outil nous a été utile pour ces premiers tests avec IPs privés mais par la suite nous avons obtenus des IP "rootables" pour nos VMs rendant ce programme inutile. Après que le réseau fut reconfiguré, nous avons été en mesure de nous y connecter depuis chez nous. Pour ce faire, nous avons installé tor sur nos PCs respectifs et avons modifié le torrc pour dire qu'il s'agissait d'un réseau de test où l'on spécifiait nos propres directory servers. Toujours après avoir mis le proxy SOCKS5, nous étions en mesure de naviguer de chez nous en passant par nos VMs.

A gauche sur cette capture, nous avons un navigateur n'utilisant aucun proxy. L'IP affichée est bien celle attribuée par mon fournisseur d'accès Internet. Sur la droite, on retrouve un firefox connecté à Tor grâce aux options réseau suivantes :

Le résultat du site nous affiche bel et bien l'IP du seul nœud de sortie de notre réseau (grodoudou). Le site en haut à gauche et à droite est d'ailleurs celui que nous avons conçu.
Ayant maintenant le contrôle sur toutes les entités de la communication, nous allons pouvoir analyser les paquets qui transitent. La solution qui nous semble la plus adéquate pour cela est de capturer à l'aide de tcdump sur les VMs et d'enregistrer les données dans des fichiers binaires pcap pouvant être interprétés par Wireshark.
Intéressons nous dans un premier temps aux échanges depuis et vers le client.

Ce qu'il est important de remarquer en plus des annotations déjà présentes sur l'image, c'est que le contenu qui transite entre le client et le premier nœud est chiffré alors qu'il s'agit d'une requête HTTP et non HTTPS.

Si on se place maintenant au niveau du second nœud, on s’aperçoit encore que les liaisons vers le nœud précédent et suivant sont chiffrées. Ceci répond déjà à une des questions du sujet : si quelqu'un à la main sur un nœud il ne peut rien faire à moins de connaître les clés AES du circuit ainsi que les clés entrant en jeux dans la liaison TLS.

Finalement, si l'on regarde du coté du serveur web, on constate que la requête GET a lieu en clair dans le cas de HTTP. Tor ne protège donc aucunement les échanges HTTP car le dernier nœud est en mesure de lire le contenu partagé avec le serveur web. Étrangement, nous ne voyons sur cette capture que la réponse du serveur web mais pas la requête effectuée par le nœud de sortie. Sur Wireshark, les seuls échanges d'un port aléatoire (nœud de sortie) vers le port 8888 du serveur web sont des trames TCP SYN et SYN/ACK. A l'écriture de ces lignes, nous ne comprenons toujours pas ce comportement.
Annexes
Chiffrement : Généralités
Tor utilisant un ensemble de méthodes de chiffrement pour garantir l'anonymat et la protection des données, nous nous devions d'écrire une partie à ce sujet. Il existe deux méthodes pour chiffrer un message, le chiffrement symétrique et asymétrique. Bien que le concept soit le même, à savoir empêcher la compréhension par un tiers malveillant des données transitant par un canal de communication, le principe et la mise en place diffère. Nous verrons dans les deux paragraphes suivants deux méthodes de chiffrement très couramment utilisées.
Chiffrement asymétrique : RSA
Rédaction en cours
Le chiffrement asymétrique est un procédé de chiffrement basé sur des paires de clefs privées/publiques différentes les unes des autres. En plus d'assurer la confidentialité il est également possible de prouver l'authenticité de l'émetteur pour quelqu'un qui reçoit le message. Ces deux critères sont réalisables séparément ou conjointement. Maintenant, considérons sans changer les habitudes, Alice et Bob deux personnes souhaitant communiquer s'étant déjà échangés leur clef publique. Si Alice souhaite envoyer un message à Bob de manière confidentielle alors elle le chiffrera avec la clef publique de Bob. Ainsi, bien que tout le monde ait pu intercepter la communication, seul Bob avec sa clef privée sera en mesure de comprendre le sens. Si maintenant Alice souhaite seulement prouver à Bob que c'est bien elle, elle chiffrera le message avec sa clef privée à elle. De cette façon, toutes les personnes en possession de la clef publique d'Alice, y compris Bob, pourront lire le message en sachant que c'est elle et elle seule qui a écrit. Finalement, il est possible de combiner tout cela pour assurer à la fois l'authentification et la confidentialité. Il suffit de chiffrer le message avec la clef privée d'Alice puis de recommencer avec la clef publique de Bob.
Pour réaliser ceci, RSA et ses variantes (1024/2048/4096 bits) sont les plus utilisées de nos jours. Sans grande surprise, la force de cette algorithme repose sur des théorèmes mathématiques et l'utilisation de nombres premiers de grandes tailles. Voici maintenant la procédure pour générer cette paire de clefs :
- On choisit 2 nombres premiers p = 7 et q = 11 volontairement petits pour l'exemple
- On calcule le produit n = pq = 77
- On calcule Phi(n) = (p-1) * (q-1) = 60
- On choisit e = 13 premier avec Phi(n) et e < Phi(n)
- d = 37 tel que d*13 mod 60 = 1 et d < Phi(n)
La clef publique d'Alice est donc (77,13) et la clef privée (77,37). Ainsi, Bob doit pour envoyer son message M = 3, calculer C = 3^13 mod 77 et Alice pour comprendre devra déchiffrer en faisant M = C^37 mod 77.
En pratique les données sont regroupées en blocs et interprétés comme des grands nombres. Pour envoyer "bonjour", RSA ne sera pas appliqué sur 'b' puis 'o' ... mais plutôt sur "bonjour" qui sera paddé pour respecter la taille de la clef (1024, 2048 ou 4096 bits). Appliquer RSA octet par octet serait bien trop coûteux en ressource au vu des calculs réalisés lorsqu'il s'agit de grands nombres.
Exemple réel d'un p/q : 12131072439211271897323671531612440428472427633701410925634549312301964373042085619324197365322416866541017057361365214171711713797974299334871062829803541
Chiffrement symétrique : AES
Rédaction en cours
Considérons Alice et Bob, deux personnes voulant discuter anonymement. Le chiffrement symétrique dit que ces deux personnes doivent posséder la même clef pour chiffre et déchiffrer et ainsi pouvoir se comprendre. L'avantage principal est une réduction en terme de temps de calcul comparativement à son homologue. Cependant, dans le cas d'une communication à distance, par Internet par exemple, les deux parties doivent d'abord s'échanger cette clef. C'est pour cette raison que cette méthode est souvent couplée à d'autres algorithmes basés sur le chiffrement asymétrique pour établir ce que l'on appelle des clefs de session. Le protocole TLS par exemple, que nous verrons ensuite, utilise ce procédé.
Nous allons maintenant s'intéresser dans les grandes lignes à son fonctionnement, plus précisément à la partie chiffrement, et pour ce faire nous étudierons un exemple tiré de la publication officielle d'AES qui concerne une clef AES de 128 bits (pour information, trois tailles de clef existent, 128, 192 et 256 bits). Notons dans un premier temps qu'une clef AES (peut importe sa taille) n'est qu'une succession de bits aléatoires générée avec des algorithmes favorisant un aléatoire non prédictible. Secondement, parce que ce n'est pas l’objectif premier ce projet (et que les concepts sont pour certains très compliqués), nous ne rentrerons pas en détail dans les aspects mathématiques. Néanmoins, en lisant la documentation nous aurions été capables de rédiger cet algorithme de chiffrement dans un langage de programmation quelconque.

Ici, seule la partie de gauche va nous intéresser car traitant du chiffrement et non du déchiffrement. En entrée nous avons un bloc de données d'une taille de 128 bits qui va se faire transformer sur plusieurs itérations (10 pour AES128) avant de donner son équivalent chiffré de 128 bits également. Les 128 bits en entrée son valables quelque soit la longueur de la clef AES et les données dépassant cette taille seront coupés en plusieurs blocs et le dernier sera éventuellement remplis de valeurs non pertinentes.

Les données en clair sont dans un premier temps XORé avec la première round key pour initialiser l'algorithme. Cette clef provient directement de la clef AES qui est transformée en 44 mots de 4 bytes (les 4 premiers étant la clef elle même) appelés Key Schedule et utilisés pour chaque itération et pour l’initialisation. C'est la génération de cet en ensemble de clefs que nous ne verrons pas ici.
Lors de la première itération nous débutons les étapes avec la matrice obtenue à l'initialisation. Nous allons appliquer une substitution sur tous les octets de la matrice. Cette opération utilise la table de correspondance appelée aussi S-Box pour déterminer les nouveaux paramètres.

Si on prend l'exemple de 0x19, il suffit de chercher la valeur à la position x=1 et y=9 correspondant aux 4 derniers bits et 4 premiers bits de 0x19. Avec cette nouvelle matrice, nous allons maintenant permuter les lignes de la manière suivante :

S'en suit l'opération de Mix Column qui consiste en une multiplication de matrices où les additions seront remplacées par des XOR.

Finalement, cette matrice sera XORé en colonne avec les 4 mots suivants du Key Schedule.
Le résultat de cette itération constituera la matrice de départ de la suivante et après les 10 tours, l'algorithme ressortira le premier bloc chiffré.
Concernant le déchiffrement, le processus est basé sur les opérations inverses et ne vaut par conséquent pas la peine d'être explicité.
Si AES est tant utilisé de nos jours c'est parce qu'il n'a toujours pas été cassé et que le seul moyen pour le moment est d'utiliser une méthode dite de force brute qui nécessiterait un maximum de 2^128 opérations pour une clé AES 128 bits.
Echange de clefs Diffie-Hellman

Lorsqu'on veut sur internet communiquer de façon chiffrée, il faut une clef de chiffrement, seulement il se pose le problème de savoir comment cette clef de chiffrement est envoyée, car si elle circule sur le réseau en clair, une simple attaque passive de "man in the middle" (MITM) permet de récupérer la clef de chiffrement et donc d'intercepter et de décrypter les données échangées. C'est un vrai problème d’œuf et de la poule, il faut du chiffrement pour pouvoir échanger la clef de chiffrement.
Ce problème est réglé grâce à l'échange de clefs Diffie-Hellman, il s'agit d'une manière pour Alice et Bob de se mettre d'accord sur la même clef de chiffrement symétrique, en échangeant des informations en amont afin de pouvoir calculer la clef. Sans qu'Eve ne soit capable de connaître la clef même en écoutant le trafic. Plus simplement, on peut vulgariser ça en deux personnes qui crient au milieu d'une foule, les deux personnes se sont mises d'accord sur une chose commune, mais il est impossible pour la foule de deviner ce dont les deux personnes se sont mis d'accord. Ce "miracle" nous vient de Whitfield Diffie et Martin Hellman en 1976. Et c'est la base de tout chiffrement sur le web (HTTPS, SSH, SFTP, etc...).
Le principe est le suivant :
- Alice choisit un nombre premier p et une base g, dans notre exemple p = 23 et g = 3 (g est connue d'Alice et de Bob)
- Alice choisit un nombre secret, a = 6
- Alice envoie à Bob A = ga [mod p] = 36 [mod 23] = 16
- Bob choisit à son tour un nombre secret b = 15
- Bob envoie à Alice la valeur B = gb [mod p] = 315 [mod 23] = 12
- Alice peut maintenant calculer la clé secrète : (B)a [mod p] = 126 [mod 23] = 9
- Bob fait de même et obtient la même clé qu'Alice : (A)b [mod p] = 1615 [mod 23] = 9
Alice et Bob se sont bien mis d'accord sur la même clef sans la faire transiter en clair.
Malheureusement, cette méthode d'échange ne permet pas de se prémunir des attaques actives d'un MITM (Man-In-The-Middle). En effet, cette tierce personne va servir de relais entre Alice et Bob. Autrement dit, une clé symétrique K1 sera négocié entre Alice et Eve et une autre K2 entre Bob et Eve. Ainsi, quand Alice parlera à Bob (en chiffrant son message avec K1), son message sera en fait reçu et déchiffré par Eve avant d'être à nouveau chiffrer avec K2 et transmis à Bob qui sera en mesure de le déchiffrer. Donc Alice et Bob pense se parler directement et ignore complètement l'attaquant interposé dans leur communication. Nous verrons dans le paragraphe suivant qu'il est possible de garantir l'authenticité de la réponse obtenue au moyen d'un protocole très connu dans son application au web ; il s'agit de TLS.
Le protocole TLS

{kind=link}
{kind=link}
{kind=link}
Nous avons vu que les échanges entre deux nœuds successifs s'effectuent toujours au moyen d'une connexion TLS (Transport Layer Security). Avant d'expliquer la nécessité d'une telle connexion, il est nécessaire d'expliquer brièvement son fonctionnement sans non plus s'attarder sur tous les détails. Nous connaissons d'avantage ce protocole sous le nom de SSL (Secure Sockets Layer) qui n'est ni plus ni moins que son prédécesseur aujourd'hui désapprouvé par l'IETF dans toutes ses versions. En plus de garantir la confidentialité des données grâce à l'utilisation d'algorithme de chiffrement, son usage permet également l'authentification du serveur vis à vis du client ainsi que l'intégrité des données échangées. Pour éviter les longues phrases, prenons un exemple de communication entre Bob et Alice.
Nous considérons dans cet exemple la suite cryptographique : TLS_DHE_RSA_WITH_AES_256_CBC_SHA.
Ce qui signifie qu'on utilise l'algorithme DHE pour l'échange de clés, RSA pour l'authentification, AES (256bits) en mode d'opération CBC (Cipher Block Chaining) pour le chiffrement par bloc et enfin SHA256 pour le calcul du MAC. Nous reviendrons évidemment sur tous ces termes dans la suite mais il était important de stipuler cette donnée dès maintenant car elle influencera l'échange.
- Alice (le client) souhaite communiquer de manière confidentielle avec Bob (le serveur). Elle envoie pour cela un Client.Hello contenant une liste de suite cryptographique (plus connu sous le terme anglais de cipher suit) rangée par ordre de priorité décroissant, la version de TLS utilisée ainsi qu'un mot de 32 octets généré aléatoirement.
- Bob fait de même est envoie pour commencer un Server.Hello contenant la suite cryptographique retenue (il essaye dans la mesure du possible de prendre la suite favorite du client), un mot de 32 octets aléatoire et un identifiant de session. Ce paquet contient également le certificat électronique X.509 du serveur qui est pourvu de différentes informations comme les dates limites de validité, l'algorithme de signature du certificat, le type et la clé publique du serveur ou encore le nom de l'autorité de certification lorsque celui-ci n'est pas auto-signé. En fin de certificat se trouve la signature qui est générée en chiffrant le condensat du certificat avec la clé privée. Le paquet se compose ensuite de la Server.KeyExchange (en réalité cette clé peut être optionnelle selon la cipher suit choisie). Dans le cadre d'un échange de clé suivant la méthode DHE (Ephemeral Diffie-Hellman), le serveur envoie sa partie du DH c'est à dire la base g choisie, le nombre premier p ainsi que le résultat ga [mod p] avec a une valeur aléatoire. Finalement, un Server.Done est envoyé indiquant simplement la fin de la procédure Hello côté serveur.
- Le client est maintenant en mesure de vérifier l'authenticité du certificat. Pour cela, il commence par générer un condensat selon la fonction choisie par le serveur (cette fonction est présente dans le certificat et peut être différente de celle indiquée dans la suite cryptographique). Après avoir déchiffré la signature avec la clé publique, Bob peut comparer les deux condensats et attester de la validité du certificat. En réalité, un problème peut se poser à cette étape. Comment peut-on garantir que le certificat reçu n'est pas celui d'un attaquant venu s'intercaler au milieu de l'échange et gérant ainsi deux connexions avec Alice et Bob. Sur le web, les administrateurs de sites font appel à des Autorités de Certification (CA). Rapidement, les certificats sont émis de ces autorités et lorsque les clients les reçoivent, leur navigateur est en mesure de vérifier leur provenance en parcourant une liste de clés publiques de ces CA. Dans le cas de Tor, ces serveurs d’autorités n'existent pas directement. Néanmoins même si un MITM venait s'ajouter, il serait incapable de déchiffrer le véritable message (post TLS) car celui-ci est également chiffré avec la clé publique de Bob (cf. paragraphe sur la création de circuits). Recentrons-nous. Bob va générer sa partie du DH en choisissant son nombre b et sera ainsi en mesure de connaître sa pre-master key sous la forme gab [mod p] dont nous verrons l'utilité ensuite. Il termine en envoyant à Alice sa partie du DH (gb [mod p]) suivi d'un Client.ChangeCipherSuite indiquant que la suite des échanges sera chiffrée avec la clé symétrique AES calculée et finalement un Client.Finished.
- Le serveur connaît maintenant (grâce à la partie du client) le secret commun du DH qui sera sa pre-master key. Il va donc pouvoir générer la clé symétrique AES de son côté également. Ensuite, même procédure que le client, il envoie son Server.ChangeCipherSuite et son Server.Finished.
Le déroulement et la chronologie maintenant fixés, nous pouvons revenir sur certaines parties laissées dans l'ombre avec notamment la génération de la, ou plutôt des, clés AES. Repartons de l'étape 3, où le client à toutes les cartes en sa possession. Il va commencer par calculer le master secret. L’intérêt d'une telle clé est d'harmoniser la longueur des clés (pre-master keys) qui dérivent des méthodes d'échange en formant un secret d'une taille fixe de 48 octets. Comme indiqué dans le RFC 5246, le calcul est le suivant :
Derrière la fonction PRF (Pseudo Random Function) se cache une formule permettant la génération d'un mot de taille souhaitée selon une fonction de hachage itérative (plus exactement une HMAC de l'anglais keyed-hash message authentication code). Le PRF découle de la formule ci-après :
Le protocole recommande l'utilisation de la fonction de hachage SHA256. Le secret est notre pre-master secret, le label est la chaîne de caractère "master secret" et enfin le seed correspond à la concaténation des deux valeurs aléatoires de 32 octets du client et du serveur.
P_SHA256(secret, seed) =
HMAC_SHA256(secret, A(1) + seed) +
HMAC_SHA256(secret, A(2) + seed) +
HMAC_SHA256(secret, A(3) + seed) + ...
Avec l'opérateur + désignant la concaténation et le paramètre A() défini de la sorte :
A(0) = seed
A(i) = HMAC_SHA256(secret, A(i-1))
La master key devant faire une taille de 48 octets, il est nécessaire d'itérer deux fois (32 octets par hash pour le SHA256). Le résultat fourni est donc une clé de 64 octets qui sera simplement tronquée pour donner la fameuse master key.
En possession de la master key, le client va maintenant pouvoir générer un ensemble de 6 clés (appelé key_block) qui lui seront utiles une fois le handshake terminé.
key_block = PRF(SecurityParameters.master_secret, "key expansion", SecurityParameters.server_random + SecurityParameters.client_random);
Cette fonction sera répétée autant de fois que nécessaire pour peupler les clés suivantes sachant que les vecteurs d'initialisation (IV) sont générés mais pas toujours utilisés. Ici dans le cas de AES_256_CBC, ils sont nécessaires.
- client_write_MAC_secret[256 bits]
- server_write_MAC_secret[256 bits]
- client_write_key[256 bits]
- server_write_key[256 bits]
- client_write_IV[256 bits]
- server_write_IV[256 bits]
A cette étape, le client est capable de calculer toutes les clés finales qui lui serviront pour les échanges à venir. Nous pouvons d'ores et déjà constater que la clé de chiffrement AES ne sera pas la même selon le sens de l'information, serveur vers client ou client vers serveur. Nous ne rentrerons pas dans les détails pour les algorithmes AES et SHA.
Pour clôturer le handshake de son côté, nous avions vu que le client envoyait un Client.Finished. Il va servir à prouver que personne n'ait altéré le handshake et que le client possède les clés. Il va calculer pour cela le verify_data un mot de 12 octets calculé comme suit :
verify_data = PRF(master_secret, "client finished", SHA256(handshake_messages))[12];
On prend ensuite le résultat (verify_data) et on y ajoute en tête l'octet 0x14 pour indiquer "finished" ainsi que la longueur des données effectives, ici 12 octets, ce qui donne 0x00000C. Finalement, ce qui sera envoyé sera : 14 00 00 0C + AES(verify_data + hash(verify_data)) avec hash la version HMAC (de l'anglais keyed-hash message authentication code) de SHA256.
Le serveur va réceptionner ces informations, les vérifier et envoyer de la même manière que le client son Server.ChangeCipherSuite et son Server.Finished. Ce dernier sera différent de celui reçu car il contiendra en plus le Server.ChangeCipherSuite et le Server.Finished du client. De cette manière, le client pourra à la réception vérifier que verify_data lui revient sans avoir été altéré.
C'est ainsi que se s'achève les 200 ms du "handshake" complet de TLS 1.2. Toutes les données qui suivront seront chiffrées et précédées d'un court en-tête TLS. Comme répétés de nombreuses fois, il nous est arrivé de rester assez évasif sur certains concepts liés au protocole. Bien que notre curiosité nous ait amené à faire des recherches approfondis sur des sujets comme HMAC, AES, SHA, les modes d'opération (ECB, CBC ...), nous n'avons pas trouvé nécessaire d'en faire des annexes dans l'immédiat. Il est bien de savoir également qu'à l'heure où nous écrivons ces lignes l'IETF vient enfin de valider la version 1.3 de TLS dont la caractéristique principale est de réduire la durée du "handshake" de moitié.
Avant de clôturer cette partie, on pourrait se poser la question suivante : Pourquoi DHE est-il nécessaire ? Autrement dit, pourquoi utiliser la clé publique du serveur pour générer une clé symétrique n'est pas recommandé. Jusqu'à maintenant nous n'avons parlé que d'authentification, de confidentialité des données échangées et d'intégrité. Mais un autre concept entre jeu, celui de la confidentialité persistante. Imaginons une personne qui s'était amusé à enregistrer toutes les communications chiffrées d'un serveur et qui quelques années après se retrouve en possession de la clé privé qu'il a pu obtenir soit par un vol soit par une solution plus mathématique qui permettrait d'inverser la clé publique. Comme tous les échanges du serveur étaient basés sur un chiffrement par clé privé, cette personne serait en mesure de tout déchiffrer. Sans connaître ce genre de propriété, on a toujours tendance à penser que certaines couches sont redondantes alors que très souvent leur présence n'est pas anodine.
Bibliographie
- https://svn.torproject.org/svn/projects/design-paper/tor-design.pdf
- https://www.torproject.org/docs/documentation.html.en
- https://www.usenix.org/system/files/conference/foci12/foci12-final2.pdf
- https://www.freehaven.net/anonbib/cache/abbott-pet2007.pdf
- https://witestlab.poly.edu/blog/anonymous-routing-of-network-traffic-using-tor/
- https://research.torproject.org/techreports.html
- https://gitweb.torproject.org/torspec.git/tree/
- https://www.ietf.org/rfc/rfc5246.txt
- https://csrc.nist.gov/csrc/media/publications/fips/197/final/documents/fips-197.pdf
Sans compter la multitude de pages Wikipédia et post sur Stack Overflow / Stack Exchange pour ne citer qu'eux.
- https://tor.stackexchange.com/
- https://security.stackexchange.com/
- https://crypto.stackexchange.com/