IMA5 2022/2023 P15 : Différence entre versions
(→Semaine 7 : 05/12/2022 - 09/12/2022) |
(→Semaine 6 : 21/11/2022 - 25/11/2022) |
||
| (38 révisions intermédiaires par 2 utilisateurs non affichées) | |||
| Ligne 236 : | Ligne 236 : | ||
*Portable chargé à 50% en veille (Cas_50_v) | *Portable chargé à 50% en veille (Cas_50_v) | ||
*Portable chargé à 50% avec une application ouverte (Cas_50_app) | *Portable chargé à 50% avec une application ouverte (Cas_50_app) | ||
| − | Dans tous les cas, le smartphone est en '''mode avion''', et nous réalisons des mesures avec | + | Dans tous les cas, le smartphone est en '''mode avion''', et nous réalisons des mesures avec nos deux portables et leurs chargeurs respectifs. Nous obtenons donc 8 cas différents que nous essaierons de différencier. |
| − | Nous avons ensuite modifier nos différents scripts afin de parcourir cette arborescence de fichier et récupérer tous les fichiers .wav nous intéressant. Cette lecture prend également en compte tous | + | Nous avons ensuite modifier nos différents scripts afin de parcourir cette arborescence de fichier et récupérer tous les fichiers .wav nous intéressant. Cette lecture prend également en compte tous fichiers ajoutés par la suite sans avoir à modifier le code. Nous avons également modifier le script permettant de séparer un fichier stéréo en deux fichiers mono afin que celui-ci s'exécute sur tous les fichiers présents dans l'arborescence. |
| − | Nous avons réalisé une série de mesures dans 4 des cas cité au dessus (5 mesures par cas) afin de pouvoir prendre en main les algorithmes qui nous | + | Nous avons réalisé une série de mesures dans 4 des cas cité au dessus (5 mesures par cas) afin de pouvoir prendre en main les algorithmes qui nous permettront de différencier les cas : |
*Portable de Ali chargé à 100% en veille (Cas_100_v) | *Portable de Ali chargé à 100% en veille (Cas_100_v) | ||
*Portable de Ali chargé à 100% avec une application ouverte (Cas_100_app) | *Portable de Ali chargé à 100% avec une application ouverte (Cas_100_app) | ||
| Ligne 250 : | Ligne 250 : | ||
[[Fichier:PCA_CH1-2.png|750px]] | [[Fichier:PCA_CH1-2.png|750px]] | ||
| − | Nous pouvons voir que les quatre cas sont | + | Nous pouvons voir que les quatre cas sont distinguables à l'œil nu. |
| − | Enfin, nous avons commencé à travailler avec l'algorithme de segmentation '''SVM''' de la librairie ''sklearn''. Nous avons séparé nos données en une partie | + | Enfin, nous avons commencé à travailler avec l'algorithme de segmentation '''SVM''' de la librairie ''sklearn''. Nous avons séparé nos données en une partie destinée à l'apprentissage (80% des données) et une partie à tester (20% des données). En réalisant les tests nous obtenons les résultats suivants : |
[[Fichier:rapport_class_pca.png|500px]] | [[Fichier:rapport_class_pca.png|500px]] | ||
| − | Nous pouvons voir dans la colonne ''f1-score'' que la plupart des mesures sont bien classifiées, mais nous avons plusieurs erreurs. Cela est grandement dû au faible nombre de mesures que nous avons | + | Nous pouvons voir dans la colonne ''f1-score'' que la plupart des mesures sont bien classifiées, mais nous avons plusieurs erreurs. Cela est grandement dû au faible nombre de mesures que nous avons prises. Nous allons donc par la suite effectuer des mesures en plus grand nombre afin de vérifier de manière plus précise la fiabilité de notre méthode. |
===Semaine 7 : 05/12/2022 - 09/12/2022=== | ===Semaine 7 : 05/12/2022 - 09/12/2022=== | ||
| Ligne 308 : | Ligne 308 : | ||
Nous avons donc choisi de réaliser une boite acoustique qui nous permettra d'effectuer nos mesures dans de meilleures conditions. Une fois que celle-ci sera réalisée nous effectuerons une nouvelle série de mesures que nous utiliserons afin de mieux observer l'influence du nombre de données décimées et de la longueur des échantillons, ainsi que les limites de notre modèle. | Nous avons donc choisi de réaliser une boite acoustique qui nous permettra d'effectuer nos mesures dans de meilleures conditions. Une fois que celle-ci sera réalisée nous effectuerons une nouvelle série de mesures que nous utiliserons afin de mieux observer l'influence du nombre de données décimées et de la longueur des échantillons, ainsi que les limites de notre modèle. | ||
| + | |||
| + | |||
| + | Nous avons également pris en charge dans notre code la génération et l'attribution automatique des couleurs pour chaque cas, en prenant des points régulièrement espacés sur le segment "''Hue''" du domaine de couleur ''HSV''. Cette attributions de couleurs n'est pas parfaite car on peut retrouver des couleurs assez proches et elle n'utilise pas les segments ''Saturation'' et ''Value'' mais permet de distribuer des couleurs à chaque cas de manière dynamique (si on ajoute des cas, leurs couleurs leur seront données automatiquement). | ||
| + | |||
| + | ===Semaine 8 et 9 : 12/12/2022 - 16/12/2022 et 02/01/2023 - 06/01/2023=== | ||
| + | |||
| + | Lors de cette semaine, nous avons terminé la fabrication de la boîte d'isolation acoustique, dans le but de réaliser des mesures dans un endroit bien isolé. | ||
| + | Cette boîte a été réalisée grâce aux matériel fournit par nos tuteurs (mousse acoustique), et les ressources présentes aux fabricarium de Polytech. | ||
| + | |||
| + | [[Fichier:boite_iso.jpg|left|thumb|Boîte à isolation acoustique|400px]] | ||
| + | [[Fichier:boite_iso2.jpg|center|thumb|Boîte à isolation acoustique|250px]] | ||
| + | |||
| + | [[Fichier:PCA_dataset3.png|right|thumb|PCA sur le nouveau jeu de données|500px]] | ||
| + | |||
| + | |||
| + | |||
| + | Par la suite nous avons réalisé un nouveau jeu de mesures en écoutant l'appareil dans cette boite, dans les mêmes cas d'utilisation que précédemment. | ||
| + | * Smartphone chargé à 100% en veille (''Cas_100_v'') | ||
| + | * Smartphone chargé à 100% avec une application ouverte (''Cas_100_app'') | ||
| + | * Smartphone chargé à 50% en veille (''Cas_50_v'') | ||
| + | * Smartphone chargé à 50% avec une application ouverte (''Cas_50_v'') | ||
| + | Pour nos deux smartphones (''Tali'' et ''Tlogan'', toujours en mode avion, soit 8 cas différents. | ||
| + | |||
| + | |||
| + | |||
| + | Nous avons pris 10 mesures par cas, pour un total de 80 mesures. Cependant lorsque nous appliquons l'algorithme de PCA nous remarquons que les points ne sont pas répartis par cas mais ce mélangent, ce qui rendrait la différentiation ardue. | ||
| + | |||
| + | |||
| + | Nous avons donc essayé divers traitements des données afin d'améliorer nos résultats et de permettre un différentiation fiable par la suite, que nous consignerons dans la partie '''Résultats'''. | ||
| + | |||
| + | ==Résultats== | ||
| + | Dans cette partie, nous allons vous présenté les résultats obtenus avec un nombre de mesures, considerés élevé par rapport aux dataset du début. | ||
| + | |||
| + | Dans cet dataset, nous avons environnement 80 mesures, pour les deux portables, et les cas différents. | ||
| + | |||
| + | En premier lieu, nous avons fourni à nos programmes de PCA, les 80 fichiers, d'où le resultat obtenu était le suivant : | ||
| + | |||
| + | |||
| + | |||
| + | [[Fichier:PCA_dataset3.png|center|thumb|PCA préliminaire|500px]] | ||
| + | |||
| + | |||
| + | On remarque que les résultats obtenus ne sont pas très satisfaisant, où nous n'arrivons pas à différencier les appareils, mais il est tout à fait possible de distinguer les cas de fonctionnement. | ||
| + | Ce résultat nous a poussé d'aller modifier notre chaîne du '''traitement du signal''', pour améliorer les résultats. | ||
| + | |||
| + | Dans une deuxième tentative, nous nous sommes servis du cours du traitement du signal de 4A, où nous avons pensé qu'un effet de fenêtrage sur le signal a eu lieu, pour cela nous avons implémenté une fenêtre de Hamming, où la fenêtre de Hamming tend à "adoucir la transition" du signal sur les bords. | ||
| + | ''' IMAGE DE SIG AVEC FENETRE ICIIIII''' | ||
| + | |||
| + | Ensuite, nous avons pensé au fait de filtré les signaux de la FFT, selon un pourcentage, c'est-à-dire, que toute les puissances inférieurs à x% de la puissance maximale, sont virées, et on ne garde que ceux qui sont supérieures. Des tests ont été faites pour x=1%, x=2%, x=3% et voici les resultats obtenus : | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | [[Fichier:pca_par_puissance_filtre_1per.png|left|thumb|PCA avec x=1%|300px]] | ||
| + | [[Fichier:pca_par_puissance_filtre_2per.png|center|thumb|PCA avec x=2%|300px]] | ||
| + | [[Fichier:pca_par_puissance_filtre_3per.png|right|thumb|PCA avec x=3%|300px]] | ||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| + | |||
| Ligne 319 : | Ligne 384 : | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | Un autre essai consiste à ramener les valeurs de la FFT à sa valeur max, cela est fait dans le bloc de calcul de la FFT, qui nous donné ce résultats : | |
| − | + | [[Fichier:Intervalle_complet_max.png|center|thumb|Intervalle complet et ramené à la valeur max|300px]] | |
| − | + | Pour ce cas, nous remarquons que ces resultats sont pas du tout correctes, où il est impossible de faire aucune distingution ni pour les cas de fonctionnement, ni pour les objets étudiés. | |
| − | |||
| − | |||
| − | Pour | ||
==Documentation== | ==Documentation== | ||
Version actuelle datée du 21 janvier 2023 à 20:47
Sommaire
- 1 Présentation générale du projet
- 2 Cahier des charges
- 3 Cahier des Spécifications
- 4 Réalisation du projet
- 4.1 Semaine 1 : 05/09/2022 - 09/09/2022
- 4.2 Semaine 2 : 19/09/2022 - 24/09/2022
- 4.3 Semaine 3 : 03/10/2022 - 07/10/2022
- 4.4 Semaine 4 : 17/10/2022 - 21/10/2022
- 4.5 Semaine 5 : 07/11/2022 - 11/11/2022 et Semaine des vacances de Toussaint
- 4.6 Semaine 6 : 21/11/2022 - 25/11/2022
- 4.7 Semaine 7 : 05/12/2022 - 09/12/2022
- 4.8 Semaine 8 et 9 : 12/12/2022 - 16/12/2022 et 02/01/2023 - 06/01/2023
- 5 Résultats
- 6 Documentation
Réalisation d’un système d’écoutes sonores à base de MEMS
- Dépôt Git : https://archives.plil.fr/akhalaf/systeme_ecoute
Présentation générale du projet
Contexte
Les objets connectés se déploient de façon massive dans nos vies personnelles et quotidiennes. La simplicité de création de ces objets permet la mise sur le marché de nombreux nouveaux objets commerciaux, voire artisanaux grâce au mouvement DIY (Do It Yourself). Cette grande rapidité rend l’écosystème des objets connectés très hétérogène et rend ainsi la reconnaissance et l’identification des objets compliquée. Une piste permettant l’identification des objets connectés consiste à s’intéresser à leur signature sonore. Pour cela, on capte à l’aide de microphones les émissions sonores de l’objet en fonctionnement et on extrait une signature sonore. Afin d’améliorer la sensibilité de la captation sonore tout en diminuant la taille et le coût, on peut envisager d’utiliser des microphones basés sur les technologies MEMS. En utilisant de tels microphones il sera possible de multiplier les sources de données.
Le projet consiste en la conception et la réalisation d’un système d’écoute embarquant plusieurs microphones MEMS. La plateforme comportera :
- une partie matérielle avec des microphones MEMS ;
- un protocole de synchronisation des mesures provenant des différents microphones ;
- une partie logicielle permettant de traiter les signaux acquis.
Des expérimentations basiques seront menées afin de valider le prototype et d’estimer les gains en termes de sensibilité notamment.
Cahier des charges
Objectif du projet
L’objectif de ce projet est de réaliser un prototype de système d’écoute de signature sonore à base de microphones MEMS permettant d’écouter un chargeur de smartphone, et pourra par la suite être étendu par d’autres systèmes, comme les microcontrôleurs, ou tout autre objet connecté. Nous travaillerons avec deux smartphones différents ainsi que leurs chargeurs respectifs, et notre système devra être capable de différencier les téléphones ainsi que de reconnaître quelques cas d’utilisations simples.
Historique
Ce projet sera le deuxième à avoir été réalisé sur cette thématique, où un premier projet avait été réalisé autour de cette thématique en 2019/2020 par l’étudiant en spécialité IMA5 Pierre Frison, celui-çi utilisant un simple microphone. Dans notre cas, nous utiliserons des microphones réalisés avec la technologie MEMS, et qui offrent donc la possibilité de réduire la taille du système, ainsi que de travailler avec plusieurs microphones afin de multiplier les sources et gagner en sensibilité.
Expression du besoin
Bête à corne

Diagramme Pieuvre

| Fonction | Intitulé | Flexibilité |
|---|---|---|
| FP1 | Permettre à l’utilisateur d’identifier les appareils connectés | |
| FC1 | Capter et reconnaître la signature sonore d’un appareil | Taux d'erreurs <= 10% |
| FC2 | Informer l’utilisateur | |
| FC3 | Fonctionner en environnement intérieur | |
| FC4 | S’alimenter par câble USB |
Diagramme FAST

Contraintes
Contraintes matérielles
Afin de réaliser un prototype ainsi que des mesures permettant de le valider, nous travaillerons avec du matériel qu’il nous à été fournis :
- 2 microcontrôleurs STM32-NUCLEO-F410RB
- 2 microcontrôleurs STM32-NUCLEO-F401RE
- 1 expansion numérique des microphones MEMS (Réf : X-NUCLEO-CCA02M2)
- 1 expansion analogique des microphones MEMS (Réf : X-NUCLEO-AMICAM1)
- 1 expansion 4 microphones MEMS numériques STEVAL-MIC001V1
- 1 expansion 4 microphones MEMS analogiques STEVAL-MIC004V1
- 2 smartphones avec leurs chargeurs
Contraintes logicielles
Afin de pouvoir programmer les cartes microcontrôleurs, nous aurons le choix de travailler sous l’une des deux plateformes suivantes:
- STM32Cube IDE
- Mbed OS
Contraintes humaines
Nous serons deux étudiants en cinquième année systèmes embarqués - systèmes communicants à travailler sur ce projet, encadrés par Monsieur Thomas Vantroys et Monsieur Alexandre Boé, professeurs du département systèmes embarqués.
Contraintes temporelles
Le projet commencera le 5 Septembre 2022 et se terminera le 23 Janvier 2023.
Nous utiliserons également les ressources disponibles au sein de Polytech’Lille ainsi qu’au Fabricarium.
Résultats attendus
Afin de nous assurer du fonctionnement et de la fiabilité de notre prototype, nous réaliserons différentes mesures sur nos smartphones personnels. Nous réaliserons une base de référence pour une dizaine de cas différents en prenant plusieurs mesures de chaque cas afin de mesurer un taux d’erreur sur les mesures.
Cahier des Spécifications
Etat de l'art
Ce projet sera le deuxième à avoir été réalisé sur cette thématique, où un premier projet avait été réalisé autour de cette thématique en 2019/2020 par l’étudiant en spécialité IMA5 Pierre Frison, celui-çi utilisant un simple microphone. Dans notre cas, nous utiliserons des microphones réalisés avec la technologie MEMS, et qui offrent donc la possibilité de réduire la taille du système, ainsi que de travailler avec plusieurs microphones afin de multiplier les sources et gagner en sensibilité.(Lien du wiki)
L’entreprise Wavely a réalisé un système d’écoute sonore permettant de détecter les dysfonctionnements sur des systèmes tels que la localisation d’une fuite de gaz. (Les Echos)
Une publication scientifique rédigée par Boris Defreville, Stéphane Bloquet, Guillaume Filippi et Christine Aujard présente une solution permettant d’identifier le différentes sources de bruit en milieu urbain afin de pouvoir prévoir par exemple l’impact d’une déviation de l’accès à un centre ville ou bien de connaître les niveaux de bruit générés par l’industrie. (Lien de la publication)
Démarche de réalisation du besoin
Afin de réaliser le besoin nous allons procéder par étapes en augmentant progressivement la complexité de notre prototype. A chaque étape nous modifierons le prototype sur les plans matériel et logiciel puis nous réaliserons une batterie de tests identique à chaque étape afin de pouvoir comparer les différents résultats et évaluer l’évolution des performances de notre prototype.
En premier lieu, nous allons nous assurer de la fonctionnalité des microphones et prendre en main leur programmation en enregistrant nos propres voix. Après cela, nous allons réaliser une version simple de notre système permettant d’écouter le système à étudier (nous allons prendre le cas des chargeurs des smartphones) avec un seul microphone MEMS. Ce système consistera en une boîte en bois dans laquelle sera placé le capteur ainsi que le système à écouter.
Il est envisageable par la suite d’utiliser dans nos études plusieurs microphones placés à l’intérieur de la boîte, ainsi que d’en ajouter un à l'extérieur dans le but de pouvoir compenser le bruit ambiant.
Pour la partie logicielle, nous allons utiliser les résultats obtenus que nous allons visualiser en utilisant un algorithme d’analyse en composantes principales (PCA). Après quoi nous allons utiliser un algorithme de segmentation du plan de visualisation afin d’associer à chaque cas une surface sur le plan.
Formalisme des résultats de mesures
Afin de ne pas nous perdre dans les nombreuses expérimentations que nous effectuerons tout au long du projet, il sera nécessaire d’adopter un formalisme dans les conditions d’expérimentation ainsi que dans la dénomination des fichiers comprenant nos résultats. Nous effectuerons des mesures avec deux smartphones différents (nos téléphones personnels) dans quatre conditions :
- Cas de base (batterie à 100%, aucune application ouverte).
- Batterie à 50%, aucune application ouverte.
- Une application ouverte, batterie à 100%
- Smartphone en veille, batterie à 100%, aucune application ouverte.
Dans chaque cas, le smartphone sera en mode avion afin de limiter l’influence des autres ondes.
Afin de ne pas se perdre dans les différentes expérimentations que nous allons mener, nous allons réaliser une arborescence de fichier telle que suit, où un répertoire sera créé pour chaque cas, chacun contenant un répertoire par téléphone. Pour chaque expérience plusieurs mesures seront effectuées, comprenant les fichiers de résultats.

Voici une légende des noms des répertoires utilisés dans notre schéma explicatif :
- Cbase = Le cas de base avec batterie à 100%, aucune application ouverte.
- C50 = Le cas avec batterie à 50%, aucune application ouverte.
- Co = Le cas avec une application ouverte et batterie à 100%
- Cv = Le cas avec smartphone en veille, batterie à 100%, aucune application ouverte.
- T_Logan et T_Ali = Téléphone sur lequel on fait l’expérience
- Expi = experience numéro i faite par le téléphone
Les fichiers seront nommés par concaténation des noms des répertoires en partant du plus général (ex. Cbase_Tlogan_E2_F1).
Diagramme de GANTT

Caractéristiques du produit
Le produit attendu est un système embarqué, basé sur des cartes microcontrôleur STM32F410RE, des expansions et des microphones MEMS analogiques (X-NUCLEO-AMICAM1) et numériques (X-NUCLEO-CCA02M2).
Nous souhaitons réaliser un prototype comportant plusieurs micros et ayant une certaine immunité au bruit extérieur. Cette immunité peut être obtenue en utilisant des matériaux insonorisant ou bien en récupérant le bruit extérieur afin de le compenser lors de l’analyse.
Ce prototype à pour but de différencier les systèmes embarqués ou bien leurs conditions de fonctionnement. Sa fiabilité sera déterminée en mesurant le taux d’erreur sur des chargeurs de téléphones portables dans plusieurs cas tel que vu précédemment. Des mesures sur d’autres systèmes embarqués sont envisageables mais cela reste à déterminer.
Les moyens consacrés
En plus du matériel électroniques fournis, tel que les microcontrôleurs, les expansions et les microphones, nous allons utiliser les outils de fabrication présents au Fabricarium de l’école, dans le but de construire une boîte dans laquelle vont être placés les composants de notre système (par découpage laser ou impression 3D).
Pour la partie logicielle nous travaillerons sous STM32Cube IDE pour la prise de mesure et nous programmerons les algorithmes de traitement et d’analyse de données en Python, en utilisant les modules svc du package sklearn.svm et pca du package sklearn.decomposition pour la visualisation et la segmentation des données.
Nous avons également la possibilité d’implémenter une solution à base de machine learning afin de faciliter l’apprentissage de nouveaux cas.
Réalisation du projet
Semaine 1 : 05/09/2022 - 09/09/2022
Durant la première semaine, nous avons rempli tout d'abord les parties de notre page Wiki en établissant la description du projet et du système, ainsi que le cahier des charges avec les tâches à effectuer.
Pour cela nous nous sommes renseignés en lisant des documentations trouvés sur internet, ainsi que les travaux effectuer par un ancien étudiant IMA sur un sujet qui ressemble celui la, ainsi que nous avons eu une première réunion avec nos encadrants; Monsieur Thomas Vantroys et Monsieur Alexandre Boé qui nous ont expliqué le but de ce projet, et nous ont fournit le matériel nécessaire pour la réalisation technique.
Semaine 2 : 19/09/2022 - 24/09/2022
Durant cette deuxième semaine, notre objectif était de comprendre le fonctionnement des expansions numériques et analogiques des microphones MEMS. Pour cela nous avons décidé d'utiliser le logiciel STM32CubeIDE, car il possède des compatibilités avec les expansions en possession. Pour cela, nous avons commencé au début d'apprendre et de comprendre le mode de fonctionnement de cet environnement en suivant des Tutorats trouvés sur Youtube.
Ensuite un nous avons testé pour la première fois l'expansion numérique des MEMS, où nous avons trouvé au début qu'il est indispensable d'utiliser X-Cube-MEMSMIC1 qui est un progiciel d'extension pour STM32Cube. Ce logiciel s'exécute sur le STM32 et comprend des pilotes et un middleware pour l'acquisition de données audio à partir de microphones numériques MEMS (MP34DT06J) et de microphones analogiques (MP23ABS1), et le streaming USB des signaux enregistrés.
Un test préliminaire, consistant à enregistrer nos voix personnelles a eu lieu, grâce au logiciel Audacity par l'expansion numérique, où le résultat est enregistré dans un fichier d'extension .aud3 .
Voici une capture du signal sonore :
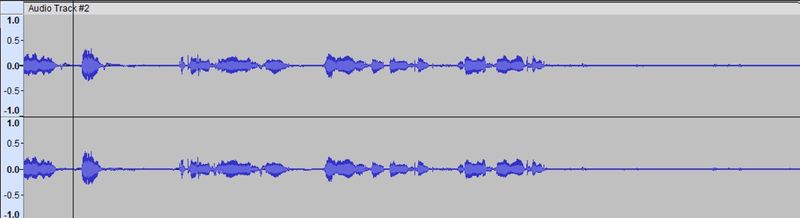

On observe la variation de l'amplitude du signal en fonction du temps.
Nous avons avons alors commencé à réflechir à l'automatisation de l'enregistrement sou des formats de compressions sans pertes utilisables. Nous avons choisi de travailler avec le format wave, où nous avons trouvé des modules sous Python permettant de traiter les données sous ce format.
Semaine 3 : 03/10/2022 - 07/10/2022
Lors de cette troisième semaine, nous avons travaillé sur l'acquisition des signaux provenant des microphones par programmation afin d'enregistrer le son récupéré au format wave. Nous avons choisi le format wave car il s'agit d'un format de compression sans perte restituant donc le son de manière fidèle. Nous avons récupéré et adapté un programme Python permettant de réaliser cette tâche et avons effectivement pus réaliser des enregistrements sonores ainsi.

Après cela nous nous sommes penché sur l'analyse de ces enregistrements. En effet, afin de pouvoir les analyser puis les comparer, il nous faut en retirer des informations qui leurs sont propres. Nous avons alors choisi de travailler avec leurs spectrogrammes nous offrant des informations de puissance sonore reçues pour chaque fréquence et en fonction du temps. Un script Python utilisant les packages scipy.io.wavfile et matplotlib.pyplot permet de lire un fichier d'extension wave et d'en afficher le spectrogramme.


Enfin nous avons effectué un premier enregistrement du bruit causé par nos chargeurs de smartphones alors que ceux-ci sont en charge. Nous ne disposons pas encore de moyen pour réduire l'influence du bruit extérieur (boite isolante, compensation du bruit), ces enregistrements ont donc été réalisés dans des conditions inadaptés et sont potentiellement impactés par le bruit environnemental.
Semaine 4 : 17/10/2022 - 21/10/2022
Lors de cette semaine, nous avons avancé sur le projet de la façon suivante:
Tout d’abord, nous avons réalisé des mesures en utilisant 2 smartphones différents avec leurs chargeurs, à un niveau de batterie de 50% et 100% respectivement, tous deux en veille. Pour chacun des deux cas, nous avons effectué plusieurs mesures afin d’obtenir un nombre suffisant d’échantillons pour de premières expérimentations.
Ensuite nous sommes partis sur l’apprentissage de la PCA, qui va nous permettre de représenter sur un plan en 2 dimensions les points représentant les signatures sonores des différents fichiers son :
- Premièrement, nous avons préparé des features pour la PCA en se basant sur le spectrogramme, en utilisant un nombre limité d'informations dans le but de comprendre le fonctionnement de l’algorithme de PCA et les résultats attendus. Comme nous nous y attendions, les résultats obtenus n'étaient pas utilisables du fait du trop peu d’informations utilisées, mais cela nous à permis de comprendre comment mettre en place l’algorithme afin d’obtenir ce que nous souhaitons.
- Deuxièmement, nous avons choisi de préparer les features via la méthode de la FFT du signal sonore, ensuite des tests ont été faits sur les fichiers de mesures. Nous avons obtenu un résultat qui paraît satisfaisant.
- Troisièmement, après discussion avec notre tuteur Mr Boe, qui nous a expliqué que la méthode de FFT faisait perdre les informations temporelles, nous sommes partis sur la mise en place d’un filtre passe-bas sur les données des spectrogrammes de chaque mesure afin de ne prendre que les informations aux fréquences inférieurs à 25 kHz. Les valeurs de puissances récupérées suite à ce filtrage, seront les features de l’algorithme de PCA. Ci-dessous les résultats obtenus.


Enfin, sur demande de Mr Boe, nous avons commencé à observer l'influence des paramètres de calcul du spectrogramme (taille de la fenêtre et overlap).
Nous avons également commencé à nous intéresser aux parties matérielles et logicielles afin de déterminer comment récupérer les informations de chaque microphones individuellement.
Semaine 5 : 07/11/2022 - 11/11/2022 et Semaine des vacances de Toussaint
Lors des vacances de Toussaint nous avons préparé notre rapport intermédiaire. Cela a également été l'occasion pour nous de faire un point sur l'avancé du projet, de définir clairement ce qui a été effectué et ce qu'il nous reste à faire. La semaine suivante nous nous sommes attelés à la compréhension du programme fourni par STMicroelectronics afin de savoir où et comment les données sont lues dans la mémoire avant d'être transférées par USB.
Semaine 6 : 21/11/2022 - 25/11/2022
Lors de ces semaines, nous avons mis en place un script en python permettant de récupérer les données de chaque microphones à part (créer deux fichiers Mono à partir d’un fichier Stéréo). Par méthode expérimentale, nous avons identifié quel microphone correspond à quel canal:
- Le canal 1 correspond au micro 1 et au micro Left.
- Le canal 2 correspond au micro 2 et au micro Right.
Après cela nous avons réalisé une arborescence de fichiers telle que décrite dans la partie spécification. Nous travaillons avec les cas suivant :
- Portable chargé à 100% en veille (Cas_100_v)
- Portable chargé à 100% avec une application ouverte (Cas_100_app)
- Portable chargé à 50% en veille (Cas_50_v)
- Portable chargé à 50% avec une application ouverte (Cas_50_app)
Dans tous les cas, le smartphone est en mode avion, et nous réalisons des mesures avec nos deux portables et leurs chargeurs respectifs. Nous obtenons donc 8 cas différents que nous essaierons de différencier.
Nous avons ensuite modifier nos différents scripts afin de parcourir cette arborescence de fichier et récupérer tous les fichiers .wav nous intéressant. Cette lecture prend également en compte tous fichiers ajoutés par la suite sans avoir à modifier le code. Nous avons également modifier le script permettant de séparer un fichier stéréo en deux fichiers mono afin que celui-ci s'exécute sur tous les fichiers présents dans l'arborescence.
Nous avons réalisé une série de mesures dans 4 des cas cité au dessus (5 mesures par cas) afin de pouvoir prendre en main les algorithmes qui nous permettront de différencier les cas :
- Portable de Ali chargé à 100% en veille (Cas_100_v)
- Portable de Ali chargé à 100% avec une application ouverte (Cas_100_app)
- Portable de Logan chargé à 50% en veille (Cas_50_v)
- Portable de Logan chargé à 50% avec une application ouverte (Cas_50_app)
En appliquant l'algorithme de PCA sur ces mesures (CH1 et CH2 séparément), nous obtenons ceci :

Nous pouvons voir que les quatre cas sont distinguables à l'œil nu.
Enfin, nous avons commencé à travailler avec l'algorithme de segmentation SVM de la librairie sklearn. Nous avons séparé nos données en une partie destinée à l'apprentissage (80% des données) et une partie à tester (20% des données). En réalisant les tests nous obtenons les résultats suivants :

Nous pouvons voir dans la colonne f1-score que la plupart des mesures sont bien classifiées, mais nous avons plusieurs erreurs. Cela est grandement dû au faible nombre de mesures que nous avons prises. Nous allons donc par la suite effectuer des mesures en plus grand nombre afin de vérifier de manière plus précise la fiabilité de notre méthode.
Semaine 7 : 05/12/2022 - 09/12/2022
Dans un premier temps, nous avons étudié l'influence du nombre de données transmises à l'algorithme de PCA par la décimation ainsi que l'influence de la durée des échantillons sur les résultats de la PCA. Le but ici est d'essayer de limiter le nombre de données utilisées tout en gardant des résultats convenables.
Pour observer l'influence du nombre de données, nous avons essayé de décimer les données après la FFT, avant de les transmettre à l'algorithme de PCA.





- Les points rouges correspondent au Téléphone de Ali chargé à 100% en mode veille.
- Les points violets correspondent au Téléphone de Ali chargé à 100% avec une application ouverte.
- Les points verts correspondent au Téléphone de Logan chargé à 50% en mode veille.
- Les points cyans correspondent au Téléphone de Logan chargé à 50% avec une application ouverte.
Nous pouvons ici voir que les deux portables sont toujours facilement différentiables. Peu n'importe le facteur de décimation, les deux cas de fonctionnement du smartphone de Ali restent distinguables, cependant les deux cas de fonctionnement du smartphone de Logan se mélangent.
La décimation dégrade le résultat, mais pour ces mesures son influence reste assez faible. Etant donné que nous n'avons que peu de mesures, et seulement pour 4 cas, nous nous sommes arrêtés là pour cette analyse.

Pour l'étude de l'influence de la durée des échantillons, nous avons réalisé un script Python permettant de séparer un fichier audio wave de 10s en 5 fichiers de 2s chacun. Nous avons exécuté ce script sur nos 20 échantillons, et avons ainsi utilisé comme jeu de données les 100 fichiers de 2s qui ont été générés. Nous avons réalisé leurs FFT avant de les confier à l'algorithme de PCA.
Nous pouvons voir encore une fois que les deux smartphones sont différentiables, et que les deux cas d'utilisation du téléphone de Ali sont distinguables. Cependant, en ayant plus de points nous nous rendons compte que les deux cas d'utilisation du téléphone de Logan sont confondus.
Par la suite, nous avons effectué une nouvelle série de 10 mesures pour chacun des cas déjà étudiés. Cependant les mesures de cette série se sont avérées être très différentes de notre première série. De plus, il était impossible de distinguer les différents cas pour cette série de mesure. Cela peut être dû à la différence des conditions de mesures entre 2 temps d'expérience (Endroit de la mesure, Bruit externe, ...).
Nous avons donc choisi de réaliser une boite acoustique qui nous permettra d'effectuer nos mesures dans de meilleures conditions. Une fois que celle-ci sera réalisée nous effectuerons une nouvelle série de mesures que nous utiliserons afin de mieux observer l'influence du nombre de données décimées et de la longueur des échantillons, ainsi que les limites de notre modèle.
Nous avons également pris en charge dans notre code la génération et l'attribution automatique des couleurs pour chaque cas, en prenant des points régulièrement espacés sur le segment "Hue" du domaine de couleur HSV. Cette attributions de couleurs n'est pas parfaite car on peut retrouver des couleurs assez proches et elle n'utilise pas les segments Saturation et Value mais permet de distribuer des couleurs à chaque cas de manière dynamique (si on ajoute des cas, leurs couleurs leur seront données automatiquement).
Semaine 8 et 9 : 12/12/2022 - 16/12/2022 et 02/01/2023 - 06/01/2023
Lors de cette semaine, nous avons terminé la fabrication de la boîte d'isolation acoustique, dans le but de réaliser des mesures dans un endroit bien isolé. Cette boîte a été réalisée grâce aux matériel fournit par nos tuteurs (mousse acoustique), et les ressources présentes aux fabricarium de Polytech.



Par la suite nous avons réalisé un nouveau jeu de mesures en écoutant l'appareil dans cette boite, dans les mêmes cas d'utilisation que précédemment.
- Smartphone chargé à 100% en veille (Cas_100_v)
- Smartphone chargé à 100% avec une application ouverte (Cas_100_app)
- Smartphone chargé à 50% en veille (Cas_50_v)
- Smartphone chargé à 50% avec une application ouverte (Cas_50_v)
Pour nos deux smartphones (Tali et Tlogan, toujours en mode avion, soit 8 cas différents.
Nous avons pris 10 mesures par cas, pour un total de 80 mesures. Cependant lorsque nous appliquons l'algorithme de PCA nous remarquons que les points ne sont pas répartis par cas mais ce mélangent, ce qui rendrait la différentiation ardue.
Nous avons donc essayé divers traitements des données afin d'améliorer nos résultats et de permettre un différentiation fiable par la suite, que nous consignerons dans la partie Résultats.
Résultats
Dans cette partie, nous allons vous présenté les résultats obtenus avec un nombre de mesures, considerés élevé par rapport aux dataset du début.
Dans cet dataset, nous avons environnement 80 mesures, pour les deux portables, et les cas différents.
En premier lieu, nous avons fourni à nos programmes de PCA, les 80 fichiers, d'où le resultat obtenu était le suivant :
On remarque que les résultats obtenus ne sont pas très satisfaisant, où nous n'arrivons pas à différencier les appareils, mais il est tout à fait possible de distinguer les cas de fonctionnement.
Ce résultat nous a poussé d'aller modifier notre chaîne du traitement du signal, pour améliorer les résultats.
Dans une deuxième tentative, nous nous sommes servis du cours du traitement du signal de 4A, où nous avons pensé qu'un effet de fenêtrage sur le signal a eu lieu, pour cela nous avons implémenté une fenêtre de Hamming, où la fenêtre de Hamming tend à "adoucir la transition" du signal sur les bords. IMAGE DE SIG AVEC FENETRE ICIIIII
Ensuite, nous avons pensé au fait de filtré les signaux de la FFT, selon un pourcentage, c'est-à-dire, que toute les puissances inférieurs à x% de la puissance maximale, sont virées, et on ne garde que ceux qui sont supérieures. Des tests ont été faites pour x=1%, x=2%, x=3% et voici les resultats obtenus :



Un autre essai consiste à ramener les valeurs de la FFT à sa valeur max, cela est fait dans le bloc de calcul de la FFT, qui nous donné ce résultats :

Pour ce cas, nous remarquons que ces resultats sont pas du tout correctes, où il est impossible de faire aucune distingution ni pour les cas de fonctionnement, ni pour les objets étudiés.
Documentation
Matériel
- Documentation de l'expansion numérique : Getting started with the X-NUCLEO-CCA02M2
- Microphones PDM : Interfacing PDM digital microphones
- Utilisation des microphones MEMS sur STM32 : Tutorial for MEMS microphones
- Datasheet des microphones MEMS numériques : MP34DT06J
Logiciel
- Conversion PDM vers PCM : STM32Cube PDM2PCM software library
- Progiciel X-CUBE-MEMSMIC1 : Getting started with X-CUBE-MEMSMIC1
Documents Rendus
- Cahier des charges : Fichier:P15 2022 2023 cahier des charges.pdf
- Cahier des spécifications :Fichier:P15 2022 2023 cahier des spécifiactions.pdf
- Rapport intermédiaire : Fichier:P15 2022 2023 Rapport Intermediaire.pdf
- Soutenance intermédiaire : Fichier:P15 2022 2023 Soutenance Intermediaire.pdf
- Rapport final : Fichier:P15 2022 2023 Rapport Final.pdf
- Soutenance finale : Fichier:P15 2022 2023 Soutenance Finale.pdf