IMA3/IMA4 2020/2022 P6 : Différence entre versions
(→Partie Machine learning) |
(→Version alternative du pré-processing) |
||
| (123 révisions intermédiaires par 4 utilisateurs non affichées) | |||
| Ligne 9 : | Ligne 9 : | ||
Pour écouter le réseau nous utilisons Wireshark, l'écoute génère un fichier avec l'extension .pcap que nous allons traiter en Python. Le fichier est .pcap est la liste des paquets écoutés. Avec python, nous allons analyser ces listes de paquets avec TensorFlow un outil open source d'apprentissage automatique et la bibliothèque Keras permettant d'interagir avec les algorithmes de langages d'apprentissage profond. L'objectif est d'analyser les différents paquets pour en identifier les comportements suspects. Cependant, nous devons définir ce qu'est un comportement suspect en analysant les différents protocoles wifi. | Pour écouter le réseau nous utilisons Wireshark, l'écoute génère un fichier avec l'extension .pcap que nous allons traiter en Python. Le fichier est .pcap est la liste des paquets écoutés. Avec python, nous allons analyser ces listes de paquets avec TensorFlow un outil open source d'apprentissage automatique et la bibliothèque Keras permettant d'interagir avec les algorithmes de langages d'apprentissage profond. L'objectif est d'analyser les différents paquets pour en identifier les comportements suspects. Cependant, nous devons définir ce qu'est un comportement suspect en analysant les différents protocoles wifi. | ||
| − | = | + | =Partie Réseau= |
| − | == | + | ==Théorie== |
La partie du réseau que nous allons étudier/analyser est la Wi-Fi. Nous nous pencherons donc sur la composition des trames Wi-Fi qui se basent sur le standard IEE 802.11. | La partie du réseau que nous allons étudier/analyser est la Wi-Fi. Nous nous pencherons donc sur la composition des trames Wi-Fi qui se basent sur le standard IEE 802.11. | ||
| Ligne 40 : | Ligne 40 : | ||
Aujourd'hui, beaucoup d'utilitaire sont développés afin de capturer des paquets réseau et les analyser. Les logiciels vont analyser les paquets afin de décrypter et ressortir les infos qu'ils transportent. Les logiciels comme Kismet et Wireshark permettent à un utilisateur de faire de la surveillance réseau manuellement. L'utilitaire Aircrack quant à lui permet de cracker des clés Wi-Fi en s'appuyant sur le mode moniteur de la carte réseau. Nous nous appuierons donc sur ces logiciels afin de réaliser notre projet. Les fichiers de capture de paquets sont sous l'extension pcap et sont lisibles par des analyseurs de réseau. | Aujourd'hui, beaucoup d'utilitaire sont développés afin de capturer des paquets réseau et les analyser. Les logiciels vont analyser les paquets afin de décrypter et ressortir les infos qu'ils transportent. Les logiciels comme Kismet et Wireshark permettent à un utilisateur de faire de la surveillance réseau manuellement. L'utilitaire Aircrack quant à lui permet de cracker des clés Wi-Fi en s'appuyant sur le mode moniteur de la carte réseau. Nous nous appuierons donc sur ces logiciels afin de réaliser notre projet. Les fichiers de capture de paquets sont sous l'extension pcap et sont lisibles par des analyseurs de réseau. | ||
| − | = | + | ==Wireshark== |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
Nous souhaitons récupérer les données importantes des trames Wi-Fi afin de les analyser par la suite à l'aide de notre algorithme de machine learning. Pour cela nous allons réaliser cette partie en deux temps. Premièrement, la capture des paquets. Puis l'extraction des données en vue de l'analyse. | Nous souhaitons récupérer les données importantes des trames Wi-Fi afin de les analyser par la suite à l'aide de notre algorithme de machine learning. Pour cela nous allons réaliser cette partie en deux temps. Premièrement, la capture des paquets. Puis l'extraction des données en vue de l'analyse. | ||
| Ligne 61 : | Ligne 53 : | ||
Liste des commandes utilisées : | Liste des commandes utilisées : | ||
| − | + | -f : Permet de capturer seulement certain types de paquets. Par exemple -f arp permet de capturer seulement les paquets ARP | |
| − | : Permet de capturer seulement certain types de paquets. Par exemple -f arp permet de capturer seulement les paquets ARP | + | -I : Met la carte en mode routeur et nous permet de capturer tous les paquets 802.11 circulant sur le réseau |
| − | + | -P : Permet d'obtenir un fichier d'extension pcap à la place d'un fichier pcapng. | |
| − | + | -a duration:time : arrête la capture après un temps "time" en secondes. exemple dumpcap -a duration:30 fait une capture de paquets pendant 30 secondes. | |
| − | : Met la carte en mode routeur et nous permet de capturer tous les paquets 802.11 circulant sur le réseau | ||
| − | |||
| − | |||
| − | : Permet d'obtenir un fichier d'extension pcap à la place d'un fichier pcapng. | ||
| − | |||
| − | |||
| − | : arrête la capture après un temps "time" en secondes. exemple dumpcap -a duration:30 fait une capture de paquets pendant 30 secondes. | ||
Nous sommes donc arrivés à une capture par le biais de la commande suivante : | Nous sommes donc arrivés à une capture par le biais de la commande suivante : | ||
| − | + | dumpcap -I -P -a duration:60 -f "type mgt or type ctl or type data" | |
Cette commande nous permet de capturer tous les paquets 802.11 en passant notre carte en mode moniteur pendant une durée de 60 secondes. Le filtre ''-f'' permet d'ignorer les paquets malformés ou corrompus. En pré-analysant les différents trames Wifi, nous serons capable de récupérer les informations nécessaires. | Cette commande nous permet de capturer tous les paquets 802.11 en passant notre carte en mode moniteur pendant une durée de 60 secondes. Le filtre ''-f'' permet d'ignorer les paquets malformés ou corrompus. En pré-analysant les différents trames Wifi, nous serons capable de récupérer les informations nécessaires. | ||
| Ligne 89 : | Ligne 74 : | ||
Format de la commande : | Format de la commande : | ||
| − | + | tshark -r fichieràlire -T fields -e nomduchampàrécupérer > fichier.csv | |
| + | |||
| + | ==aireplay-ng== | ||
| + | |||
| + | Aireplay-ng est un outil de de la suite aircrack-ng. La suite de logiciel permet la surveillance de réseaux sans fil mais son utilisation principale est de casser les clés WEP et WPA des réseaux Wi-Fi mais ce n'est pas le but du projet, c'est pourquoi nous allons étudier aireplay-ng. Cet outil permet d'injecter des paquets 802.11 sur le réseau. Aircrack-ng s'utilise avec des lignes de commandes dans le terminal. | ||
| + | Dans les lignes de commandes, il existe un paramètre permettant de générer des paquets pour certains types d'injections. | ||
| + | Les types d'injection par défaut sont : | ||
| + | |||
| + | -désauthentification | ||
| + | |||
| + | -fausse authentification | ||
| + | |||
| + | -reinjection selective de paquet (permet de choisir un paquet particulier pour être injecter un grand nombre de fois sur le réseau) | ||
| + | |||
| + | - répétition de requête ARP | ||
| + | |||
| + | - Korek chopchop (permet le déchiffrement de paquets sans avoir la clé de cryptage WEP) | ||
| + | |||
| + | - attaque par fragmentation (exploite le principe de fragmentation des paquets IP) | ||
| + | |||
| + | - Cafe-latte (obtention de la clé WEP) | ||
| + | |||
| + | - attaque par fragmentation orienté client | ||
| + | |||
| + | - WPA Migration Mode (modifie le WPA migration mode qui est un paramètre des points d'accès Cisco) | ||
| + | |||
| + | - Test d'injection (simple test pour voir si notre carte réseau est capable d'injecter des paquets | ||
| + | |||
| + | Ces types d'injection ou d'attaques s'utilisent en ajoutant "-X" avec X le numéro du paramètre allant de 0 à 9 selon la liste précédente. | ||
| + | |||
| + | Dans un objectif de surveillance du réseau de l'école, les attaques concernant le protocole de sécurité WPE ne seront pas étudiés, ce protocole n'est plus utilisé depuis de nombreuses années. | ||
| + | |||
| + | Les commandes s'utilisent de la manière suivante | ||
| + | aireplay-ng <options> <replay interface> | ||
| + | |||
| + | En effet, il existe différentes options de filtres permettant de personnaliser les paquets avec notre réseau. Nous pouvons choisir l'adresse mac du point d'accès, l'adresse mac de destination et de source , la taille minimale et ou maximale d'un paquet, et d'autres options agissant sur la trame de contrôle. Ces paramètres sont à utiliser pour la simulation d'attaque. | ||
| + | Voici quelques exemples : | ||
| + | -b bssid : MAC address, Access Point | ||
| + | -d dmac : MAC address, Destination | ||
| + | -s smac : MAC address, Source | ||
| + | -m len : minimum packet length | ||
| + | -u type : frame control, type field | ||
| + | |||
| + | Il existe aussi des options pour la répétition de paquets comme le nombre de paquets envoyés par secondes, le mot de la frame de control, la fixation d'un point d'accès, d'une adresse de destination ou de source, paramétrage de l'IP source ou destination. Ce sont les paramètres que nous retenons pour le moment. Ces paramètres sont à utiliser pour l'injection de paquets sans simulation d'attaque | ||
| + | -x nombre de paquets par seconde | ||
| + | -a bssid : set Access Point MAC address | ||
| + | -c dmac : set Destination MAC address | ||
| + | -h smac : set Source MAC address | ||
| + | -k IP : set destination IP in fragments | ||
| + | -l IP : set source IP in fragments | ||
| + | |||
| + | Ainsi, l'objectif d'aircrack dans le projet est de simuler des attaques sur le réseau pour que nous puissions les identifier et les ajouter à notre set de données pour le modèle de machine learning. | ||
| + | |||
| + | Finalement cette solution n'a pas été retenue pour l'injection de paquets. Ce n'était pas le plus simple pour injecter des paquets sur le réseau et en même temps le simuler et en même temps capturer le réseau. | ||
| + | |||
| + | ==Edition de fichier pcap== | ||
| + | |||
| + | Pour faire notre jeu de données, nous avons eu besoin de manipuler des fichiers pcap. Ce traitement peut se faire rapidement avec l'utilitaire '''editcap''' ou encore '''mergecap'''. Ces utilitaires sont installés automatiquement quand nous téléchargeons Wireshark. | ||
| + | Ces outils fonctionnent en ligne de commande avec différentes options. | ||
| + | |||
| + | Quelques exemples options d''''editpcap''' : | ||
| + | -A temps à partir duquel les données sont sélectionnées | ||
| + | -B temps jusqu'auquel les données sont séléctionnées | ||
| + | -c nombre de paquets par fichiers | ||
| + | -i nombre de secondes contenue dans un fichier | ||
| + | |||
| + | Quelques exemples options de '''mergecap''' : | ||
| + | -a concatène plutôt que merge les fichiers | ||
| + | -w permet de choisir/créer le fichier de sortie | ||
| + | |||
| + | ==Argus== | ||
| + | |||
| + | A la différence de Tshark et tcpdump, Argus ne réalise pas une copie complète du traffic, Argus se concentre sur la "Session Data" (trames TCP ou UDP). Argus décrit les conversations réseaux se concentrant sur qui parle avec qui, quand et combien d'informations ont été échangés. Cependant, nous ne pouvons pas observer des requêtes ARP par exemple, ce qui peut être dérengeant pour le projet. | ||
| + | |||
| + | ==Simulation du trafic réseau sain== | ||
| + | |||
| + | Pour simuler le trafic sans attaque, nous avons utiliser différents outils. | ||
| + | |||
| + | Tout d'abord le plus simple est de capturer pendant assez longtemps nos recherches sur le navigateur. Nous avons aussi fait un script pour simuler du trafic sur certains sites internet et avoir un nombre de requêtes important en peu de temps. Le script suivant permet via un fichier texte contenant l'adresse de 10 sites avec un site par ligne de récupérer de manière aléatoire une adresse et d'effectuer une requête via la commande '''curl'''. La commande retourne le code html de la page. Afin de ne pas polluer la sortie standard, le code est retourné dans un fichier texte temporaire. | ||
| + | |||
| + | #!/bin/bash | ||
| + | for (( i=0; i <= 100; i++ )); | ||
| + | do | ||
| + | site=$(sed -n $((1 + RANDOM % 10))p trafic.txt); | ||
| + | curl $site > /tmp/simutrafic.txt | ||
| + | sleep 5 | ||
| + | done | ||
| + | |||
| + | Certes se sont toujours les mêmes sites internets, mais dans le contexte du projet nous ne regardons pas le contenu de la requête mais son type (UDP,ARP,TCP). | ||
| − | ==Partie Machine learning == | + | ==Simulation d'une attaque sur un réseau== |
| + | |||
| + | Nous nous sommes axés sur la détection des attaques de type ARP (saturation du réseau par émission de requêtes ARP, ARP-spoofing…). Réaliser des attaques avec ARP nécessite souvent d'émettre un grand nombre de paquets de ce type. Ainsi, et afin d’entraîner notre modèle de machine learning, nous avons dû réaliser des émissions de paquets ARP en grand nombre pour simuler des attaques. Ces attaques ont en parallèle été enregistrées à l’aide de notre sniffer pour créer un jeu de données “infectées” utilisable par notre modèle. | ||
| + | |||
| + | Pour réaliser les émissions de requêtes, nous nous sommes aidé de la bibliothèque python scapy. Cette dernière nous permet de fabriquer nos propres paquets et de les émettre sur le réseau ciblé. | ||
| + | Nous formons et envoyons donc nos paquets à l’aide du code suivant : | ||
| + | |||
| + | [[Fichier:Codeattaque.png|600px|center|thumb|Code python pour simuler une attaque type ARP-Poisoning]] | ||
| + | |||
| + | Avec ce programme nous pouvons choisir d’envoyer des requêtes ARP en boucle ou envoyer des réponses spontanées pour détourner les paquets de la cible (ARP poisoning), notre but étant d'augmenter drastiquement le nombre de paquet ARP par rapport à un trafic classique. | ||
| + | |||
| + | |||
| + | Voici ce que donne une attaque : | ||
| + | |||
| + | [[Fichier:Arp.png|600px|center|thumb|Paquets ARP sur le réseau pendant l'attaque, on vise l'adresse IP 192.168.43.31]] | ||
| + | [[Fichier:Spoof.png|600px|center|thumb|Paquets détournés qui étaient sensés être à destination du véritable détenteur de l'adresse IP 192.168.43.31]] | ||
| + | |||
| + | En combinant cette simulation d’attaques avec la simulation de trafic, nous obtenons les jeux de données nécessaires à l’entraînement de notre modèle de machine learning. | ||
| + | |||
| + | ==Contraintes rencontrées pour la capture == | ||
| + | |||
| + | Tout d'abord, nous avons essayé de capturer simplement le trafic du réseau, nous avons rapidement vu que tous les données qui circulaient étaient cryptées donc il est impossible de capturer le réseau simplement de cette manière pour l'analyser. Nous avons ensuite voulu faire une capture sur un routeur pour pouvoir voir tout le réseau décrypté. Cette solution auraient été possible en faisant un port miroir sur un routeur, cette technique consiste à envoyer sur un port du routeur la copie de tous les paquets qui circulent. Cependant ce n'est pas réalisable à Polytech. D'un point de vue de la confidentialité, ils auraient fallu traiter tous les paquets pour vérifier qu'aucune donnée personnelle ne circule et nous n'avons pas accès aux routeurs. Nous avons ensuite essayer de faire une capture sur les machines ZABETH fonctionnant en Ethernet sauf que les ZABETH sont sur un réseau commuté, c'est à dire que les paquets sont dirigés seulement vers la machine concerné. Finalement, nous sommes revenus à la solution la plus simple qui est de capturer sur nos ordinateurs pendant les séances de projet comme ca nous avons les paquets décryptées que notre carte réseau traite. Après pour avoir un fichier de capture plus long nous pouvons les assembler pour avoir une version plus complète de l'activité du réseau. Ainsi, contrairement à la consigne initial, nous ne capturons pas directement des paquets wifi, nous capturons des paquets sous la forme Ethernet mais qui ont été envoyé par wifi. | ||
| + | |||
| + | =Partie Machine learning = | ||
| + | |||
| + | ==Etude de cas 1 : Classement d'images== | ||
| + | |||
| + | Les premiers algorithmes de machine learning que nous avons étudiés sont des algorithmes de classification d'images. Nous avons utilisé les jeux de données (appelés Dataset) connu MNIST et Fashion MNIST afin de mettre en place, tester et surtout comprendre le fonctionnement d'un algorithme de machine learning. Le premier, MNIST, contient des images de chiffre manuscrit, le but de l'algorithme est donc de détecter de quel chiffre il s'agit sur chaque image. Le second, sur lequel nous allons nous attarder afin d'expliquer le fonctionnement d'un réseau de neurones est Fashion MNIST, qui regroupe des images de vêtements. L'algorithme doit alors être capable de classer ces vêtements par type. | ||
| + | |||
| + | ===Exploitation du jeu de données=== | ||
| + | |||
| + | Le jeu de données que nous avons principalement utilisé est le Fashion MNIST. Ce dataset contient 60000 images d'entrainement et 10000 images de test. Ces images représentent des vêtements au format 28x28 pixels. Ces vêtements sont de différents type : T-shirt, Pantalon, Pull, Robe, Manteau, Sandale, La chemise, Baskets, Sac ou Bottine. | ||
| + | Les 60000 images forment un jeu de données d'entrainement qui va être utilisé par le programme pour apprendre à reconnaitre les vêtements en les comparant. Le jeu de test de 10000 images va quant à lui permettre d'évaluer la précision du réseau de neurones après son apprentissage. | ||
| + | |||
| + | Ces données sont charger dans des tableaux numpy pour être utilisés par le réseau : | ||
| + | fashion_mnist = tf.keras.datasets.fashion_mnist | ||
| + | (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() | ||
| + | |||
| + | Chaque élément des tableaux train_images et test_images sont des tableaux de 28x28 contenant les pixels de l'image et les éléments des tableaux train_labels et test_labels sont des nombre entier représentant les types de vétements : 0 T-shirt, 1 Pantalon, 2 Pull ... | ||
| + | |||
| + | On peut observer cela avec : | ||
| + | > train_images.shape() | ||
| + | (60000, 28, 28) | ||
| + | |||
| + | ===Pré-traitement=== | ||
| + | |||
| + | Maintenant que nos données sont chargées, il faut les prétraiter afin qu'elles soient utilisables et interprétables par le réseau de neurones. Dans les tableaux précédemment créés, | ||
| + | chaque pixel a une valeur de 0 à 255, représentant son intensité. Pour que ces données soient compréhensibles par le réseau, il faut qu'elles soient comprises dans l'intervalle 0 et 1. | ||
| + | On ajuste donc les valeurs : | ||
| + | train_images = train_images / 255.0 | ||
| + | test_images = test_images / 255.0 | ||
| + | |||
| + | Nous sommes désormais prêt à construire notre modèle. | ||
| + | |||
| + | ===Construction du modéle=== | ||
| + | |||
| + | Un réseau de neurones fonctionne en couches superposées qui communiquent entre elles et qui ont des paramètres qui s'apprennent durant la formation. Ici nous utilisons un modèle séquentiel, qui est une pile linéaire de couches de neurones (appelés nœuds) | ||
| + | |||
| + | Voici la création de notre modèle : | ||
| + | model = tf.keras.Sequential([ | ||
| + | tf.keras.layers.Flatten(input_shape=(28, 28)), | ||
| + | tf.keras.layers.Dense(128, activation='relu'), | ||
| + | tf.keras.layers.Dense(10) | ||
| + | ]) | ||
| + | |||
| + | La première couche tf.keras.layers.Flatten permet de linéariser nos images en transformant nos tableaux 2 dimensions en tableaux 1 dimension. | ||
| + | Les deux couches suivantes créées par tf.keras.layers.Dense comportent respectivement 128 et 10 nœuds. La dernière couche, de 10 nœuds, contient les scores correspondants aux 10 types de vêtements. | ||
| + | |||
| + | On utilise ensuite model.compile pour compiler notre modèle | ||
| + | |||
| + | ===Entrainement du modèle=== | ||
| + | |||
| + | On est ensuite prêt à entrainer le modèle : | ||
| + | |||
| + | model.fit(train_images, train_labels, epochs=10) | ||
| + | |||
| + | Le modèle s'entraine et augmente en précision à chaque nouvel entrainement | ||
| + | On peut tester sa précision avec un jeu de test : | ||
| + | |||
| + | test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) | ||
| + | |||
| + | On peut aussi utiliser des prédictions que l'on vérifie avec les jeux de test pour évaluer la fiabilité du résultat. | ||
| + | |||
| + | ===Vérification et test du modèle=== | ||
| + | |||
| + | Notre modèle est désormais prêt et on peut l'utiliser en lui fournissant une image. Pour cela, on prend une image au hasard du jeu de test, ici un Pull (associé à 2) | ||
| + | |||
| + | img = test_images[1] | ||
| + | img = (np.expand_dims(img,0)) | ||
| + | predictions_single = probability_model.predict(img) | ||
| + | print(predictions_single) | ||
| + | |||
| + | On obtient la probabilité que l'image a d'être chaque type : | ||
| + | |||
| + | [8.8914348e-05 1.3264636e-13 [[9.9108773e-01]] 1.2658383e-10 8.1463791e-03 1.6905785e-08 6.7695131e-04 2.7492119e-17 5.1699739e-10 7.1339325e-17] | ||
| + | |||
| + | On remarque que la probabilité 2 est beaucoup plus élevé, le modèle prédit donc un Pull, ce qui est le cas | ||
| + | |||
| + | |||
| + | Cette partie étude de différents réseaux de neurones, tel que celui ci, nous a grandement aidé à comprendre l'enjeu et le fonctionnement des algorithmes de machine learning. Ces connaissances nous permettent désormais de mieux comprendre comment mettre en place notre réseau de neurones pour qu'il soit efficace à notre projet. | ||
| + | |||
| + | ==Etude de cas 2 : Une détection d'intrusion== | ||
Notre projet consiste à surveiller le réseau et les utilisateurs de ce réseau. La question qui se pose est alors la suivante : comment surveiller et analyser les milliers de données qui transitent sur ce réseau tous les jours ? Comment reconnaître un comportement malveillant ? C'est alors là que le machine learning devient intéressant. En effet,la détection d'un comportement malveillant revient à chercher une aiguille dans une botte de foin. Mais les algorithmes de Machine Learning permettent de traiter efficacement d'immenses quantités de données. | Notre projet consiste à surveiller le réseau et les utilisateurs de ce réseau. La question qui se pose est alors la suivante : comment surveiller et analyser les milliers de données qui transitent sur ce réseau tous les jours ? Comment reconnaître un comportement malveillant ? C'est alors là que le machine learning devient intéressant. En effet,la détection d'un comportement malveillant revient à chercher une aiguille dans une botte de foin. Mais les algorithmes de Machine Learning permettent de traiter efficacement d'immenses quantités de données. | ||
| Ligne 99 : | Ligne 273 : | ||
Les algorithmes de Machine Learning reposent sur des réseaux de neurones convultionnels (CNN). Ces derniers sont composés de couches de neurones où chaque neurone est relié à tous les neurones de la couche précédente. En python, avec la commande "model.add" nous pouvons ajouter les couches nécessaires à notre réseau en décrivant chaque couche avec différents paramètres. | Les algorithmes de Machine Learning reposent sur des réseaux de neurones convultionnels (CNN). Ces derniers sont composés de couches de neurones où chaque neurone est relié à tous les neurones de la couche précédente. En python, avec la commande "model.add" nous pouvons ajouter les couches nécessaires à notre réseau en décrivant chaque couche avec différents paramètres. | ||
| − | Pour notre projet, nous | + | Pour notre projet, nous allons devoir utiliser le Deep Learning. Le Deep Learning est une forme spécifique de Machine Learning où des couches cachées sont présentes entre les différentes couches de neurones. Il est préférable d'utiliser le Deep Leraning pour deux raisons : |
| − | + | - Notre algorithme se forme tout seul, nous avons juste à lui fournir des données pour s'entraîner | |
| − | + | - Le Deep Learning est plus efficace que le Machine Learning grâce à ses réseaux de neurones profonds | |
| − | ===Paramètres | + | ===Paramètres permettant la détection d'intrusions=== |
| − | + | Différents paramètres sélectionnés au préalable permettent de surveiller le réseau. Ces paramètres constituent une couche d'entrée du réseau de neurones. La couche de sortie nous donne la classification des comportements malveillants. Il est très important de choisir les bons paramètres pour que notre modèle soit biaisé par de fausses informations. Les paramètres extraits du réseau sont les suivants : | |
- la durée totale de l'enregistrement | - la durée totale de l'enregistrement | ||
| Ligne 120 : | Ligne 294 : | ||
- Moyenne de la taille des paquets de flux transmis par l'adresse IP source | - Moyenne de la taille des paquets de flux transmis par l'adresse IP source | ||
- Moyenne de la taille des paquets de flux transmis par l'adresse IP destination | - Moyenne de la taille des paquets de flux transmis par l'adresse IP destination | ||
| − | |||
| − | |||
===Réalisation de l'algorithme=== | ===Réalisation de l'algorithme=== | ||
| − | Pour créer | + | Pour créer l'algorithme de Deep Learning maintenant bien défini, il est conseillé d'utiliser Python. Ainsi, il est possible d'utiliser deux bibliothèques écrites en Python particulièrement utiles pour créer notre algorithme : Tensorflow et Keras. |
Tensorflow est un outil open source d'apprentissage automoatique. C'est un outil très utilisé dans le domaine de l'intelligence artificielle et plus particulièrement de l'apprentissage machine. | Tensorflow est un outil open source d'apprentissage automoatique. C'est un outil très utilisé dans le domaine de l'intelligence artificielle et plus particulièrement de l'apprentissage machine. | ||
| Ligne 131 : | Ligne 303 : | ||
Keras est quant à lui permet d'interagir avec les algorithmes de réseaux de neurones profonds et d'apprentissage automatique comme Tensorflow cité précedemment. | Keras est quant à lui permet d'interagir avec les algorithmes de réseaux de neurones profonds et d'apprentissage automatique comme Tensorflow cité précedemment. | ||
| − | La combinaison de ces deux bilbiothèques | + | La combinaison de ces deux bilbiothèques permet de créer notre algorithme de Deep Learning. |
| + | |||
| + | ===Fonctionnement de l'algorithme=== | ||
| + | |||
| + | Un premier programme training-set permet de créer le modèle séquentiel avec plusieurs entrées et une seule sortie. L'utilisation de Convolution (Conv2D) et ReLU permettent des réduire la taille des données (filtre). L'utilisation de MaxPooling permet elle d'échantillonner les données pour diminuer leur dimension. Nous diminuons ainsi les données jusqu'à obtenir une seule sortie. | ||
| + | |||
| + | Il nous faut ensuite prétraiter les données. Pour cela on isole les données qui nous intéressent puis on les normalise pour obtenir un jeu de données compréhensible par notre modèle. | ||
| + | |||
| + | Pour créer notre jeu de données initiale, nous allons faire une écoute réseau sur une durées assez importante et pendant cette période simuler des attaques avec l'outil aireplay-ng pour que les paquets malveillants soit capturés. Une fois tous les paquets capturés, nous devrons identifiés nous même lesquels sont malveillants pour que l'algorithme puisse par la suite comprendre et établir un modèle d'un comportement malveillant sur le réseau. | ||
| + | |||
| + | |||
| + | Nous pouvons ensuite générer notre modèle séquentiel et l'entraîner avec nos données pour avoir un programme opérationnel. Une fois opérationnel, nous pouvons enregistrer ce modèle en format Keras H5 ou sous forme d'un fichier JSON. | ||
| + | |||
| + | ==Création de notre modèle== | ||
| + | |||
| + | De notre côté, nous cherchons à réaliser du net monitoring, nous ne devons pas écouter seulement ce qui arrive sur notre machine mais nous devons aussi écouter ce qu'il se passe sur les machines environnantes. | ||
| + | |||
| + | Dans un premier temps, nous allons devoir créer notre modèle séquentiel. Sa taille et le nombre de couches variera en fonction du nombre de paramètres retenus. | ||
| + | |||
| + | Afin de créer nos Dataset utiles à l'apprentissage et l'entraînement de notre modèle, nous devrons simuler quelques attaques sélectionnées au préalable avec Aircrack. Ainsi nous pourrons récupérer certains paquets en sachant qu'ils sont suspects pour créer notre Dataset. | ||
| + | |||
| + | Une fois notre modèle entraîner, nous pourrons l'enregistrer sous forme d'un fichier Keras H5. Sinon, nous avons toujours l'option d'enregistrer notre modèle sous la forme d'un fichier JSON. | ||
| + | |||
| + | Nous pouvons ensuite lancer l'écoute réseau en arrière plan. Durant l'écoute, nous allons extraire les paramètres sélectionnés dans fichier log. Ainsi, pendant que le fichier continue de se remplir, notre modèle séquentiel pourra réaliser l'étude des paramètres pour essayer de détecter des comportements malveillants. En cas d'attaque, nous devrons créer une alerte, cela se fera surement à l'aide d'un second programme python. | ||
| + | |||
| + | ===Révision du projet=== | ||
| + | |||
| + | Nous avons décidé de nous concentrer sur les attaques à base d'injection ARP comme par exemple l'attaque Man In The Middle. En effet, cette attaque est composée de deux étapes : l'usurpation ARP et l'empoisonnement ARP. | ||
| + | |||
| + | L'usurpation ARP est une attque où un pirate envoie de faux paquets ARP reliant l'adresse MAC d'un attaquant à l'adresse IP d'un ordinateur déjà sur le LAN. | ||
| + | |||
| + | L'empoisonnement ARP, après une usurpation réussie, permet au pirate de modifier la table ARP de sa victime afin de falsifier les correspondances entre adresses MAC et IP. Ainsi, le pirate a accès à tout le traffic envoyé au réseau compromis sans même que la victime soit au courant. | ||
| + | |||
| + | Une fois installé, le pirate peut donc examiner tout le trafic envoyé au réseau avant que la victime le reçoive, il peut donc refuser d'acheminer le trafic s'il le souhaite. Il peut aussi modifier les informations envoyées avant que la victime les reçoive. | ||
| + | |||
| + | Ces attaques Man-in-the-middle compromettent la confidentialité, elles sont l'unes des cybermenaces les plus redoutables et dangereuses. C'est pourquoi nous avons décidé de nous concentrer sur ce type d'attaque. | ||
| + | |||
| + | Pour cela, nous allons observer le pourcentage de paquets ARP, de paquets UDP et de paquets TCP sur les 60 dernières secondes. Nous allons simuler des injections ARP pour créer des paquets malveillants. Ces paquets serviront à l'apprentissage de notre modèle de deep learning. | ||
| + | |||
| + | ===Architecture de notre réseau de neurones=== | ||
| + | |||
| + | L'architecture de notre réseau de neurones convolutionnel nous a posé quelques problèmes puisqu'à ce jour, il est diffcile de déterminer une architecture idéale. En effet, nous avons vu plusieurs projets qui testaient différentes architectures "à l'aveugle" pour regarder laquelle était la meilleure. De plus, chaque projet nécessite une architecture propre à elle. Cepedant, nous avons trouvé une thèse (renseignée en bibliographie) sur la détection d'attaque ARP à l'aide de deep learning. | ||
| + | |||
| + | Après une sélection simple des paramètres, différentes architectures ont été testées pour voir quelle était la plus efficace. Il en est ressorti de cette thèse qu'une architecture avec 3 neurones sur la couche d'entrée, une couche cachée comportant 3 neurones et 1 neurone sur la couche de sortie était l'architecture la plus efficace. Les paramètres sélectionnés sont les suivants : pourcentage de paquets ARP, TCP et UDP sur la dernière minute. | ||
| + | |||
| + | En se basant sur cette thèse, nous avons crée un réseau de neurones convolutionnels semblable en essayant d'enchaîner au mieux les MaxPooling et les Conv2D. Nous en sommes arrivés au code suivant : | ||
| + | |||
| + | def generate_cnn_model(shape): | ||
| + | model = Sequential() | ||
| + | model.add(Conv2D(32, (3, 1), activation='relu', input_shape = (3,1,1))) | ||
| + | model.add(Conv2D(32, (3, 1), activation='relu',padding="same")) | ||
| + | model.add(MaxPooling2D(pool_size=(2, 2),padding="same")) | ||
| + | model.add(Conv2D(64, (3, 1), activation='relu',padding="same")) | ||
| + | model.add(Conv2D(64, (3, 1), activation='relu', padding="same")) | ||
| + | model.add(Conv2D(64, (3, 1), activation='relu', padding="same")) | ||
| + | model.add(MaxPooling2D(pool_size=(2, 2),padding="same")) | ||
| + | model.add(Conv2D(128, (3, 1), activation='relu', padding="same")) | ||
| + | model.add(Conv2D(128, (3, 1), activation='relu', padding="same")) | ||
| + | model.add(Conv2D(128, (3, 1), activation='relu', padding="same")) | ||
| + | model.add(MaxPooling2D(pool_size=(2, 2),padding="same")) | ||
| + | model.add(Flatten()) | ||
| + | model.add(Dense(1, kernel_initializer='normal', activation='relu')) | ||
| + | model.add(Dropout(0.5)) | ||
| + | model.add(Dense(1, kernel_initializer='normal', | ||
| + | activation='relu', name='output')) | ||
| + | model.add(Dense(1, kernel_initializer='normal', activation='softmax')) | ||
| + | return model | ||
| + | |||
| + | ===Création de notre dataset=== | ||
| + | ===Phase de pré-processing=== | ||
| + | |||
| + | Les données que nous récupérons sont des données brutes (des paquets réseau). Nous devons donc réaliser une phase de pré-processing pour récupérer des données utilisables. Ces données utilisables sont dans notre cas le pourcentage de paquets TCP, UDP et ARP sur les 60 dernières secondes. Pour chacun des deux datasets, nous allons parcourir le fichier ligne par ligne. Pour chacune des lignes, nous récupérons les paquets des 60 dernières secondes et nous identifions la nature de chacun des paquets. Après l'identification, nous comptons le nombre de paquets de chaque type sur la dernière minute, nous pouvons ainsi calculer nos pourcentages : | ||
| + | |||
| + | # On parcourt le 1er dataset "classique" | ||
| + | for i in range(0,len(reader)): | ||
| + | for j in range(i,0,-1): | ||
| + | if reader[j].time > reader[i].time - 60: | ||
| + | if reader[j].haslayer(TCP): | ||
| + | compteur_tcp += 1 | ||
| + | if reader[j].haslayer(UDP): | ||
| + | compteur_udp += 1 | ||
| + | if reader[j].haslayer(ARP): | ||
| + | compteur_arp += 1 | ||
| + | else: | ||
| + | break | ||
| + | if (compteur_udp+compteur_tcp+compteur_arp !=0): | ||
| + | if (cpt%3 ==0): | ||
| + | pourcentage_udp_test.append( (compteur_udp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | pourcentage_tcp_test.append( (compteur_tcp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | pourcentage_arp_test.append( (compteur_arp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | y_test1.append(1) | ||
| + | cpt=cpt+1 | ||
| + | else: | ||
| + | pourcentage_udp_tr.append( (compteur_udp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | pourcentage_tcp_tr.append( (compteur_tcp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | pourcentage_arp_tr.append( (compteur_arp)/(compteur_udp + compteur_tcp + compteur_arp)) | ||
| + | y_train1.append(1) | ||
| + | cpt=cpt+1 | ||
| + | |||
| + | Nous rangeons ensuite chaque pourcentage dans un tableau différent (poucentage_udp,pourcentage_tcp,pourcentage_arp). Comme vous pouvez le voir ci-dessus, nous avons décidé de consacrer les 2/3 de nos données à la création d'un dataset de training et 1/3 de nos données à la création d'un dataset de test. | ||
| + | |||
| + | Ensuite, nous mettons nos données en format matrice (plutôt que tableau de listes) : | ||
| + | |||
| + | # On met nos données en format matrice (plutot que tableau de liste) | ||
| + | x_train = [pourcentage_udp_tr,pourcentage_tcp_tr,pourcentage_arp_tr] | ||
| + | x_train_final = np.array(x_train) | ||
| + | x_train_final = np.transpose(x_train_final) | ||
| + | y_train_final = np.array(y_train1) | ||
| + | |||
| + | Enfin, pour pouvoir utiliser les convolutions (Conv2D) dans l'entraînement de notre modèle, nous devons faire un "reshape" de nos données d'entrées puisque Conv2D attend au minimum des données de dimension 3 : | ||
| + | |||
| + | # On reshape la forme des données d'entrées pour que ca match avec Conv2D | ||
| + | x_final_train = [] | ||
| + | size = np.size(x_train_final,axis=1) | ||
| + | for x in x_train_final: | ||
| + | sample = x.reshape([size,1,1]) | ||
| + | x_final_train.append(sample) | ||
| + | x_train_final = np.array(x_final_train) | ||
| + | |||
| + | Nous pouvons ensuite retourner nos différentes données (x_train,x_test, y_train, y_test). | ||
| + | |||
| + | ===Entraînement et évaluation de notre modèle=== | ||
| + | |||
| + | Dans le main, nous allons appeler les différentes fonctions décrites précedemment pour créer et entraîner notre modèle dans un premier temps : | ||
| + | |||
| + | def main(): | ||
| + | |||
| + | (x_train,y_train,x_test,y_test)=preporcess(); | ||
| + | shape = x_train.shape | ||
| + | |||
| + | # Declare the model | ||
| + | model = generate_cnn_model(shape) | ||
| + | |||
| + | # Compile the network | ||
| + | opt = tf.keras.optimizers.Adam() | ||
| + | model.compile(loss='categorical_crossentropy', | ||
| + | optimizer=opt, metrics=['categorical_accuracy']) | ||
| + | |||
| + | # Early stopper declaration for the traning | ||
| + | stopper = EarlyStopping(monitor='val_binary_accuracy', patience=10, mode='auto') | ||
| + | |||
| + | # Learning | ||
| + | model.fit(x_train, y_train, epochs=1, callbacks=[stopper], batch_size=10) | ||
| + | |||
| + | # Evaluate the performance of the model | ||
| + | eval(model, x_test, y_test) | ||
| + | |||
| + | # serialize model to JSON | ||
| + | model_json = model.to_json() | ||
| + | with open("model.json", "w") as json_file: | ||
| + | json_file.write(model_json) | ||
| + | |||
| + | # serialize weights to HDF5 | ||
| + | model.save_weights("model.h5") | ||
| + | print("Saved model to disk") | ||
| + | |||
| + | Durant l’entraînement, on peut voir l’évolution de ce dernier, la précision de l’entraînement et le nombre de paquets perdus : | ||
| + | |||
| + | 7064/7068 [============================>.] - ETA: 0s - loss: 0.0000e+00 - categorical_accuracy: 1.0000 | ||
| + | 7068/7068 [==============================] - 27s 4ms/step - loss: 0.0000e+00 - categorical_accuracy: 1.0000 | ||
| + | |||
| + | Dans un second temps, nous allons évaluer la qualité de notre modèle grâce à la fonction "eval(model,x_test,y_test)" décrite ci-dessous : | ||
| + | |||
| + | def eval(model, x_test, y_test): | ||
| + | print ("Evaluation :") | ||
| + | score = model.evaluate(x_test, y_test, verbose=1,batch_size=5) | ||
| + | print("loss on test data:", score[0]) | ||
| + | print("accuracy on test data:", score[1]*100, "%") | ||
| + | |||
| + | L’évaluation nous renvoie toujours les mêmes résultats : | ||
| + | |||
| + | Evaluation : | ||
| + | 7068/7068 [==============================] - 15s 2ms/step - loss: 0.0000e+00 - categorical_accuracy: 1.0000 | ||
| + | loss on test data: 0.0 | ||
| + | |||
| + | Une fois le modèle entraîné puis testé, il ne nous reste plus qu'à le sauvegarder. Nous le sauvegardons sous deux formats différents : un format JSON puis un format HDF5. | ||
| + | |||
| + | ===Exécution du modèle en temps réel=== | ||
| + | |||
| + | Notre modèle est désormais construit. Nous devons trouver le moyen de pouvoir l’utiliser en direct, en parallèle d’une écoute réseau. Pour cela, nous avons crée deux nouveaux programmes python : Inspect.py et Monitoring.py. | ||
| + | |||
| + | Le premier n’a pas un grand intérêt puisqu’il consiste à charger le modèle .json et le modèle .h5. Ces modèles étant chargés nous les compilons ensemble puis nous le faisons fonctionner en lui fournissant des données d’entrée. | ||
| + | |||
| + | Le second programme, Monitoring.py doit donc être capable de réaliser une écoute réseau et de mettre les données dans un fichier pcap. Pendant que nous écrivons dans ce fichier pcap, nous allons en parallèle lire les données de ce fichier. Cette lecture permettra de réaliser un pré-processing afin de donner à notre modèle des données utilisables. Ces données utilisables seront stockées dans un fichier log par exemple. | ||
| + | |||
| + | C’est ce second programme qui nous pose problème aujourd’hui. Nous n’arrivons pas à réaliser l’écriture et la lecture en même temps. De plus, nous ne pouvons pas utiliser la même technique de pré-processing que la première fois puisque nous manipulons un fichier “dynamique”. Nous utilisons donc pcapy.open_live et pcapy.open_offline plutôt que rdpcap. | ||
| + | |||
| + | Nous avons donc écrit le code suivant (l'entièreté du code n'est pas présent ci-dessous, juste l'essentiel), ce code compile, l’écriture fonctionne mais la lecture est elle défaillante : | ||
| + | |||
| + | # callback for received packets | ||
| + | def write_packets(hdr, data): | ||
| + | print (eth_decoder.decode(data)) | ||
| + | dumper.dump(hdr, data) | ||
| + | |||
| + | def read_packets(hdr,data): | ||
| + | ether = eth_decoder.decode(data) | ||
| + | if ether.get_ether_type() == IP.ethertype: | ||
| + | ip = ip_decoder.decode(data) | ||
| + | if ip.get_ip_type() == TCP.iptype: | ||
| + | cpt_tcp +=1 | ||
| + | if ip.get_ip_type() == UDP.iptype: | ||
| + | cpt_udp +=1 | ||
| + | else: | ||
| + | if ether.get_ether_type() == ARP.ethertype: | ||
| + | cpt_arp +=1 | ||
| + | |||
| + | packet_limit = -1 # infinite | ||
| + | if ecriture == 1: | ||
| + | pc = pcapy.open_live("wlp1s0", max_bytes, promiscuous, read_timeout) | ||
| + | dumper = pc.dump_open("sniffer.pcap") | ||
| + | pc.loop(packet_limit, write_packets) # capture packets | ||
| + | else : | ||
| + | pc2 = pcapy.open_offline("sniffer.pcap") | ||
| + | pc2.loop(packet_limit, read_packets) | ||
| + | |||
| + | Nous pensons être sur la bonne voie mais nous n’arrivons pas à utiliser notre modèle de deep learning en direct. Cependant, nous pouvons réaliser les écoutes et utiliser notre modèle, après-coup, sur ces écoutes. | ||
| + | |||
| + | ==Version alternative du pré-processing== | ||
| + | |||
| + | En plus de la version présentée dans la partie ci dessus, nous avons travaillé sur une autre méthode de détection d'attaque ARP sur un réseau en reprenant le fonctionnement du machine learning. On utilise ici des données différentes de précédemment en fournissant au modèle une image du reseau des 60 dernières secondes. Ainsi, cette variante permet de donner et d'analyser plus précisément le trafic qui à eu lieu et donc de rendre mieux compte de la réalité. | ||
| + | |||
| + | ===Description et choix des données=== | ||
| + | |||
| + | Ici, ce ne sont donc pas des valeurs passées en entrée du machine learning, mais de grands tableaux contenant les informations des paquets ayant transité par le réseau que nous avons jugés utiles de garder. | ||
| + | Nous avons fait le choix de ne garder que les paquets ARP, afin de ne pas surcharger nos données et donc de minimiser le temps d'éxécution et le besoin en mémoire. De ces paquets, nous avons gardé seulement certaines informations qui sont utiles pour détecter une attaque ARP à savoir l'adresse MAC source, l'adresse MAC destinataire ainsi que l'horodatage de l'envoi de celui ci. | ||
| + | |||
| + | |||
| + | ===Générations des datasets=== | ||
| + | |||
| + | Pour entrainer le modèle, il nous faut au préalable récuperer des jeux de données en écoutant le réseau dans deux conditions : en temps normal et pendant une attaque ARP. Nous avons donc créé un script permettant de générer des fichiers .pcapng contenant le trafic réseau pendant 1 minute. Ce script est ensuite exécuté dans les deux conditions pour générer un nombre de fichier donné. | ||
| + | |||
| + | |||
| + | #!/bin/bash | ||
| + | |||
| + | for i in $(seq "$1") | ||
| + | do | ||
| + | dumpcap -a duration:60 -w DataSets/clean"$i".pcapng | ||
| + | done | ||
| + | |||
| + | |||
| + | |||
| + | [[Fichier:Capture5pkt.png]] | ||
| + | |||
| + | On nomme les datasets contenant un trafic "normal" cleanX.pcapng et les datasets contenant un trafic perturbé par une attaque ARP "contamineX.pcapng" | ||
| + | |||
| + | |||
| + | ===Entrainement du modèle=== | ||
| + | |||
| + | |||
| + | def convert_adr(adr): | ||
| + | sum=0 | ||
| + | for l in adr: | ||
| + | sum+=ord(l) | ||
| + | return sum | ||
| + | |||
| + | def preprocess(): | ||
| + | |||
| + | y_train = [[]] | ||
| + | x_train = [[]] | ||
| + | num_file=0 | ||
| + | |||
| + | for file in os.listdir("DataSets/"): | ||
| + | if 'pcapng' in file: | ||
| + | reader = rdpcap("DataSets/"+file) | ||
| + | num_file+=1 | ||
| + | |||
| + | if 'clean' in file: | ||
| + | y_train[0].append(0) | ||
| + | else: | ||
| + | y_train[0].append(1) | ||
| + | |||
| + | time_base = reader[0].time | ||
| + | |||
| + | for pkt in reader: | ||
| + | if pkt.haslayer(ARP): | ||
| + | x_train[0].append([int(pkt.time-time_base), convert_adr(pkt.dst), convert_adr(pkt.src)]) | ||
| + | |||
| + | print("Processed {} files".format(num_file)) | ||
| + | |||
| + | print ("Pré-processing fait !") | ||
| + | return (x_train, y_train) | ||
| + | |||
| + | |||
| + | (x_train,y_train)=preprocess() | ||
| + | |||
| + | |||
| + | Le pré-processing généré deux tableaux x_train et y_train comme dans la version précédente. | ||
| + | |||
| + | Le x_train contient toutes les "images" du trafic ARP du réseau. Chaque case est associée à un fichier .pcapng et donc à une minute de trafic. On appelle "image du réseau" la matrice où chaque ligne est un paquet ARP capté et où les colonnes sont l'horodatage et les adresses sources et destinataire de chaque paquet. | ||
| + | |||
| + | Dans y_train, on associe à chaque image de réseau un 0 si elle est normale et un 1 si une attaque ARP à eu lieu dans celle ci. | ||
| + | |||
| + | Ces fichiers x_train et y_train sont ensuite à passer en entrée du programme de machine learning pour qu'il s'entraine. | ||
| + | |||
| + | [[Fichier:Preprocess.png]] | ||
| + | |||
| + | |||
| + | ===Bilan de cette méthode=== | ||
| + | |||
| + | Comme expliqué précédemment, le problème de cryptage des paquets lorsque nous voulons effectuer le monitoring sur une borne de Polytech ne nous permet pas de tester ce modèle. En effet, celui-ci repose sur des données qui sont cryptées et donc inexploitables. Par ailleurs, nos difficultés à lancer le machine learning en temps réel ne nous a pas permis de comparer cette méthode à la première. Cependant, le pré-processing et l'entraînement du modèle fonctionne pour un usage sur un réseau privé. | ||
| + | |||
| + | =Conclusion= | ||
| + | |||
| + | Durant ces trois semestres, nous avons essayé de mettre en place du machine learning pour détecter des comportements malveillants sur le réseau WiFi. Le cahier des charges initial nous demandait de faire une surveillance sur du réseau WiFi et sur du réseau LoRa. Au vue de la complexité du projet nous avons au fur et à mesure du projet abandonné l’idée de traiter le réseau LoRa. Lors du premier semestre, nous nous sommes concentrés sur le réseau. Nous avons eu une mauvaise approche du projet en ne prenant pas assez en compte l’aspect machine learning du projet. Nous sommes partis dans une mauvaise direction. Ainsi pendant le premier semestre, nous avons acquis des connaissances sur le réseau et sur les outils d’analyse mais nous avons abandonné la partie que nous avions réalisée. | ||
| − | + | De ce fait, au semestre suivant, nous avons redéfini notre cahier des charges, et revu notre définition du projet. Nous avons étudié différents articles et projets pour comprendre au mieux comment nous pouvions mettre en place l’outil de machine learning pour la surveillance du réseau. Nous avons donc préparé le cahier des charges et établi les objectifs pour le dernier semestre. Nous avons pu acquérir les connaissances nécessaires en réseau et en machine learning pour se préparer pour le dernier semestre. | |
| − | |||
| − | + | Ainsi, pour ce dernier semestre, d’un point de vue réseau nous avons eu à préparer le jeu de données pour entraîner le modèle de machine learning. Pour ce faire nous avons fait une écoute réseau saine où aucune attaque a été simulé et une autre écoute où nous avons injecté des paquets que nous pouvons considéré comme malveillants. D’un point de vue machine learning nous avons créé notre modèle pour l'entraîner avec notre jeu de données. Nous avons ensuite tenté d’utiliser notre modèle en temps réel. Sur ce semestre, nous avons donc gagné en compétences techniques sur l’injection de paquets et sur l’intelligence artificielle. | |
| − | |||
| − | = | + | =Bibliographie= |
| − | + | '''Etat de l'art''' | |
| − | = | + | Argus : https://github.com/jmanteau/lprims-nsm/blob/master/TP%20-%20Utilisation%20Tcpdump%20Tshark%20Argus%20Snort%20Bro.md |
| + | https://www.mankier.com/1/ra?fbclid=IwAR1TznPzCRb2kxH1yEf5OsUf03rElYWdvzjmdFGzFwRr_3VQvsAZ8isf8VI#Synopsis | ||
| − | + | '''Partie réseau''' | |
| − | + | '''Partie machine learning''' | |
| − | + | Détection d'intrusion : https://connect.ed-diamond.com/MISC/mischs-018/vers-une-detection-d-intrusion-dynamique-et-continue-en-utilisant-les-reseaux-de-neurones?fbclid=IwAR1XAjxRdHp_NHfmqxpxHNlNYuKgTRPxV9GayYv-53j6B5ZeOn6HCxheM-Y | |
| − | + | Keras : https://keras.io/guides | |
| − | + | Tensorflow : https://www.tensorflow.org | |
| − | + | Man-in-the-middle : https://www.okta.com/fr/identity-101/arp-poisoning/ | |
| − | + | Thèse sur la détection d'attaque ARP : https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3659129 | |
Version actuelle datée du 5 mai 2022 à 22:00
Sommaire
Présentation
Contexte
De nos jours, de plus en plus d’appareils électroniques ont besoin d’une connexion internet pour fonctionner. En outre, la majeure partie de nos données sont conservées sur le cloud et transitent par le biais d’internet. Il est donc nécessaire pour des grandes entreprises ou même des particuliers de pouvoir sécuriser ces données et ces appareils. Le réseau doit être protégé de toutes attaques malveillantes. Une manière de sécuriser le réseau est de détecter qui peut être un utilisateur malveillant, c'est que nous allons faire dans ce projet.
Description
Pour identifier les utilisateurs suspects voir malveillant, nous allons écouter le réseau et au travers des différents paquets échangés essayer de détecter les tentatives de connexions suspectes. La récupération des données du paquet suspect nous permet d'identifier la machine et permettrait d'isoler ou de bannir cette utilisateur du réseau mais ce n'est pas dans le cadre du projet. Pour écouter le réseau nous utilisons Wireshark, l'écoute génère un fichier avec l'extension .pcap que nous allons traiter en Python. Le fichier est .pcap est la liste des paquets écoutés. Avec python, nous allons analyser ces listes de paquets avec TensorFlow un outil open source d'apprentissage automatique et la bibliothèque Keras permettant d'interagir avec les algorithmes de langages d'apprentissage profond. L'objectif est d'analyser les différents paquets pour en identifier les comportements suspects. Cependant, nous devons définir ce qu'est un comportement suspect en analysant les différents protocoles wifi.
Partie Réseau
Théorie
La partie du réseau que nous allons étudier/analyser est la Wi-Fi. Nous nous pencherons donc sur la composition des trames Wi-Fi qui se basent sur le standard IEE 802.11.
Trame 802.11
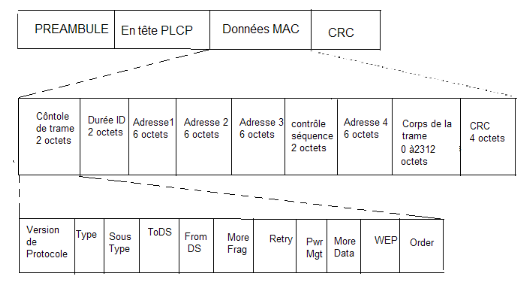

Voici la description d'une trame Wi-Fi, ce qui nous intéresse dans notre projet ce sont les données MAC. Le préambule ainsi que l'en-tête PLCP sont présents pour permettre une connexion ainsi qu'une synchronisation avec les points d'accès (couche physique/niveau 1).
Explication des différents champs
-Contrôle de trame (2 octets) : donne des informations sur la nature de la trame
-Durée (2 octets) : donne la durée de la séquence en ms
-Adresse 1,2 et 3 (3*6 octets) : Tout dépend du mode de fonctionnement (ad-hoc ou infrastructure). Le plus souvent ce sera en mode infrastructure avec l'adresse 1 qui désigne l'adresse MAC du point d'accès, l'adresse 2 désignant la station source et l'adresse 3 désignant la station destination.
-Contrôle séquence (2 octets) : composé d'un numéro de séquence attribué à chaque trame sur 12 bits ainsi que numéro de fragment sur 4 bits si la trame est fragmentée.
-Corps de la trame(0 à 2312 octets) : trames de niveaux supérieurs qui sont encapsulés dans la trame 802.11
-CRC (4 octets) : somme de contrôle
Mode moniteur
Maintenant que nous comprenons le contenu d'un paquet Wi-Fi, nous souhaitons capturer tous ces paquets afin de les étudier. Il faut savoir qu'il existe plusieurs mode de fonctionnement d'une carte réseau. Le plus courant est le mode infrastructure qui va permettre de communiquer avec les autres appareils. Il existe aussi le mode moniteur qui nous permet d'écouter le trafic réseau et de capturer les paquets. Le mode moniteur permet l'écoute et l'analyse passive des données circulant sur le réseau. Dans notre projet, nous utiliserons ce mode de fonctionnement pour sniffer les trames 802.11 à l'aide d'un logiciel de sniffing. Cependant, une fois dans ce mode, il nous est impossible de communiquer avec d'autres appareil au travers de ce réseau puisque l'appareil n'est pas connecté à un point d'accès (elle n'a pas d'adresse IP définie).
Capture Réseau
Aujourd'hui, beaucoup d'utilitaire sont développés afin de capturer des paquets réseau et les analyser. Les logiciels vont analyser les paquets afin de décrypter et ressortir les infos qu'ils transportent. Les logiciels comme Kismet et Wireshark permettent à un utilisateur de faire de la surveillance réseau manuellement. L'utilitaire Aircrack quant à lui permet de cracker des clés Wi-Fi en s'appuyant sur le mode moniteur de la carte réseau. Nous nous appuierons donc sur ces logiciels afin de réaliser notre projet. Les fichiers de capture de paquets sont sous l'extension pcap et sont lisibles par des analyseurs de réseau.
Wireshark
Nous souhaitons récupérer les données importantes des trames Wi-Fi afin de les analyser par la suite à l'aide de notre algorithme de machine learning. Pour cela nous allons réaliser cette partie en deux temps. Premièrement, la capture des paquets. Puis l'extraction des données en vue de l'analyse.
Pour réaliser la capture des paquets, nous pouvions utiliser plusieurs utilitaires tels que Wireshark, dumpcap, tcpdump et Aircrack.
Lors du premier semestre, nous nous étions penchés sur l'utilisation d'Aircrack. Cependant, ce choix ne s'est pas révélé être le bon puisque nous avons constaté que les paquets étaient certes capturés mais les informations importantes qui permettraient une analyse et ne détection des menaces n'étaient pas récupérées. Nous avons donc dû changer de logiciel de sniffing lors de ce second semestre afin de capturer des paquets en entier.
Nous nous sommes donc penchés sur la suite Wireshark. Wireshark sniffe, capture les paquets et les analyse également. Le logiciel Wireshark est utilisable avec une interface graphique. Ce qui ne nous arrange pas puisque nous voulons automatiser la capture/pré-analyse. Nous passerons donc par la commande "dumpcap" qui est la version en lignes de commande de Wireshark.
Liste des commandes utilisées :
-f : Permet de capturer seulement certain types de paquets. Par exemple -f arp permet de capturer seulement les paquets ARP -I : Met la carte en mode routeur et nous permet de capturer tous les paquets 802.11 circulant sur le réseau -P : Permet d'obtenir un fichier d'extension pcap à la place d'un fichier pcapng. -a duration:time : arrête la capture après un temps "time" en secondes. exemple dumpcap -a duration:30 fait une capture de paquets pendant 30 secondes.
Nous sommes donc arrivés à une capture par le biais de la commande suivante :
dumpcap -I -P -a duration:60 -f "type mgt or type ctl or type data"
Cette commande nous permet de capturer tous les paquets 802.11 en passant notre carte en mode moniteur pendant une durée de 60 secondes. Le filtre -f permet d'ignorer les paquets malformés ou corrompus. En pré-analysant les différents trames Wifi, nous serons capable de récupérer les informations nécessaires.
Nous voulions ensuite passer sur un analyseur de trame pour récupérer les données. Nous avons essayé d'utiliser la librairie scapy une librairie python pour ressortir les informations des paquets mais cela ne s'est pas révélé concluant. Les informations récupérées n'étant pas les bonnes.
En observant les données demandées pour l'algorithme de Machine Learning, nous nous sommes rendu compte que l'analyse ne devait pas se faire paquets par paquets mais plutôt statistiquement, c'est à dire en observant les connexions entre deux adresses, leur nombre,....
Nous avons donc décidé de nous tourner vers l'utilitaire tshark qui nous permet de préanalyser les fichiers de capture d'extension pcap. Nous allons pouvoir sortir les données sous forme de tableaux exploitables par l'algorithme.
Format de la commande :
tshark -r fichieràlire -T fields -e nomduchampàrécupérer > fichier.csv
aireplay-ng
Aireplay-ng est un outil de de la suite aircrack-ng. La suite de logiciel permet la surveillance de réseaux sans fil mais son utilisation principale est de casser les clés WEP et WPA des réseaux Wi-Fi mais ce n'est pas le but du projet, c'est pourquoi nous allons étudier aireplay-ng. Cet outil permet d'injecter des paquets 802.11 sur le réseau. Aircrack-ng s'utilise avec des lignes de commandes dans le terminal. Dans les lignes de commandes, il existe un paramètre permettant de générer des paquets pour certains types d'injections. Les types d'injection par défaut sont :
-désauthentification
-fausse authentification
-reinjection selective de paquet (permet de choisir un paquet particulier pour être injecter un grand nombre de fois sur le réseau)
- répétition de requête ARP
- Korek chopchop (permet le déchiffrement de paquets sans avoir la clé de cryptage WEP)
- attaque par fragmentation (exploite le principe de fragmentation des paquets IP)
- Cafe-latte (obtention de la clé WEP)
- attaque par fragmentation orienté client
- WPA Migration Mode (modifie le WPA migration mode qui est un paramètre des points d'accès Cisco)
- Test d'injection (simple test pour voir si notre carte réseau est capable d'injecter des paquets
Ces types d'injection ou d'attaques s'utilisent en ajoutant "-X" avec X le numéro du paramètre allant de 0 à 9 selon la liste précédente.
Dans un objectif de surveillance du réseau de l'école, les attaques concernant le protocole de sécurité WPE ne seront pas étudiés, ce protocole n'est plus utilisé depuis de nombreuses années.
Les commandes s'utilisent de la manière suivante
aireplay-ng <options> <replay interface>
En effet, il existe différentes options de filtres permettant de personnaliser les paquets avec notre réseau. Nous pouvons choisir l'adresse mac du point d'accès, l'adresse mac de destination et de source , la taille minimale et ou maximale d'un paquet, et d'autres options agissant sur la trame de contrôle. Ces paramètres sont à utiliser pour la simulation d'attaque. Voici quelques exemples :
-b bssid : MAC address, Access Point -d dmac : MAC address, Destination -s smac : MAC address, Source -m len : minimum packet length -u type : frame control, type field
Il existe aussi des options pour la répétition de paquets comme le nombre de paquets envoyés par secondes, le mot de la frame de control, la fixation d'un point d'accès, d'une adresse de destination ou de source, paramétrage de l'IP source ou destination. Ce sont les paramètres que nous retenons pour le moment. Ces paramètres sont à utiliser pour l'injection de paquets sans simulation d'attaque
-x nombre de paquets par seconde -a bssid : set Access Point MAC address -c dmac : set Destination MAC address -h smac : set Source MAC address -k IP : set destination IP in fragments -l IP : set source IP in fragments
Ainsi, l'objectif d'aircrack dans le projet est de simuler des attaques sur le réseau pour que nous puissions les identifier et les ajouter à notre set de données pour le modèle de machine learning.
Finalement cette solution n'a pas été retenue pour l'injection de paquets. Ce n'était pas le plus simple pour injecter des paquets sur le réseau et en même temps le simuler et en même temps capturer le réseau.
Edition de fichier pcap
Pour faire notre jeu de données, nous avons eu besoin de manipuler des fichiers pcap. Ce traitement peut se faire rapidement avec l'utilitaire editcap ou encore mergecap. Ces utilitaires sont installés automatiquement quand nous téléchargeons Wireshark. Ces outils fonctionnent en ligne de commande avec différentes options.
Quelques exemples options d'editpcap :
-A temps à partir duquel les données sont sélectionnées -B temps jusqu'auquel les données sont séléctionnées -c nombre de paquets par fichiers -i nombre de secondes contenue dans un fichier
Quelques exemples options de mergecap :
-a concatène plutôt que merge les fichiers -w permet de choisir/créer le fichier de sortie
Argus
A la différence de Tshark et tcpdump, Argus ne réalise pas une copie complète du traffic, Argus se concentre sur la "Session Data" (trames TCP ou UDP). Argus décrit les conversations réseaux se concentrant sur qui parle avec qui, quand et combien d'informations ont été échangés. Cependant, nous ne pouvons pas observer des requêtes ARP par exemple, ce qui peut être dérengeant pour le projet.
Simulation du trafic réseau sain
Pour simuler le trafic sans attaque, nous avons utiliser différents outils.
Tout d'abord le plus simple est de capturer pendant assez longtemps nos recherches sur le navigateur. Nous avons aussi fait un script pour simuler du trafic sur certains sites internet et avoir un nombre de requêtes important en peu de temps. Le script suivant permet via un fichier texte contenant l'adresse de 10 sites avec un site par ligne de récupérer de manière aléatoire une adresse et d'effectuer une requête via la commande curl. La commande retourne le code html de la page. Afin de ne pas polluer la sortie standard, le code est retourné dans un fichier texte temporaire.
#!/bin/bash
for (( i=0; i <= 100; i++ ));
do
site=$(sed -n $((1 + RANDOM % 10))p trafic.txt);
curl $site > /tmp/simutrafic.txt
sleep 5
done
Certes se sont toujours les mêmes sites internets, mais dans le contexte du projet nous ne regardons pas le contenu de la requête mais son type (UDP,ARP,TCP).
Simulation d'une attaque sur un réseau
Nous nous sommes axés sur la détection des attaques de type ARP (saturation du réseau par émission de requêtes ARP, ARP-spoofing…). Réaliser des attaques avec ARP nécessite souvent d'émettre un grand nombre de paquets de ce type. Ainsi, et afin d’entraîner notre modèle de machine learning, nous avons dû réaliser des émissions de paquets ARP en grand nombre pour simuler des attaques. Ces attaques ont en parallèle été enregistrées à l’aide de notre sniffer pour créer un jeu de données “infectées” utilisable par notre modèle.
Pour réaliser les émissions de requêtes, nous nous sommes aidé de la bibliothèque python scapy. Cette dernière nous permet de fabriquer nos propres paquets et de les émettre sur le réseau ciblé. Nous formons et envoyons donc nos paquets à l’aide du code suivant :

Avec ce programme nous pouvons choisir d’envoyer des requêtes ARP en boucle ou envoyer des réponses spontanées pour détourner les paquets de la cible (ARP poisoning), notre but étant d'augmenter drastiquement le nombre de paquet ARP par rapport à un trafic classique.
Voici ce que donne une attaque :


En combinant cette simulation d’attaques avec la simulation de trafic, nous obtenons les jeux de données nécessaires à l’entraînement de notre modèle de machine learning.
Contraintes rencontrées pour la capture
Tout d'abord, nous avons essayé de capturer simplement le trafic du réseau, nous avons rapidement vu que tous les données qui circulaient étaient cryptées donc il est impossible de capturer le réseau simplement de cette manière pour l'analyser. Nous avons ensuite voulu faire une capture sur un routeur pour pouvoir voir tout le réseau décrypté. Cette solution auraient été possible en faisant un port miroir sur un routeur, cette technique consiste à envoyer sur un port du routeur la copie de tous les paquets qui circulent. Cependant ce n'est pas réalisable à Polytech. D'un point de vue de la confidentialité, ils auraient fallu traiter tous les paquets pour vérifier qu'aucune donnée personnelle ne circule et nous n'avons pas accès aux routeurs. Nous avons ensuite essayer de faire une capture sur les machines ZABETH fonctionnant en Ethernet sauf que les ZABETH sont sur un réseau commuté, c'est à dire que les paquets sont dirigés seulement vers la machine concerné. Finalement, nous sommes revenus à la solution la plus simple qui est de capturer sur nos ordinateurs pendant les séances de projet comme ca nous avons les paquets décryptées que notre carte réseau traite. Après pour avoir un fichier de capture plus long nous pouvons les assembler pour avoir une version plus complète de l'activité du réseau. Ainsi, contrairement à la consigne initial, nous ne capturons pas directement des paquets wifi, nous capturons des paquets sous la forme Ethernet mais qui ont été envoyé par wifi.
Partie Machine learning
Etude de cas 1 : Classement d'images
Les premiers algorithmes de machine learning que nous avons étudiés sont des algorithmes de classification d'images. Nous avons utilisé les jeux de données (appelés Dataset) connu MNIST et Fashion MNIST afin de mettre en place, tester et surtout comprendre le fonctionnement d'un algorithme de machine learning. Le premier, MNIST, contient des images de chiffre manuscrit, le but de l'algorithme est donc de détecter de quel chiffre il s'agit sur chaque image. Le second, sur lequel nous allons nous attarder afin d'expliquer le fonctionnement d'un réseau de neurones est Fashion MNIST, qui regroupe des images de vêtements. L'algorithme doit alors être capable de classer ces vêtements par type.
Exploitation du jeu de données
Le jeu de données que nous avons principalement utilisé est le Fashion MNIST. Ce dataset contient 60000 images d'entrainement et 10000 images de test. Ces images représentent des vêtements au format 28x28 pixels. Ces vêtements sont de différents type : T-shirt, Pantalon, Pull, Robe, Manteau, Sandale, La chemise, Baskets, Sac ou Bottine. Les 60000 images forment un jeu de données d'entrainement qui va être utilisé par le programme pour apprendre à reconnaitre les vêtements en les comparant. Le jeu de test de 10000 images va quant à lui permettre d'évaluer la précision du réseau de neurones après son apprentissage.
Ces données sont charger dans des tableaux numpy pour être utilisés par le réseau :
fashion_mnist = tf.keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Chaque élément des tableaux train_images et test_images sont des tableaux de 28x28 contenant les pixels de l'image et les éléments des tableaux train_labels et test_labels sont des nombre entier représentant les types de vétements : 0 T-shirt, 1 Pantalon, 2 Pull ...
On peut observer cela avec :
> train_images.shape() (60000, 28, 28)
Pré-traitement
Maintenant que nos données sont chargées, il faut les prétraiter afin qu'elles soient utilisables et interprétables par le réseau de neurones. Dans les tableaux précédemment créés, chaque pixel a une valeur de 0 à 255, représentant son intensité. Pour que ces données soient compréhensibles par le réseau, il faut qu'elles soient comprises dans l'intervalle 0 et 1. On ajuste donc les valeurs :
train_images = train_images / 255.0 test_images = test_images / 255.0
Nous sommes désormais prêt à construire notre modèle.
Construction du modéle
Un réseau de neurones fonctionne en couches superposées qui communiquent entre elles et qui ont des paramètres qui s'apprennent durant la formation. Ici nous utilisons un modèle séquentiel, qui est une pile linéaire de couches de neurones (appelés nœuds)
Voici la création de notre modèle :
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
La première couche tf.keras.layers.Flatten permet de linéariser nos images en transformant nos tableaux 2 dimensions en tableaux 1 dimension. Les deux couches suivantes créées par tf.keras.layers.Dense comportent respectivement 128 et 10 nœuds. La dernière couche, de 10 nœuds, contient les scores correspondants aux 10 types de vêtements.
On utilise ensuite model.compile pour compiler notre modèle
Entrainement du modèle
On est ensuite prêt à entrainer le modèle :
model.fit(train_images, train_labels, epochs=10)
Le modèle s'entraine et augmente en précision à chaque nouvel entrainement On peut tester sa précision avec un jeu de test :
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
On peut aussi utiliser des prédictions que l'on vérifie avec les jeux de test pour évaluer la fiabilité du résultat.
Vérification et test du modèle
Notre modèle est désormais prêt et on peut l'utiliser en lui fournissant une image. Pour cela, on prend une image au hasard du jeu de test, ici un Pull (associé à 2)
img = test_images[1] img = (np.expand_dims(img,0)) predictions_single = probability_model.predict(img) print(predictions_single)
On obtient la probabilité que l'image a d'être chaque type :
[8.8914348e-05 1.3264636e-13 9.9108773e-01 1.2658383e-10 8.1463791e-03 1.6905785e-08 6.7695131e-04 2.7492119e-17 5.1699739e-10 7.1339325e-17]
On remarque que la probabilité 2 est beaucoup plus élevé, le modèle prédit donc un Pull, ce qui est le cas
Cette partie étude de différents réseaux de neurones, tel que celui ci, nous a grandement aidé à comprendre l'enjeu et le fonctionnement des algorithmes de machine learning. Ces connaissances nous permettent désormais de mieux comprendre comment mettre en place notre réseau de neurones pour qu'il soit efficace à notre projet.
Etude de cas 2 : Une détection d'intrusion
Notre projet consiste à surveiller le réseau et les utilisateurs de ce réseau. La question qui se pose est alors la suivante : comment surveiller et analyser les milliers de données qui transitent sur ce réseau tous les jours ? Comment reconnaître un comportement malveillant ? C'est alors là que le machine learning devient intéressant. En effet,la détection d'un comportement malveillant revient à chercher une aiguille dans une botte de foin. Mais les algorithmes de Machine Learning permettent de traiter efficacement d'immenses quantités de données.
Réseaux de neurones convolutionnels
Les algorithmes de Machine Learning reposent sur des réseaux de neurones convultionnels (CNN). Ces derniers sont composés de couches de neurones où chaque neurone est relié à tous les neurones de la couche précédente. En python, avec la commande "model.add" nous pouvons ajouter les couches nécessaires à notre réseau en décrivant chaque couche avec différents paramètres.
Pour notre projet, nous allons devoir utiliser le Deep Learning. Le Deep Learning est une forme spécifique de Machine Learning où des couches cachées sont présentes entre les différentes couches de neurones. Il est préférable d'utiliser le Deep Leraning pour deux raisons :
- Notre algorithme se forme tout seul, nous avons juste à lui fournir des données pour s'entraîner
- Le Deep Learning est plus efficace que le Machine Learning grâce à ses réseaux de neurones profonds
Paramètres permettant la détection d'intrusions
Différents paramètres sélectionnés au préalable permettent de surveiller le réseau. Ces paramètres constituent une couche d'entrée du réseau de neurones. La couche de sortie nous donne la classification des comportements malveillants. Il est très important de choisir les bons paramètres pour que notre modèle soit biaisé par de fausses informations. Les paramètres extraits du réseau sont les suivants :
- la durée totale de l'enregistrement - le nombre de paquets envoyés de la destination à la source - le nombre d'octets envoyés de la source à la destination - le nombre d'octets envoyés de la destination à la source - le nombre de paquets par seconde - Time To Live (TTL) de la source à la destination - TTL de la destination à la source - Nombre de bits par seconde pour la source - Nombre de bits par seconde pour la destination - Moyenne de la taille des paquets de flux transmis par l'adresse IP source - Moyenne de la taille des paquets de flux transmis par l'adresse IP destination
Réalisation de l'algorithme
Pour créer l'algorithme de Deep Learning maintenant bien défini, il est conseillé d'utiliser Python. Ainsi, il est possible d'utiliser deux bibliothèques écrites en Python particulièrement utiles pour créer notre algorithme : Tensorflow et Keras.
Tensorflow est un outil open source d'apprentissage automoatique. C'est un outil très utilisé dans le domaine de l'intelligence artificielle et plus particulièrement de l'apprentissage machine.
Keras est quant à lui permet d'interagir avec les algorithmes de réseaux de neurones profonds et d'apprentissage automatique comme Tensorflow cité précedemment.
La combinaison de ces deux bilbiothèques permet de créer notre algorithme de Deep Learning.
Fonctionnement de l'algorithme
Un premier programme training-set permet de créer le modèle séquentiel avec plusieurs entrées et une seule sortie. L'utilisation de Convolution (Conv2D) et ReLU permettent des réduire la taille des données (filtre). L'utilisation de MaxPooling permet elle d'échantillonner les données pour diminuer leur dimension. Nous diminuons ainsi les données jusqu'à obtenir une seule sortie.
Il nous faut ensuite prétraiter les données. Pour cela on isole les données qui nous intéressent puis on les normalise pour obtenir un jeu de données compréhensible par notre modèle.
Pour créer notre jeu de données initiale, nous allons faire une écoute réseau sur une durées assez importante et pendant cette période simuler des attaques avec l'outil aireplay-ng pour que les paquets malveillants soit capturés. Une fois tous les paquets capturés, nous devrons identifiés nous même lesquels sont malveillants pour que l'algorithme puisse par la suite comprendre et établir un modèle d'un comportement malveillant sur le réseau.
Nous pouvons ensuite générer notre modèle séquentiel et l'entraîner avec nos données pour avoir un programme opérationnel. Une fois opérationnel, nous pouvons enregistrer ce modèle en format Keras H5 ou sous forme d'un fichier JSON.
Création de notre modèle
De notre côté, nous cherchons à réaliser du net monitoring, nous ne devons pas écouter seulement ce qui arrive sur notre machine mais nous devons aussi écouter ce qu'il se passe sur les machines environnantes.
Dans un premier temps, nous allons devoir créer notre modèle séquentiel. Sa taille et le nombre de couches variera en fonction du nombre de paramètres retenus.
Afin de créer nos Dataset utiles à l'apprentissage et l'entraînement de notre modèle, nous devrons simuler quelques attaques sélectionnées au préalable avec Aircrack. Ainsi nous pourrons récupérer certains paquets en sachant qu'ils sont suspects pour créer notre Dataset.
Une fois notre modèle entraîner, nous pourrons l'enregistrer sous forme d'un fichier Keras H5. Sinon, nous avons toujours l'option d'enregistrer notre modèle sous la forme d'un fichier JSON.
Nous pouvons ensuite lancer l'écoute réseau en arrière plan. Durant l'écoute, nous allons extraire les paramètres sélectionnés dans fichier log. Ainsi, pendant que le fichier continue de se remplir, notre modèle séquentiel pourra réaliser l'étude des paramètres pour essayer de détecter des comportements malveillants. En cas d'attaque, nous devrons créer une alerte, cela se fera surement à l'aide d'un second programme python.
Révision du projet
Nous avons décidé de nous concentrer sur les attaques à base d'injection ARP comme par exemple l'attaque Man In The Middle. En effet, cette attaque est composée de deux étapes : l'usurpation ARP et l'empoisonnement ARP.
L'usurpation ARP est une attque où un pirate envoie de faux paquets ARP reliant l'adresse MAC d'un attaquant à l'adresse IP d'un ordinateur déjà sur le LAN.
L'empoisonnement ARP, après une usurpation réussie, permet au pirate de modifier la table ARP de sa victime afin de falsifier les correspondances entre adresses MAC et IP. Ainsi, le pirate a accès à tout le traffic envoyé au réseau compromis sans même que la victime soit au courant.
Une fois installé, le pirate peut donc examiner tout le trafic envoyé au réseau avant que la victime le reçoive, il peut donc refuser d'acheminer le trafic s'il le souhaite. Il peut aussi modifier les informations envoyées avant que la victime les reçoive.
Ces attaques Man-in-the-middle compromettent la confidentialité, elles sont l'unes des cybermenaces les plus redoutables et dangereuses. C'est pourquoi nous avons décidé de nous concentrer sur ce type d'attaque.
Pour cela, nous allons observer le pourcentage de paquets ARP, de paquets UDP et de paquets TCP sur les 60 dernières secondes. Nous allons simuler des injections ARP pour créer des paquets malveillants. Ces paquets serviront à l'apprentissage de notre modèle de deep learning.
Architecture de notre réseau de neurones
L'architecture de notre réseau de neurones convolutionnel nous a posé quelques problèmes puisqu'à ce jour, il est diffcile de déterminer une architecture idéale. En effet, nous avons vu plusieurs projets qui testaient différentes architectures "à l'aveugle" pour regarder laquelle était la meilleure. De plus, chaque projet nécessite une architecture propre à elle. Cepedant, nous avons trouvé une thèse (renseignée en bibliographie) sur la détection d'attaque ARP à l'aide de deep learning.
Après une sélection simple des paramètres, différentes architectures ont été testées pour voir quelle était la plus efficace. Il en est ressorti de cette thèse qu'une architecture avec 3 neurones sur la couche d'entrée, une couche cachée comportant 3 neurones et 1 neurone sur la couche de sortie était l'architecture la plus efficace. Les paramètres sélectionnés sont les suivants : pourcentage de paquets ARP, TCP et UDP sur la dernière minute.
En se basant sur cette thèse, nous avons crée un réseau de neurones convolutionnels semblable en essayant d'enchaîner au mieux les MaxPooling et les Conv2D. Nous en sommes arrivés au code suivant :
def generate_cnn_model(shape):
model = Sequential()
model.add(Conv2D(32, (3, 1), activation='relu', input_shape = (3,1,1)))
model.add(Conv2D(32, (3, 1), activation='relu',padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2),padding="same"))
model.add(Conv2D(64, (3, 1), activation='relu',padding="same"))
model.add(Conv2D(64, (3, 1), activation='relu', padding="same"))
model.add(Conv2D(64, (3, 1), activation='relu', padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2),padding="same"))
model.add(Conv2D(128, (3, 1), activation='relu', padding="same"))
model.add(Conv2D(128, (3, 1), activation='relu', padding="same"))
model.add(Conv2D(128, (3, 1), activation='relu', padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2),padding="same"))
model.add(Flatten())
model.add(Dense(1, kernel_initializer='normal', activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, kernel_initializer='normal',
activation='relu', name='output'))
model.add(Dense(1, kernel_initializer='normal', activation='softmax'))
return model
Création de notre dataset
Phase de pré-processing
Les données que nous récupérons sont des données brutes (des paquets réseau). Nous devons donc réaliser une phase de pré-processing pour récupérer des données utilisables. Ces données utilisables sont dans notre cas le pourcentage de paquets TCP, UDP et ARP sur les 60 dernières secondes. Pour chacun des deux datasets, nous allons parcourir le fichier ligne par ligne. Pour chacune des lignes, nous récupérons les paquets des 60 dernières secondes et nous identifions la nature de chacun des paquets. Après l'identification, nous comptons le nombre de paquets de chaque type sur la dernière minute, nous pouvons ainsi calculer nos pourcentages :
# On parcourt le 1er dataset "classique"
for i in range(0,len(reader)):
for j in range(i,0,-1):
if reader[j].time > reader[i].time - 60:
if reader[j].haslayer(TCP):
compteur_tcp += 1
if reader[j].haslayer(UDP):
compteur_udp += 1
if reader[j].haslayer(ARP):
compteur_arp += 1
else:
break
if (compteur_udp+compteur_tcp+compteur_arp !=0):
if (cpt%3 ==0):
pourcentage_udp_test.append( (compteur_udp)/(compteur_udp + compteur_tcp + compteur_arp))
pourcentage_tcp_test.append( (compteur_tcp)/(compteur_udp + compteur_tcp + compteur_arp))
pourcentage_arp_test.append( (compteur_arp)/(compteur_udp + compteur_tcp + compteur_arp))
y_test1.append(1)
cpt=cpt+1
else:
pourcentage_udp_tr.append( (compteur_udp)/(compteur_udp + compteur_tcp + compteur_arp))
pourcentage_tcp_tr.append( (compteur_tcp)/(compteur_udp + compteur_tcp + compteur_arp))
pourcentage_arp_tr.append( (compteur_arp)/(compteur_udp + compteur_tcp + compteur_arp))
y_train1.append(1)
cpt=cpt+1
Nous rangeons ensuite chaque pourcentage dans un tableau différent (poucentage_udp,pourcentage_tcp,pourcentage_arp). Comme vous pouvez le voir ci-dessus, nous avons décidé de consacrer les 2/3 de nos données à la création d'un dataset de training et 1/3 de nos données à la création d'un dataset de test.
Ensuite, nous mettons nos données en format matrice (plutôt que tableau de listes) :
# On met nos données en format matrice (plutot que tableau de liste) x_train = [pourcentage_udp_tr,pourcentage_tcp_tr,pourcentage_arp_tr] x_train_final = np.array(x_train) x_train_final = np.transpose(x_train_final) y_train_final = np.array(y_train1)
Enfin, pour pouvoir utiliser les convolutions (Conv2D) dans l'entraînement de notre modèle, nous devons faire un "reshape" de nos données d'entrées puisque Conv2D attend au minimum des données de dimension 3 :
# On reshape la forme des données d'entrées pour que ca match avec Conv2D
x_final_train = []
size = np.size(x_train_final,axis=1)
for x in x_train_final:
sample = x.reshape([size,1,1])
x_final_train.append(sample)
x_train_final = np.array(x_final_train)
Nous pouvons ensuite retourner nos différentes données (x_train,x_test, y_train, y_test).
Entraînement et évaluation de notre modèle
Dans le main, nous allons appeler les différentes fonctions décrites précedemment pour créer et entraîner notre modèle dans un premier temps :
def main():
(x_train,y_train,x_test,y_test)=preporcess(); shape = x_train.shape
# Declare the model model = generate_cnn_model(shape)
# Compile the network
opt = tf.keras.optimizers.Adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt, metrics=['categorical_accuracy'])
# Early stopper declaration for the traning stopper = EarlyStopping(monitor='val_binary_accuracy', patience=10, mode='auto')
# Learning model.fit(x_train, y_train, epochs=1, callbacks=[stopper], batch_size=10)
# Evaluate the performance of the model
eval(model, x_test, y_test)
# serialize model to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model.h5")
print("Saved model to disk")
Durant l’entraînement, on peut voir l’évolution de ce dernier, la précision de l’entraînement et le nombre de paquets perdus :
7064/7068 [============================>.] - ETA: 0s - loss: 0.0000e+00 - categorical_accuracy: 1.0000 7068/7068 [==============================] - 27s 4ms/step - loss: 0.0000e+00 - categorical_accuracy: 1.0000
Dans un second temps, nous allons évaluer la qualité de notre modèle grâce à la fonction "eval(model,x_test,y_test)" décrite ci-dessous :
def eval(model, x_test, y_test):
print ("Evaluation :")
score = model.evaluate(x_test, y_test, verbose=1,batch_size=5)
print("loss on test data:", score[0])
print("accuracy on test data:", score[1]*100, "%")
L’évaluation nous renvoie toujours les mêmes résultats :
Evaluation : 7068/7068 [==============================] - 15s 2ms/step - loss: 0.0000e+00 - categorical_accuracy: 1.0000 loss on test data: 0.0
Une fois le modèle entraîné puis testé, il ne nous reste plus qu'à le sauvegarder. Nous le sauvegardons sous deux formats différents : un format JSON puis un format HDF5.
Exécution du modèle en temps réel
Notre modèle est désormais construit. Nous devons trouver le moyen de pouvoir l’utiliser en direct, en parallèle d’une écoute réseau. Pour cela, nous avons crée deux nouveaux programmes python : Inspect.py et Monitoring.py.
Le premier n’a pas un grand intérêt puisqu’il consiste à charger le modèle .json et le modèle .h5. Ces modèles étant chargés nous les compilons ensemble puis nous le faisons fonctionner en lui fournissant des données d’entrée.
Le second programme, Monitoring.py doit donc être capable de réaliser une écoute réseau et de mettre les données dans un fichier pcap. Pendant que nous écrivons dans ce fichier pcap, nous allons en parallèle lire les données de ce fichier. Cette lecture permettra de réaliser un pré-processing afin de donner à notre modèle des données utilisables. Ces données utilisables seront stockées dans un fichier log par exemple.
C’est ce second programme qui nous pose problème aujourd’hui. Nous n’arrivons pas à réaliser l’écriture et la lecture en même temps. De plus, nous ne pouvons pas utiliser la même technique de pré-processing que la première fois puisque nous manipulons un fichier “dynamique”. Nous utilisons donc pcapy.open_live et pcapy.open_offline plutôt que rdpcap.
Nous avons donc écrit le code suivant (l'entièreté du code n'est pas présent ci-dessous, juste l'essentiel), ce code compile, l’écriture fonctionne mais la lecture est elle défaillante :
# callback for received packets
def write_packets(hdr, data):
print (eth_decoder.decode(data))
dumper.dump(hdr, data)
def read_packets(hdr,data):
ether = eth_decoder.decode(data)
if ether.get_ether_type() == IP.ethertype:
ip = ip_decoder.decode(data)
if ip.get_ip_type() == TCP.iptype:
cpt_tcp +=1
if ip.get_ip_type() == UDP.iptype:
cpt_udp +=1
else:
if ether.get_ether_type() == ARP.ethertype:
cpt_arp +=1
packet_limit = -1 # infinite
if ecriture == 1:
pc = pcapy.open_live("wlp1s0", max_bytes, promiscuous, read_timeout)
dumper = pc.dump_open("sniffer.pcap")
pc.loop(packet_limit, write_packets) # capture packets
else :
pc2 = pcapy.open_offline("sniffer.pcap")
pc2.loop(packet_limit, read_packets)
Nous pensons être sur la bonne voie mais nous n’arrivons pas à utiliser notre modèle de deep learning en direct. Cependant, nous pouvons réaliser les écoutes et utiliser notre modèle, après-coup, sur ces écoutes.
Version alternative du pré-processing
En plus de la version présentée dans la partie ci dessus, nous avons travaillé sur une autre méthode de détection d'attaque ARP sur un réseau en reprenant le fonctionnement du machine learning. On utilise ici des données différentes de précédemment en fournissant au modèle une image du reseau des 60 dernières secondes. Ainsi, cette variante permet de donner et d'analyser plus précisément le trafic qui à eu lieu et donc de rendre mieux compte de la réalité.
Description et choix des données
Ici, ce ne sont donc pas des valeurs passées en entrée du machine learning, mais de grands tableaux contenant les informations des paquets ayant transité par le réseau que nous avons jugés utiles de garder. Nous avons fait le choix de ne garder que les paquets ARP, afin de ne pas surcharger nos données et donc de minimiser le temps d'éxécution et le besoin en mémoire. De ces paquets, nous avons gardé seulement certaines informations qui sont utiles pour détecter une attaque ARP à savoir l'adresse MAC source, l'adresse MAC destinataire ainsi que l'horodatage de l'envoi de celui ci.
Générations des datasets
Pour entrainer le modèle, il nous faut au préalable récuperer des jeux de données en écoutant le réseau dans deux conditions : en temps normal et pendant une attaque ARP. Nous avons donc créé un script permettant de générer des fichiers .pcapng contenant le trafic réseau pendant 1 minute. Ce script est ensuite exécuté dans les deux conditions pour générer un nombre de fichier donné.
#!/bin/bash for i in $(seq "$1") do dumpcap -a duration:60 -w DataSets/clean"$i".pcapng done

On nomme les datasets contenant un trafic "normal" cleanX.pcapng et les datasets contenant un trafic perturbé par une attaque ARP "contamineX.pcapng"
Entrainement du modèle
def convert_adr(adr):
sum=0
for l in adr:
sum+=ord(l)
return sum
def preprocess():
y_train = [[]]
x_train = [[]]
num_file=0
for file in os.listdir("DataSets/"):
if 'pcapng' in file:
reader = rdpcap("DataSets/"+file)
num_file+=1
if 'clean' in file:
y_train[0].append(0)
else:
y_train[0].append(1)
time_base = reader[0].time
for pkt in reader:
if pkt.haslayer(ARP):
x_train[0].append([int(pkt.time-time_base), convert_adr(pkt.dst), convert_adr(pkt.src)])
print("Processed {} files".format(num_file))
print ("Pré-processing fait !")
return (x_train, y_train)
(x_train,y_train)=preprocess()
Le pré-processing généré deux tableaux x_train et y_train comme dans la version précédente.
Le x_train contient toutes les "images" du trafic ARP du réseau. Chaque case est associée à un fichier .pcapng et donc à une minute de trafic. On appelle "image du réseau" la matrice où chaque ligne est un paquet ARP capté et où les colonnes sont l'horodatage et les adresses sources et destinataire de chaque paquet.
Dans y_train, on associe à chaque image de réseau un 0 si elle est normale et un 1 si une attaque ARP à eu lieu dans celle ci.
Ces fichiers x_train et y_train sont ensuite à passer en entrée du programme de machine learning pour qu'il s'entraine.

Bilan de cette méthode
Comme expliqué précédemment, le problème de cryptage des paquets lorsque nous voulons effectuer le monitoring sur une borne de Polytech ne nous permet pas de tester ce modèle. En effet, celui-ci repose sur des données qui sont cryptées et donc inexploitables. Par ailleurs, nos difficultés à lancer le machine learning en temps réel ne nous a pas permis de comparer cette méthode à la première. Cependant, le pré-processing et l'entraînement du modèle fonctionne pour un usage sur un réseau privé.
Conclusion
Durant ces trois semestres, nous avons essayé de mettre en place du machine learning pour détecter des comportements malveillants sur le réseau WiFi. Le cahier des charges initial nous demandait de faire une surveillance sur du réseau WiFi et sur du réseau LoRa. Au vue de la complexité du projet nous avons au fur et à mesure du projet abandonné l’idée de traiter le réseau LoRa. Lors du premier semestre, nous nous sommes concentrés sur le réseau. Nous avons eu une mauvaise approche du projet en ne prenant pas assez en compte l’aspect machine learning du projet. Nous sommes partis dans une mauvaise direction. Ainsi pendant le premier semestre, nous avons acquis des connaissances sur le réseau et sur les outils d’analyse mais nous avons abandonné la partie que nous avions réalisée.
De ce fait, au semestre suivant, nous avons redéfini notre cahier des charges, et revu notre définition du projet. Nous avons étudié différents articles et projets pour comprendre au mieux comment nous pouvions mettre en place l’outil de machine learning pour la surveillance du réseau. Nous avons donc préparé le cahier des charges et établi les objectifs pour le dernier semestre. Nous avons pu acquérir les connaissances nécessaires en réseau et en machine learning pour se préparer pour le dernier semestre.
Ainsi, pour ce dernier semestre, d’un point de vue réseau nous avons eu à préparer le jeu de données pour entraîner le modèle de machine learning. Pour ce faire nous avons fait une écoute réseau saine où aucune attaque a été simulé et une autre écoute où nous avons injecté des paquets que nous pouvons considéré comme malveillants. D’un point de vue machine learning nous avons créé notre modèle pour l'entraîner avec notre jeu de données. Nous avons ensuite tenté d’utiliser notre modèle en temps réel. Sur ce semestre, nous avons donc gagné en compétences techniques sur l’injection de paquets et sur l’intelligence artificielle.
Bibliographie
Etat de l'art
Argus : https://github.com/jmanteau/lprims-nsm/blob/master/TP%20-%20Utilisation%20Tcpdump%20Tshark%20Argus%20Snort%20Bro.md https://www.mankier.com/1/ra?fbclid=IwAR1TznPzCRb2kxH1yEf5OsUf03rElYWdvzjmdFGzFwRr_3VQvsAZ8isf8VI#Synopsis
Partie réseau
Partie machine learning
Détection d'intrusion : https://connect.ed-diamond.com/MISC/mischs-018/vers-une-detection-d-intrusion-dynamique-et-continue-en-utilisant-les-reseaux-de-neurones?fbclid=IwAR1XAjxRdHp_NHfmqxpxHNlNYuKgTRPxV9GayYv-53j6B5ZeOn6HCxheM-Y
Keras : https://keras.io/guides
Tensorflow : https://www.tensorflow.org
Man-in-the-middle : https://www.okta.com/fr/identity-101/arp-poisoning/
Thèse sur la détection d'attaque ARP : https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3659129