IMA5 2018/2019 P06 : Différence entre versions
(→Réalisation du Projet) |
(→Documents Rendus) |
||
| (178 révisions intermédiaires par 2 utilisateurs non affichées) | |||
| Ligne 21 : | Ligne 21 : | ||
=== Matériel === | === Matériel === | ||
| − | * Un Serveur dédié | + | * Un Serveur dédié accueillant l'ensemble des services |
* Un réseau de capteurs orchestré par des Raspberry Pi | * Un réseau de capteurs orchestré par des Raspberry Pi | ||
| Ligne 46 : | Ligne 46 : | ||
=Réalisation du Projet= | =Réalisation du Projet= | ||
| − | == | + | == Premier semestre == |
Comme pour tout début de projet, nous avons passé une bonne partie de cette semaine à nous documenter et à évaluer des solutions potentielles. Le monde du front-end évoluant rapidement, il n'est pas toujours facile de s'y retrouver et de faire les choix adéquats. En l'occurrence, nous avons comparé les trois solutions qui sont Angular, React et Vue pour concevoir une interface web dynamique et moderne. Notre choix s'est finalement porté sur le framework Vue.js pour les raisons suivantes : | Comme pour tout début de projet, nous avons passé une bonne partie de cette semaine à nous documenter et à évaluer des solutions potentielles. Le monde du front-end évoluant rapidement, il n'est pas toujours facile de s'y retrouver et de faire les choix adéquats. En l'occurrence, nous avons comparé les trois solutions qui sont Angular, React et Vue pour concevoir une interface web dynamique et moderne. Notre choix s'est finalement porté sur le framework Vue.js pour les raisons suivantes : | ||
| Ligne 56 : | Ligne 56 : | ||
Concernant le framework CSS, nous avons fait simple et avons choisi Bootstrap, un standard du web depuis quelques années et qui reste d'actualité face à des alternatives en vogue telles que Foundation ou Semantic UI. Les classes proposées par ces feuilles de styles se démarquent quasi-exclusivement par la pâte graphique qu'elles apportent et non par les technologies employées qui sont identiques. | Concernant le framework CSS, nous avons fait simple et avons choisi Bootstrap, un standard du web depuis quelques années et qui reste d'actualité face à des alternatives en vogue telles que Foundation ou Semantic UI. Les classes proposées par ces feuilles de styles se démarquent quasi-exclusivement par la pâte graphique qu'elles apportent et non par les technologies employées qui sont identiques. | ||
| − | Avec ces outils en main, nous avons commencé par créer la page sur laquelle l’utilisateur arrivera s'il n'est pas déjà enregistré, la page de connexion. | + | Avec ces outils en main, nous avons commencé par créer la page sur laquelle l’utilisateur arrivera s'il n'est pas déjà enregistré, la page de connexion. Rien de particulier sur cette page, un champ pour le login et un pour le mot de passe. Nous allons tout de même ajouter un peu de dynamisme en affichant un message d'erreur en d'échec de la connexion pour mauvais login ou mot de passe. |
| − | [[Fichier:login_form.png|center| | + | [[Fichier:login_form.png|center|700px]] |
| − | |||
| − | =Documents Rendus= | + | En parallèle, nous nous sommes intéressés à Spring et de manière plus générale à Java EE. Pour pratiquer et prendre ce vaste écosystème en main, nous avons créé quelques projets avec Spring comme une API REST basique ou encore un ''controller'' plus classique capable de servir des pages web statiques. Une fois cette étape de découverte effectuée, nous sommes rentrés dans le vif du sujet. |
| + | L'idée dans un premier temps et de concevoir le gestionnaire d'utilisateurs et de prouver son fonctionnement en affichant le login de la personne enregistrée sur une page d'accueil. Pour ce faire, nous avons parcouru quelques projets existants sur Internet afin d'avoir une idée de la structure globale des projets de plus grande taille et également pour identifier les outils que nous allons devoir utiliser. En cette fin de première semaine, nous avons un bon aperçu des bibliothèques et frameworks que nous allons utiliser. A titre d'exemple, nous pensions devoir implémenter nous même le système de session et donc gérer les cookies émis et reçus mais il s'est avéré que Spring dispose d'un framework nommé Spring Security qui fournit des fonctionnalités d’authentification et d'autorisation pour les applications web. Les objectifs de la semaine suivante seront de se renseigner sur ce framework, de pratiquer l'utilisation d'une base de données et finalement d'associer ces travaux pour stocker des utilisateurs dans la base et permettre l'accès à une page sécurisée au moyen d'un formulaire de connexion. | ||
| + | |||
| + | [[Fichier:Spring-Jpa-PostgreSQL.jpg|right|700px]] | ||
| + | |||
| + | Durant cette deuxième semaine nous avons décidé de reprendre les bases de Spring pour mieux comprendre le fonctionnement des dépendances utilisées. | ||
| + | Notamment, nous nous sommes concentrés sur la communication avec une base de données en ProgreSQL via la Java Persistence API (ou JPA) couplée à l'interface Java Database Connectivity (JDBC) qui permet justement de communiquer avec une base de données, quelque soit le type (MySQL, PostgreSQL). Plus précisément, JPA permet de s'affranchir des créations de tables, de l'ajout et des modifications dans celles-ci. Il est également possible de faire des requêtes en JPQL, un langage proche de SQL mais orienté objet. Ce qu'il faut retenir de tout ça c'est que cette API va nous permettre de définir des classes vu comme des entités dans le projet et qui serviront à créer et remplir une table de données. | ||
| + | |||
| + | Grâce à ces recherches que nous avons effectuées, nous avons maintenant une meilleur idée du squelette du projet. Ainsi, pour un projet comme le nôtre il sera nécessaire d'avoir : | ||
| + | |||
| + | * Pour la base de données : | ||
| + | ** une classe par table de données | ||
| + | ** une classe qui permet à la JPA d’interagir avec la première classe décrite comme une table | ||
| + | ** un fichier application.properties pour indiquer au projet la localisation de la BDD et les identifiants pour y accéder | ||
| + | |||
| + | * De manière général pour un projet Spring Boot : | ||
| + | ** une classe pour gérer les routes de notre site Web (et donc les requêtes, qu'elles soient de type GET ou POST) | ||
| + | ** le fichier pom.xml dans le cas de l'utilisation de Maven pour spécifier la liste des dépendances | ||
| + | ** des fichiers de ressources comme des .html pour afficher les informations nécessaires à l'utilisateur | ||
| + | ** une classe Application qui permet de lancer l'application depuis le projet (il sera ultérieurement utile d'utiliser une exportation en Jar ou War pour utiliser le projet de manière indépendante) | ||
| + | |||
| + | Pour la suite du projet il est également nécessaire d'intégrer le framework Spring Security qui permet justement de gérer l'accès à différentes pages. Il est possible d'utiliser ce framework sans base de données mais il serait compliquer dans ce cas d'assurer la persistance en mémoire des utilisateurs et des rôles qui leur sont associées. Il va donc être important de faire interagir le framework Spring Security avec la base de données. | ||
| + | |||
| + | === Commit 1 et 2 === | ||
| + | |||
| + | '''Intitulé :''' "Projet Spring Boot avec gestion de base données simple et interface web pour l'ajout d'utilisateurs avec affichage des clients ajoutés" | ||
| + | |||
| + | Ce commit utilise les connaissances que nous avons acquis sur l'utilisation des bases de données. | ||
| + | Ce projet utilise l'outil de gestion d'automatisation de production Maven et a les dépendances suivantes : | ||
| + | * Spring Boot | ||
| + | * JPA pour la gestion des bases de données externes, dans notre cas | ||
| + | * Thymeleaf, un moteur de template | ||
| + | |||
| + | Il permet d'accéder à une page d'accueil qui demande à un utilisateur (quelconque pour le moment mais par la suite il devra être Admin) d'ajouter des utilisateurs à la base de données. Lorsque le bouton est pressé, les informations (pseudo et mot de passe) sont passés dans le corps d'une requête POST. Coté Java, une méthode permet de gérer les requêtes POST de cette page. Pour le moment, nous créons un objet "Customer" en lui affectant le pseudo et le mot de passe rentré par l'utilisateur. Grâce ) la méthode ''save'' fournie par notre objet CustomerRepository, nous faisons persister ces informations en base de données. Enfin, nous effectuons une redirection sur la page du formulaire avec un paramètre "ok" pour avertir du bon enregistrement. Ainsi, quand le navigateur effectuera son GET, il ajoutera "?ok" à la destination permettant donc à la template Thymeleaf grâce à une condition d'afficher un message. | ||
| + | |||
| + | Pour le commit 2, nous avons souhaité vérifier si le pseudo entré dans le formulaire n'est pas déjà présent dans la base de données. Pour ce faire, nous avons au niveau du traitement du POST ajouté quelques lignes qui vont faire une requête à la BDD. Si le résultat est "null", tout se passe comme précédemment. Dans le cas contraire, la redirection est effectué sur le formulaire avec comme paramètre "?error". Une autre condition dans la vue permet de gérer ce cas d'erreur. | ||
| + | |||
| + | === Commit 3 === | ||
| + | |||
| + | '''Intitulé :''' "Restructuration du site web avec une page d'accueil, de login et d'ajout d'utilisateur et ajout de Spring Security pour l'instant pas opérationnel" | ||
| + | |||
| + | Nous avons implanté la possibilité d'ajouter des utilisateurs avec le rôle Admin pour l'instant. En se rendant sur la page "registration", il est ainsi possible d'ajouter un utilisateur avec un mot de passe. Le serveur vérifie que le pseudo de l'utilisateur n'existe pas avant de l'ajouter. Un message permet d'indiquer à l'administrateur si l'utilisateur a bien été ajouté ou s'il existe déjà. | ||
| + | |||
| + | Les pages ont également été remaniées afin de parfaire l'expérience de la navigation. | ||
| + | Spring Security a également été ajouté même si pour le moment il ne fonctionne pas. En effet, on indique au framework que la page login est celle à utiliser pour vérifier l'utilisateur. On indique également que seul un utilisateur avec le rôle Admin peut se connecter à la page d'ajout d'utilisateurs. | ||
| + | |||
| + | Enfin, grâce à des requêtes JPQL on précise quels sont les paramètres de la base de données à utiliser pour identifier l'utilisateur qui essaie de se connecter. | ||
| + | L'enregistrement d'utilisateurs fonctionne mais pour l'instant l'entrée du rôle "ADMIN" est dupliquée ce qui sera à corriger. | ||
| + | |||
| + | === Commit 4 === | ||
| + | |||
| + | '''Intitulé :''' "Front-end : page de login et page d'accueil" | ||
| + | |||
| + | La page de login n'a pas changé depuis la semaine, elle a juste été ajoutée au Git. Néanmoins, nous avons travaillé sur une ébauche de la page de d'accueil, la page qui s'affichera après que l’utilisateur se soit enregistré. | ||
| + | |||
| + | |||
| + | [[Fichier:home_1.png|center|700px]] | ||
| + | [[Fichier:home_2.png|center|700px]] | ||
| + | |||
| + | |||
| + | Dans l'ordre, on y voit un ''header'' en haut de la page qui permettra de se déconnecter ainsi qu'un autre lien qui affichera une page de configuration avec notamment la possibilité pour un Admin de d'ajouter un utilisateur et de lui affecter un rôle. Plus bas, il s'agit d'un tableau ou chaque ligne représente un nœud avec ses informations. Il ne s'agit ici que d'un exemple, tant pour le choix des informations qui seront affichées que pour le contenu actuel des lignes. Ce tableau utilise le plugin DataTables pour jQuery et offre des fonctionnalités prêtes à l'usage comme le tri par colonne, la recherche ou encore la sélection de ligne. A ce propose, pour le moment quand des lignes sont sélectionnées ou désélectionnées, un message s'affiche dans la console avec le contenu de la ligne, montrant ainsi qu'il est possible de les recueillir. | ||
| + | |||
| + | La seconde partie de cette page concerne l'upload d'un fichier. Il sera possible prochainement de déposer un fichier dans la zone ou de cliquer dessus pour choisir un fichier dans l'explorateur. La barre de progression montrera après l'appui sur un bouton le pourcentage déjà transféré. Ce bouton n'est pas encore présent mais sera très probablement situé au dessous de la zone d'upload. | ||
| + | |||
| + | L'objectif sera de communiquer le fichier au serveur non pas seul mais avec des métadonnées (liste des nœuds concernés), ce qui fait une potentielle difficulté pour cette étape. | ||
| + | |||
| + | === Commit 5 === | ||
| + | |||
| + | '''Intitulé :''' "Spring Security Opérationnel" | ||
| + | |||
| + | Dans l'état actuel du projet, tout le monde peut se créer un compte et se connecter au site avec et la page d'accueil affiche le pseudo de l'utilisateur. Lorsque l'utilisateur n'est pas connecté, toutes les requêtes le renvoient vers la page de login. | ||
| + | D'un point de vu quantité de lignes, peu de changements majeurs ont été apportés par rapport au commit 3. En effet, les dysfonctionnements étaient plutôt causés par des éléments de configuration et plus précisément ces 2 points : | ||
| + | |||
| + | * La classe Customer doit pour être reconnu comme un utilisateur par Spring Security posséder un attribut "active" de type entier valant 0 ou 1. | ||
| + | * Ensuite, un changement a eu lieu dans la dernière version de Spring Security. Le mot de passe d'un utilisateur doit être par défaut haché avec Bcrypt dans la base de données. Apporter une telle sécurité nous paraissait futile '''durant cette phase d'apprentissage''' du framework mais finalement, il s'est avéré que de laisser des mots de passe en clair demande plus de configuration. Nous avons donc utilisé Bcrypt. | ||
| + | |||
| + | Pour terminer cette partie consacrée à la gestion des utilisateurs il va falloir travailler sur les points suivants : | ||
| + | |||
| + | * Fixer un utilisateur admin en BDD | ||
| + | * Autoriser la création de comptes seulement aux admins | ||
| + | * Créer un rôle utilisateur avec moins de privilèges (création de comptes) | ||
| + | |||
| + | === Commit 6 et 7 === | ||
| + | |||
| + | '''Intitulé :''' "Upload d'un fichier" | ||
| + | |||
| + | On continue toujours parallèlement le développement de la partie front. Ce commit intègre la possibilité d'envoyer un fichier unique associé à une liste de nœuds via une requête POST. Après avoir pris connaissance des événements écoutables au niveau de l'action de drag & drop, nous avons fait en sorte d'afficher le nom du fichier dans le cadre une fois celui-ci déposé. Dans une optique d'interactivité, nous avons fait en sorte que la bordure de la zone s'épaississe quand un fichier survole la zone. Pour stocker les données qui seront envoyées, nous avons utilisé l'objet FormData qui permet de construire un ensemble de paires clé / valeur qui représenteront les données que nous enverrons. L'avantage étant que cet objet peut être envoyé via la méthode send() de l'objet XMLHttpRequest. Ainsi au moment de l’événement "drop", nous stockons le nom du fichier et l'objet "File" qui sera converti en binaire à l'envoi. Lorsque l'utilisateur déposent plus d'un fichier dans l'espace prévu, un pop-up d'avertissement apparaît pour indiquer qu'un seul fichier ne peut être transféré. | ||
| + | |||
| + | Nous avons ensuite ajouté la possibilité de cliquer sur cette zone pour choisir le fichier dans l'explorateur. Pour ce faire, nous avons rendu invisible via le CSS un input de type file. En JS, nous observons l’événement "click" sur la zone de dépôt puis nous simulons un clic sur le input invisible faisait apparaître la fenêtre de l'explorateur. Un autre événement "change" sur l'élément input permet de recueillir le fichier et ses infos. | ||
| + | |||
| + | Il a fallu également s'attaquer aux quelques cas d'usage particuliers comme lorsque que l'utilisateur dépose ou choisi un nouveau fichier. Pour ce cas, nous avons fait le choix de remplacer le fichier existant par le nouveau. | ||
| + | |||
| + | Avant de procéder à l'envoi, il faut récupérer la liste des nœuds sélectionnés et pour ce faire, nous avons créé un "Set" qui sera passé intégré à notre instance de FormData grâce la méthode append() de cet objet. | ||
| + | |||
| + | Enfin, pour procéder à l'envoi, il suffit de cliquer sur le bouton en bas de page. Si aucun nœud n'a été sélectionné ou si aucun fichier n'a été fourni, un pop-up apparaîtra pour stipuler l'erreur. En revanche si tout se passe bien, la requête POST peut être envoyée. Dernière petite fonctionnalité, XMLHttpRequest nous permet de récupérer le nombre d'octets total à transmettre ainsi que le nombre déjà transmis ce qui est parfait pour intégrer une barre de progression. Une fois le transfert opéré, un message apparaît et la page est rechargée. | ||
| + | |||
| + | |||
| + | [[File:dropfile.gif|frame|center|alt=https://projets-ima.plil.fr/mediawiki/images/3/35/Dropfile.gif|https://projets-ima.plil.fr/mediawiki/images/3/35/Dropfile.gif]] | ||
| + | |||
| + | === Commit 8 === | ||
| + | |||
| + | '''Intitulé :''' "Optimisation de la communication avec la BDD" | ||
| + | |||
| + | Pour ce commit, nous nous sommes concentré uniquement sur la base de données et ses interactions avec Spring. Premièrement, grâce au fichier data.sql il est possible d'ajouter des entrées au lancement du serveur. Le problème étant qu'ensuite, lorsqu'on ajoute un utilisateur depuis le site internet, Spring commence par l'id '1' pour l'utilisateur alors qu'il est déjà utilisé vu que des utilisateurs ont été entrés dans la base de données au lancement. | ||
| + | Pour corriger ce problème, il est nécessaire de modifier la manière dont Hibernate va générer les id. En fait, on précise dans notre classe "Customer" que la génération est en mode automatique alors qu'il faut en fait la paramétrer. | ||
| + | |||
| + | Malgré toutes les tentatives sur les différents type de génération, nous ne sommes pas parvenu à changer dynamiquement la valeur initial de l'id. Nous avons donc choisi d'utiliser une méthode setId() qui va être appelée en même temps que setPassword() et setPseudo(). Nous utilisons la méthode count() déjà implémenter dans JpaRepository (et donc CrudRepository). Celle-ci permet de connaître le nombre d'entrées dans la base de données à chaque fois que la requête "registration" est émise. L'assignation de l'id est donc dynamique. | ||
| + | |||
| + | L'erreur qui dupliquait le champ "ADMIN" a également été corrigée. Plutôt que de créer un nouvel utilisateur à chaque requête vers "registration", on recherche le rôle "ADMIN" dans la table rôle et assigne la ligne trouvé à l'utilisateur. | ||
| + | Enfin, nous avons ajouté un utilisateur par défaut : pseudo : user / password : user, et un administrateur par défaut : pseudo : admin / password : admin.<br/> | ||
| + | Remarque : il est obligatoire de stocker le password haché dans le fichier data.sql pour que Spring puisse l'utiliser (en effet, depuis Spring Boot 5.0, il est obligatoire d'encoder le mot de passe). | ||
| + | |||
| + | === Commit 9 === | ||
| + | |||
| + | '''Intitulé :''' "Routage du site" | ||
| + | |||
| + | Nous avons implémenté la distinction entre un utilisateur classique et un administrateur. Les pages auxquelles peut accéder chaque rôle sont donc différentes : seul l'administrateur peut accéder à la page "registration"; les deux utilisateurs doivent se connecter pour accéder aux différentes pages du site. L'administrateur peut désormais préciser quel rôle aura l'utilisateur ajouté<br/> | ||
| + | Les templates sont également codés pour n'afficher que les informations dédiées au rôle qui est connecté au site internet. | ||
| + | |||
| + | === Commit 10 === | ||
| + | |||
| + | '''Intitulé :''' "Intégration du front au projet" | ||
| + | |||
| + | Ce commit consiste en l'intégration de la partie front au projet. Pour que les templates puissent utiliser les ressources dont elles ont besoin (CSS et JS), nous avons créé un dossier static contenant deux autres dossiers JS et CSS pour lesquels nous avons autorisé l'accès à tout le monde dans la configuration de Spring Security. Pour la page de login, aucun changement majeur si ce n'est la présence d'un message d'erreur qui s'affiche lorsque que le compte n'existe pas. Son apparition ou non est gérée dans la template Thymeleaf grâce à une condition sur le paramètre "erreur" de l'URL. | ||
| + | |||
| + | La page d'accueil a elle aussi été mise à jour. Seul les liens "déconnexion" et "paramètres" de la barre de navigation ont été changés. | ||
| + | Des tests sur mobile, nous ont révélé quelques soucis d'adaptation du contenu, il faudra veiller à régler ces petits défauts d'affichage. Il serait intéressant également de travailler sur la template "registration" consacrée à l'ajout d'utilisateurs. Enfin, il faudra être capable au niveau du controller Spring de récupérer le fichier envoyé depuis l'interface via la requête POST. | ||
| + | |||
| + | === Commit 11 === | ||
| + | |||
| + | '''Intitulé :''' "Sauvegarde des fichiers envoyés" | ||
| + | |||
| + | Ce commit ajoute l'enregistrement du fichier ''uploadé'' depuis l'interface web. Ce fichier se retrouve stocker dans un répertoire nommé <pseudo>_<timestamp> qui lui même est dans le dossier files. Ceci permet d'avoir un dossier unique pour chaque envoi de fichier par l'utilisateur tout en gardant une trace de son nom pour d'éventuels futurs besoin. Techniquement, la sauvegarde du fichier s'effectue en copiant par bloc de 1024 octets le binaire contenu dans la requête vers sa destination au moyen des flux Java. Pour la suite nous avons envisagé la création d'un programme annexe ''daemon'' dont le but serait de scruter la présence de nouveaux fichiers et de les transférer sur les nœuds concernés. Cette liste de nœuds sera dès le prochain commit incluse dans le dossier du fichier. On peut ensuite imaginer l'utilisation d'Ansible pour faciliter le déploiement du binaire sur les nœuds. | ||
| + | |||
| + | === Commit 12 === | ||
| + | |||
| + | '''Intitulé :''' "Amélioration du front-end" | ||
| + | |||
| + | Nous avons ajouté une page permettant de visualiser tous les utilisateurs enregistrés sous la forme d'un tableau avec leur ID, leur pseudo et leur rôle. Cette liste n'est accessible qu'aux administrateurs. | ||
| + | |||
| + | {{Alert_error|Ajouter images}} | ||
| + | |||
| + | === Commit 13 et 14 === | ||
| + | |||
| + | '''Intitulé :''' "UI : modifications mineures" | ||
| + | |||
| + | * Changement de quelques textes | ||
| + | * Mieux adapté aux mobiles : quelques ajustements sur le CSS ont été faits pour améliorer l'expérience sur les appareils mobiles. | ||
| + | * Ajout des alertes pour la page d'ajout des utilisateurs : une alerte s'affiche si le pseudo est déjà utilisé. | ||
| + | * Corrections orthographiques | ||
| + | |||
| + | === Commit 15 === | ||
| + | |||
| + | '''Intitulé :''' "Passage de pseudo à email pour les utilisateurs" | ||
| + | |||
| + | Les utilisateurs sont maintenant caractérisés par leur email et non plus par leur pseudo suite à la demande de nos encadrants. Quelques ajustement au niveau des formulaires ont du être faits. | ||
| + | |||
| + | === Commit 16 === | ||
| + | |||
| + | '''Intitulé :''' "Ajout d'une classe qui contiendra les paramètres d'une mise à jour si l'utilisateur souhaite la stocker" | ||
| + | |||
| + | Il nous a également été demandé de revoir le système permettant d'uploader des fichier depuis l'interface. L'idée est de séparer l'upload du déploiement et ainsi de pouvoir garder un historique des mises à jour qui ont été faites par chaque utilisateur afin qu'il puisse facilement réitérer ces précédentes actions. | ||
| + | |||
| + | === Commit 17 === | ||
| + | |||
| + | '''Intitulé :''' "Implémentation de l'ajout de maj" | ||
| + | |||
| + | [[Image:Make_update.png|1200px|center]] | ||
| + | |||
| + | Nous avons désiré ajouter la possibilité d'enregistrer les paramètre d'une mise à jour; c'est à dire les noeuds connectés, le nom de la mise à jour, sa date d'exécution et le fichier binaire à téléverser. | ||
| + | Nous avons donc implémenter une nouvelle classe Maj.java ainsi que son dépôt MajRepository.java qui va permettre de créer une nouvelle table maj. La table maj a en fait le même comportement que la table de rôle : elles possèdent toutes les deux une jointure multiples associé à la table customer. | ||
| + | |||
| + | Ensuite, nous avons écrit une page HTML basique permettant de tester cette classe maj et son bon fonctionnement en ce qui concerne les ajouts en BDD et la liaison à l'utilisateur qui l'a créé. | ||
| + | Par la suite, nous avons pour objectif de faire évoluer la gestion des utilisateurs par une gestion par groupes. En effet, il y a plusieurs groupes de recherche dans un laboratoire mais chaque individu d'un même groupe doit avoir accès aux mises à jour du groupe. Il faudra donc créer une classe Group.java qui sera en jointure avec la table customer '''et''' la classe maj. Ainsi les mises à jour seront visibles par tous les utilisateurs d'un même groupe de recherche. | ||
| + | |||
| + | === Commit 18 === | ||
| + | |||
| + | '''Intitulé :''' "Page home restructurée et fonctionnelle" | ||
| + | |||
| + | Nous avons enlevé le tableau des noeuds sur la page d'accueil. Elle ne comprend maintenant plus que l'espace permettant d'uploader des fichiers sur le serveur. | ||
| + | |||
| + | === Commit 19 et 20 === | ||
| + | |||
| + | '''Intitulé :''' "Mise à jour front et sauvegarde d'une configuration" | ||
| + | |||
| + | '''Intitulé :''' "Choix du fichier pour la sauvegarde d'une configuration" | ||
| + | |||
| + | Nous avons créé une nouvelle page "Paramétrer une mise à jour" découpée en deux sections. La première est un historique des mises à jour que l'utilisateur a décidé de sauvegarder. Il aura la possibilité de sélectionner l'une d'entre-elle et de relancer son déploiement. La seconde partie concerne justement la création d'une mise à jour. L'utilisateur sélectionne les noeuds concernés, entre un nom pour cette configuration, sélectionne le fichier dans la liste, entre la date (éventuellement l'heure ?) à laquelle il veut que la mise à jour soit effectuée et enfin il choisit via les deux boutons s'il veut sauvegarder cette configuration ou seulement l'appliquer sans la sauvegarder. | ||
| + | |||
| + | {{Alert_error|Ajouter images}} | ||
| + | |||
| + | |||
| + | Le bouton "Lancer la mise à jour" n'a pour l'instant aucun impact mais nous avons réfléchi au fonctionnement de la partie back-end pour mettre en place cette action. Lors de l'appuie, nous allons créer un fichier dans un dossier prévu pour les mises à jour, supposons un qu'il s'appellera "todo". Ce fichier contiendra l'ensemble des métadonnées qui ont été entrées par l'utilisateur et pour limiter l'espace disque le chemin vers le fichier à déployer. Ce fichier pourra être dans un format de représentation des données tels que JSON ou YAML bien que cela ne soit pas forcément nécessaire. Un autre programme (en Java par exemple) se chargera de scruter ce dossier pour voir si des mises à jour sont dans l'attente d'être faites. | ||
| + | |||
| + | === Commit 21 === | ||
| + | |||
| + | '''Intitulé :''' " Ergonomie du site" | ||
| + | |||
| + | Suite aux différentes remarques d'un de nos encadrants, nous avons revu quelques éléments de la partie front-end. Il s'agit principalement d'un changement au niveau du header où le bouton pour se déconnecter est maintenant plus visible sur la droite. Nous avons également profité pour faire un peu de nettoyage et d'organisation dans les fichiers. | ||
| + | |||
| + | === Commit 25 === | ||
| + | |||
| + | '''Intitulé :''' "Fichier de configuration YAML" | ||
| + | |||
| + | Dans le but de ne jamais devoir modifier le code source ou encore de devoir modifier la base de données, nous avons mis en place un fichier de configuration au format YAML qui permet dans l'état actuel des choses de créer le premier utilisateur ADMIN de l'application en renseignant son email et son mot de passe. Les lignes qui suivent sont consacrées à l'établissement de la liste des nœuds qui seront visibles depuis l'interface. | ||
| + | |||
| + | adminEmail: pfe@pfe.fr | ||
| + | adminPassword: pfepfe | ||
| + | nodes: | ||
| + | - name: AT-001 | ||
| + | ip: '85.10.201.246' | ||
| + | arch: ARM | ||
| + | - name: AT-002 | ||
| + | ip: '85.10.201.247' | ||
| + | arch: ARM | ||
| + | - name: AT-003 | ||
| + | ip: '85.10.201.248' | ||
| + | arch: ARM | ||
| + | - name: ATTTT-004 | ||
| + | ip: '85.10.201.249' | ||
| + | arch: ARM | ||
| + | |||
| + | On constate ici un objet <code>nodes</code> comprenant lui même une liste d'autres objets décrivant les informations relatives aux noeuds (nom, ip, architecture). La présence de ce fichier YAML est obligatoire pour garantir le fonctionnement de l'application. Sa lecture s'effectue au sein d'une classe possédant une méthode <code>init()</code> avec une annotation <code>@PostConstruct</code> qui lui permet de s’exécuter au démarrage du programme après toutes les inutilisations opérées en interne et qui sont nécessaires. Afin de ''parser'' ce fichier, nous avons utilisé la bibliothèque '''SnakeYAML''' qui possède la particularité intéressante (sûrement comme d'autres) de faire correspondre une classe avec un YAML. On aurait ici pour illustrer, une classe YAMLConf par exemple avec comme attributs <code>String adminEmail</code>, <code>String adminPassword</code> et <code>List<NodeYAML> nodes</code>. Il faudrait ensuite créer la classe NodeYAML de la même façon. Avec les ''getters/setters'' qui vont avec, on dispose donc d'un objet Java représentant notre fichier YAML. | ||
| + | |||
| + | === Commit 26 === | ||
| + | |||
| + | '''Intitulé :''' "Modifications front-end" | ||
| + | |||
| + | A nouveau, nous avons effectué quelques changement en terme d'apparence. Le header se retrouve un peu plus resserré vers le centre et est maintenant pourvu d'un logo permettant de revenir à la page d'accueil. A ce propos, une vraie page d'accueil a fait son apparition car jusqu'à présent il s'agissait de la page d'upload. Cette nouvelle vue accueille selon le rang de l'utilisateur les fonctionnalités auxquelles il a accès avec une courte description. | ||
| + | |||
| + | {{Alert_error|Ajouter images}} | ||
| + | |||
| + | === Commit 27 === | ||
| + | |||
| + | '''Intitulé :''' "Changement pour la configuration du réseau" | ||
| + | |||
| + | Comme nous l'avions vu dans le commit 25, la configuration du réseau se faisait au moyen d'un fichier YAML à venir déposer à la racine de l'application. Seulement, après discussion, nous avons trouvé plus judicieux de proposer cette fonctionnalité depuis l'interface web pour limiter le plus possible les interactions directes avec le serveur. De plus, cela permet à tous les administrateurs de changer cette description des noeuds (il conviendra de rediscuter avec nos encadrants d'un rang spécial éventuellement). L'upload de ce fichier s'effectue sur la page "Paramétrer une mise à jour" où un champs permet de sélectionner le fichier voulu. Un exemple est également présent juste en dessous pour montrer la syntaxe qu'il faut adopter. | ||
| + | |||
| + | nodes: | ||
| + | - name: AT-001 | ||
| + | ip: '85.10.201.246' | ||
| + | arch: ARM | ||
| + | - name: AT-002 | ||
| + | ip: '85.10.201.247' | ||
| + | arch: ARM | ||
| + | - name: AT-003 | ||
| + | ip: '85.10.201.248' | ||
| + | arch: ARM | ||
| + | - name: ATTTT-004 | ||
| + | ip: '85.10.201.249' | ||
| + | arch: ARM | ||
| + | |||
| + | Une fois le bouton "Envoyer" pressé, la modification du réseau est visible directement dans le tableau des noeuds situé plus bas. | ||
| + | |||
| + | '''Ajouter images''' | ||
| + | |||
| + | === Commit 28 === | ||
| + | |||
| + | '''Intitulé :''' "Bouton "Lancer la mise à jour" fonctionnel" | ||
| + | |||
| + | La page "Paramétrer une mise à jour" est maintenant fonctionnelle dans son intégralité. En effet, le bouton "Lancer la mise à jour" envoie maintenant une requête POST au serveur. Dans le cas d'une mise à jour anonyme (sans sauvegarde en BDD), toutes les informations relatives à la mise à jour sont envoyées. Dans le cas d'une mise à jour sauvegardée, seul le nom est envoyé via la requête. Coté back-end, deux nouvelles routes sont donc apparues permettant de gérer justement ces deux cas de figure. Pour le moment, les deux méthodes de ces routes se contentent de créer un fichier YAML dans le dossier <code>toflash</code> avec les paramètres de la mise à jour. Comme nous l'avions évoqué plus tôt, un second programme se chargera par la suite de scruter ce dossier afin de vérifier si des mises à jour doivent être effectuées. | ||
| + | |||
| + | == Second semestre == | ||
| + | |||
| + | === Commit 29, 30 & 31 === | ||
| + | |||
| + | '''Intitulé :''' "Ajout des groupes de travail" | ||
| + | |||
| + | '''Intitulé :''' "Modifications mineures de méthodes" | ||
| + | |||
| + | '''Intitulé :''' "Modifications mineures" | ||
| + | |||
| + | Il existe désormais une gestion des utilisateurs et des mises à jours par groupes de travail. En effet, notre idée est que dans un laboratoire, il existe plusieurs groupes de recherche. Ainsi, il est nécessaire que un utilisateur d'un groupe de travail puisse avoir accès aux mises à jours des autres utilisateurs du même groupe. | ||
| + | Pour cela nous avons donc créé une classe et une table "Team" (le mot-clef "group" est réservé en PostgreSQL). Celle-ci possède deux jointures multiples : une avec "Customer" pour lister les utilisateurs présents dans le groupe. La deuxième jointure est avec "Update" et remplace la jointure multiple dans "Customer" : en effet désormais les mises à jours sont par groupe et non plus par utilisateur. | ||
| + | Dorénavant lorsqu'on accède à une "Team" on peut connaitre les utilisateurs de ce groupe et savoir les mises à jours réalisés (i.e. sauvegardé) par les utilisateurs. | ||
| + | |||
| + | A faire : il reste à ajouter un groupe par défaut pour le premier utilisateur. Nous ajouterons également la possibilité de créé de nouveaux groupes et de spécifier lors de la création d'un utilisateur, le groupe auquel il appartient. | ||
| + | |||
| + | === Commit 32 === | ||
| + | |||
| + | '''Intitulé :''' "Nouvelle manière de paramétrer le réseau" | ||
| + | |||
| + | Jusqu'à présent, la configuration de réseau s'effectuée sur la page consacrée aux mises à jours et l'utilisateur devait uploader un fichier YAML représentant le réseau. Mais suite à notre soutenance intermédiaire, nous avons opté pour une configuration plus didactique directement depuis l'interface. L'utilisateur peut créer autant de noeuds qu'il le souhaite et y ajouter un ou plusieurs capteurs. L'interface lui permet également de revenir sur un noeud créé en le modifiant ou en le supprimant. Lors de l'appuie sur le bouton du dessous, une requête POST sera envoyée avec comme corps un objet JSON regroupant toutes les données. De cette façon, quiconque peut modifier le réseau sans avoir à connaitre les spécificités d'un langage de sérialisation comme le JSON ou le YAML. | ||
| + | |||
| + | A faire : il faudra s'occuper de la partie back-end pour traiter le JSON et modifier la base de données en conséquence. De plus, avec l'apparition des capteurs, il faudra modifier le contenu du tableau qui permet la sélection des noeuds lors de la création d'une mise à jour. | ||
| + | |||
| + | === Commit 33 === | ||
| + | |||
| + | '''Intitulé :''' ajout de l'interface pour ajouter des groupes | ||
| + | |||
| + | Pour compléter le travail réalisé lors du commit 29, 30 et 31, nous avons ajouté modifiant l'interface utilisateur pour prendre en compte les groupes de travail. | ||
| + | Sur la page registration.html, qui permet d'ajouter de nouveaux utilisateurs, quelques modifications ont été faite pour entrer en cohérence avec l'ajout des groupes de travail. | ||
| + | En effet, lors de la création d'un utilisateur, il est désormais nécessaire de lui fournir un groupe de travail pour pouvoir l'ajouter. | ||
| + | Pour pouvoir créer ce groupe, un formulaire est présent plus bas sur la même page. | ||
| + | |||
| + | === Commit 34 === | ||
| + | |||
| + | '''Intitulé :''' Possibilité de voir les groupes et leurs mises à jours | ||
| + | |||
| + | Ce commit corresponds également à la mise en oeuvre des groupes de travail puisque sur la page all.html qui permettait d'afficher les utilisateurs ainsi que leur rôle, il est désormais possible de visualiser les groupes de travail avec les mises à jours qui y sont faites ainsi que les identifiants des utilisateurs appartenant au groupe de travail. | ||
| + | |||
| + | === Commit 35 === | ||
| + | |||
| + | '''Intitulé :''' "Backend : configuration du réseau" | ||
| + | |||
| + | La page /registration commençait à ne plus être cohérente avec le reste du site, c'est pourquoi nous avons effectué quelques changements sur la partie front-end de manière à mieux structurer et mettre en valeur les deux sections : ajout d'un utilisateur et ajout d'un groupe. | ||
| + | |||
| + | Lors du commit 32, nous avions imaginé une nouvelle manière de paramétrer le réseau. Cette fonctionnalité est maintenant intégrée dans le haut de la page /update. Lorsque le bouton "Terminer" est pressé, si des nœuds ont été renseignés, la page envoie une requête POST au serveur avec comme corps du JSON. Du coté du controller, l'ensemble du corps est parsé grâce à l'objet ObjectMapper de la bibliothèque Jackson. Il permet de faire correspondre un fichier JSON avec un ou plusieurs objets Java. Dans notre cas, ObjectMapper s'attend à trouver une liste de NodeJSON composé des attributs name, ip, arch et d'une liste de SensorJSON avec comme seul attribut pour le moment, name. On peut ensuite parcourir cette liste de noeuds créée et enregistrer les entrées dans la base de données. | ||
| + | |||
| + | Comme nous venons de le voir, nous faisons maintenant la distinction entre les noeuds et les capteurs. Il faut donc modifier la page de création des mises à jours pour les faire apparaître. Un double foreach dans la template Thymeleaf associé a suffit pour multiplier les lignes des noeuds possédant plusieurs capteurs. | ||
| + | |||
| + | === Commit 36 === | ||
| + | |||
| + | '''Intitulé :''' Ajout du fichier qui tournera sur la Raspberry | ||
| + | |||
| + | Les Raspberry représentent les noeuds du réseaux de capteurs dans notre projet. Ce sont elles qui font faire l’interface entre les capteurs d’une part, et le serveur d’autre part. | ||
| + | La manière dont nous avons conçu notre système est que serveur va lancer un programme sur la Raspberry qui va se charger de récupérer les valeurs des capteurs et ses valeurs seront ensuite transféré jusqu’au serveur sous la forme de fichiers. | ||
| + | |||
| + | Nous avons choisi de réaliser ce programme en C. Premièrement, c’est un langage que nous maîtrisons bien, ensuite, il nous permet de rester bas niveau ce qui correspond bien pour la communication série avec les capteurs. | ||
| + | |||
| + | Le programme utilise deux fichiers différents en entrée. Le premier “config_raspberry.txt” contient la correspondance entre chaque port série et le nom du capteur qui lui est associé. | ||
| + | Par exemple “temperature_1=/dev/ttyACM0” signifie que le capteur de temperature numéro 1 est sur le port série linux /dev/ttyACM0. Cela va permettre de créer un fichier de sortie par nom de capteur ce qui sera plus facile à utiliser par le serveur pour afficher les valeurs à l’utilisateur. | ||
| + | Le deuxième fichier est “config_experimentation.txt” qui est simplement un fichier qui liste les capteurs pour lesquels les données doivent être récupérés. Ce fichier est généré par Ansible est ajouter dans le dossier avant que le serveur lance l’exécution du programme. | ||
| + | |||
| + | En sortie du programme, un fichier différent est créé pour chaque capteurs dans le dossier res. Les fichiers sont sous la forme “result_exp_mouvement_capteur.txt”. Ces fichiers sont écrits en temps réel par le programme dans chaque thread et ne sont pas modifiés par rapport aux caractères récupérés sur la liaison série. | ||
| + | En effet, lors de la réceptions des octets provenant du capteurs aucun traitement n’est fait (retour à la ligne, virgule, espace, etc.). Le choix a été fait de laisser les codeurs du programme sur le microprocesseur de faire le code en conséquence et d’ainsi pouvoir y ajouter leur propre délimiteurs. | ||
| + | |||
| + | Pour ce programme nous utilisons différents outils : | ||
| + | * la bibliothèque termios.h qui permet de modifier les caractéristiques des ports séries comme la gestion des caractères spéciaux, le baudrate, le blocage ou non de la fonction read, etc. | ||
| + | * la bibliothèque pthread.h que nous utiliserons pour créer un thread par communication série. | ||
| + | * deux fichiers de configuration : config_raspberry.txt et config_experimentation.txt qui permettent de mettre en lien de les ports séries et les capteurs à utiliser dans l'expérimentation. | ||
| + | |||
| + | Afin de mener à bien une communication avec plusieurs capteurs, ce programme est multithread : il y a un processus par communication avec une liaison série. Dans notre système on suppose que un capteur correspond à un microprocesseur et donc à une liaison série. Pour ce faire, nous utilisons la bibliothèque pthread.h qui nous permet de créer un processus à partir d’une fonction. | ||
| + | |||
| + | Ensuite, le programme est dans une boucle de lecture infinie et ne s'arrête donc jamais par lui-même. C’est le serveur qui se charge de lui indiquer quand s'arrêter en lui envoyant un signal SIGKILL. Ce signal est pris en charge par le programme et il se charge de fermer correctement les liaisons séries, les fichiers ainsi que d’arrêter les threads proprement avant de finir complètement. | ||
| + | |||
| + | Enfin, la bibliothèque termios.h est la plus utilisé puisque c’est elle qui nous permet de nous interfacer avec les liaisons série. | ||
| + | Cette bibliothèque est relativement bas niveau puisqu’elle nécessite plusieurs opérations binaires pour modifier le comportement des liaisons séries. En effet, grâce à cette bibliothèques on peut avoir accès à toutes les caractéristiques de la liaison ciblé mais aussi en modifier le comportement. | ||
| + | |||
| + | Pour notre projet, nous avons besoin d’avoir une liaison série sur laquelle on récupère les valeurs tel qu'elles arrivent ce qui n’est pas le cas par défaut sous linux. De nombreuses fioritures sont en effet ajoutés pour le confort des utilisateurs comme l’affichage des lettres tapés par l’utilisateur dans le terminal par exemple. | ||
| + | Pour se défaire de ce problème on utilise la fonction cfmakeraw() qui va fixer la valeurs de plusieurs “flags” (bits avec une signification précise) dans la structure termios. | ||
| + | Ensuite la fonction setispeed() et setospeed() nous permettent de fixer le baudrate à 9600 pour les liaisons série. | ||
| + | Cette bibliothèque nous permet finalement de changer le fonction de la fonction read(). Il existe en effet deux modes différents : canonique et non-canonique. Par défaut, la lecture est canonique, c’est à dire que la lecture est faite par ligne, celles-ci séparés par des retours chariot “\n”. Cela signifie que lors d’un read() on ne peut pas lire plus loin qu’un retour chariot. | ||
| + | Nous changeons donc ce mode (toujours grâce à cfmakeraw()) en non-canonique ce qui nous permet d’avoir une vraie lecture octet par octet et d'accéder à deux variables : VMIN et VTIME. La variable VMIN indique combien d’octets doivent avoir été reçu depuis le dernier read (octets dan le buffer) avant que celui-ci ne puisse retourner le résultat. | ||
| + | La variable VTIME quand à elle est un time-out, c’est à dire que c’est compte à rebour qui décompte à chaque fois que la fonction read() est lancé. Lorsqu’il arrive à 0, la fonction read() retourne quoiqu’il arrive. Ainsi on a toujours une lecture bloquante (on attendant un seul octet dans notre programme) mais avec un compte à rebour, ainsi chaque thread peut regarder si un signal d’arrêt de programme a été envoyé par le serveur. | ||
| + | |||
| + | Lors de l’implémentation de notre programme nous avons rencontré beaucoup de problème avec ces variables et la lecture bloquante de manière générale. Pour faire les tests nous avons travaillé sous linux et les variables ne semblent pas être prises en compte quoiqu’il arrive : la lecture n’attends pas d’avoir reçu au moins 1 octet et le compte à rebour n’est pas utilisé du tout. Cela n’est pas le cas lorsque le programme est implémenté sur la Raspberry ou le fonctionnement décrit dans le manuel de termios est bien respecté. | ||
| + | |||
| + | === Commit 37 === | ||
| + | |||
| + | '''Intitulé :''' "Modifications mineures" | ||
| + | |||
| + | Sur la page des expérimentations (/update), nous avons supprimé, car peu utile, le bouton permettant de lancer une expérimentation de manière anonyme sans enregistrement en BDD. Sur cette même page, nous avons ajouté dans le formulaire de création de la mise à jour un champ permettant de renseigner la durée de l'expérimentation et nous avons modifié celui pour la date en y ajoutant l'heure. | ||
| + | |||
| + | Lorsque une mise à jour est lancée ou relancée depuis la page, le serveur va vérifier la cohérence de la date et la modifier dans le cas ou celle-ci se trouve dans le passé en y mettant la date actuelle du serveur. | ||
| + | |||
| + | === Docker === | ||
| + | |||
| + | ==== Les débuts ==== | ||
| + | |||
| + | Lorsqu'une expérimentation est lancée, un fichier qui lui est propre est créé dans le dossier "toflash". Un programme annexe en cours d'écriture se charge d'exploiter ce fichier pour compiler les sources puis flasher les différents appareils. Mais selon l'architecture des dispositifs, il faut choisir la toolchain de compilation adaptée. Nous avons commencé par écrire un Dockerfile permettant la compilation d'un programme pour ARM. L'idée à terme serait d'avoir une image pour chaque architecture ce qui permet une maintenance plus facile en évitant d'avoir plusieurs versions de GCC. | ||
| + | |||
| + | Un Dockerfile se trouve dans le répertoire ''/home/pifou/compiler/arm_compiler'' et l'image se crée avec la commande : | ||
| + | |||
| + | docker build -t arm_compiler . | ||
| + | |||
| + | Pour pouvoir compiler notre porgramme, il faut créer un conteneur avec cette image de cette façon : | ||
| + | |||
| + | docker run --rm -v /home/pifou/exp:/exp -e SRC_NAME="main.c" -e SRC_DIR="exp1" arm_compiler | ||
| + | |||
| + | L'option --rm permet de supprimer le conteneur une fois la compilation terminée, le volume (-v) spécifie le dossier où se trouve les sources sur la machine hôte ainsi que le dossier de réception du binaire. On affecte ensuite deux valeurs pour les variables d'environnements SRC_NAME et SRC_DIR avec l'option -e pour respectivement donner le nom du fichier à compiler et dans quelle dossier de /exp il se situe. Pour le moment, le cas des projets avec Makefile n'est pas géré. Nous avons l'idée pour généraliser le fonctionnement mais nous ne savons pas comment détecter le fichier de sortie produit. | ||
| + | |||
| + | Le Dockerfile se présente comme ceci : | ||
| + | |||
| + | FROM debian:latest | ||
| + | RUN apt-get update | ||
| + | RUN apt-get install -y python2.7 python-pip gcc-arm-none-eabi && pip install mbed-cli | ||
| + | WORKDIR /arm | ||
| + | COPY ./start.sh /arm | ||
| + | RUN chmod +x ./start.sh | ||
| + | ENTRYPOINT ./start.sh | ||
| + | |||
| + | Ce Dockerfile était au départ prévu pour gérer les projets Mbed d'où la présence de paquets supplémentaires. Concrètement, à la création le conteneur possédera un dossier /arm dans lequel un fichier bash sera copié depuis la machine hôte pour ensuite être exécuté grâce à la directive ENTRYPOINT. Ce fichier start.sh contient les commandes nécessaires pour compiler le fichier. Par la suite, c'est lui qui fera la différence entre un projet à fichier unique, un zip avec Makefile ou même une adresse de dépôt git. | ||
| + | |||
| + | ==== Suite ==== | ||
| + | |||
| + | Finalement, nous avons décidé que cette image soit celle qui compile des projets Mbed. Pour ce faire, nous avons dans l'image importé un projet exemple qui servira de base pour construire le binaire. Le fichier à compiler vient donc remplacer le main.cpp d'exemple et on peut ensuite compiler le projet. Pour accélérer le processus, nous procédons à la compilation des sources Mbed à la création du conteneur donc une fois, au build de l'image. | ||
| + | |||
| + | Le Dockerfile change légèrement pour devenir : | ||
| + | |||
| + | FROM debian:latest | ||
| + | RUN apt-get update | ||
| + | RUN apt-get install -y python2.7 python-pip gcc-arm-none-eabi && pip install mbed-cli | ||
| + | WORKDIR /arm | ||
| + | RUN mbed import https://github.com/ARMmbed/mbed-os-example-blinky && \ | ||
| + | cd mbed-os-example-blinky && \ | ||
| + | mbed compile -t GCC_ARM -m NUCLEO_F401RE && \ | ||
| + | rm main.cpp && \ | ||
| + | cd .. | ||
| + | COPY ./start.sh /arm | ||
| + | RUN chmod +x ./start.sh | ||
| + | ENTRYPOINT ./start.sh | ||
| + | |||
| + | Au niveau du script Bash, quelques lignes sont nécessaires pour produire le binaire : | ||
| + | |||
| + | #!/bin/bash | ||
| + | echo "Compilation de : " $SRC_NAME | ||
| + | cp /exp/$SRC_DIR/$SRC_NAME /arm/mbed-os-example-blinky/main.cpp | ||
| + | cd ./mbed-os-example-blinky | ||
| + | mbed compile -t GCC_ARM -m NUCLEO_F401RE | ||
| + | cd ./BUILD/NUCLEO_F401RE/GCC_ARM | ||
| + | mv mbed-os-example-blinky.bin out.bin | ||
| + | cp out.bin /exp/$SRC_DIR/ | ||
| + | |||
| + | === Script Ansible === | ||
| + | |||
| + | ==== Les débuts ==== | ||
| + | |||
| + | Ansible est un utilitaire écrit en Python permettant via le protocole SSH de gérer et configurer des ensembles d'ordinateurs qui seront dans notre cas les noeuds du réseaux, des Raspberry Pi. Le script Ansible que nous avons écrit sera lancé et paramétré par le programme C. Dans le code ci-dessous, le programme de lecture série est pour le moment remplacé par un programme (while) qui tourne en boucle et ne fait rien. | ||
| + | |||
| + | Le lancement du script s'effectue grâce à la commande suivante qui n'est qu'un exemple de ce que le programme C pourrait exécuter. | ||
| + | |||
| + | ansible-playbook /etc/ansible/roles/test.yml -i /etc/ansible/exp_42.hosts -e "servernames=exp_42 exp_duration=3600 binary_dir=admin_1550420007" | ||
| + | |||
| + | Cette commande prend en argument un script YAML (comme celui dessous) et accepte plusieurs options comme -i pour donner le fichier d'inventaire contenant les IPs des nœuds ou -e pour créer des variables qui seront accessibles dans le playbook. | ||
| + | |||
| + | --- | ||
| + | |||
| + | - hosts: "<nowiki>{{ servernames }}</nowiki>" | ||
| + | |||
| + | tasks: | ||
| + | |||
| + | - name: "Création du dossier de résultats" | ||
| + | file: | ||
| + | path: /home/pi/<nowiki>{{ servernames }}</nowiki>/res | ||
| + | state: directory | ||
| + | recurse: yes | ||
| + | |||
| + | On commence par indiquer le fichier hosts sur lequel appliquer ce script. On crée ensuite la première tâche qui aura pour effet de créer un dossier exp_42 avec dedans un autre dossier res si l'on garde l'exemple vu plus haut. | ||
| + | |||
| + | - name: "Copie du fichier de lecture série" | ||
| + | copy: | ||
| + | src: ~/pfe/while | ||
| + | dest: /home/pi/<nowiki>{{ servernames }}</nowiki>/while | ||
| + | |||
| + | On copie l’exécutable qui viendra produire les résultats par lecture série. | ||
| + | |||
| + | - name: "Copie du binaire pour le(s) capteur(s)" | ||
| + | copy: | ||
| + | src: ~/pfe/files/<nowiki>{{ binary_dir }}</nowiki>/out.bin | ||
| + | dest: /home/pi/<nowiki>{{ servernames }}</nowiki>/out.bin | ||
| + | |||
| + | On copie le binaire produit par le conteneur Docker sur le nœud. | ||
| + | |||
| + | - name: "Lancement du programme de lecture série" | ||
| + | command: /home/pi/<nowiki>{{ servernames }}</nowiki>/while | ||
| + | async: 3000000 | ||
| + | poll: 0 | ||
| + | |||
| + | Il manque ici, avant de lancer le programme de lecture série, toute la partie qui concerne le flashage des capteurs mais celle-ci arrivera un peu plus tard. | ||
| + | Cette tâche ci lance donc le programme de manière asynchrone pendant une durée arbitraire suffisamment longue. Nous aurions pu mettre directement la durée souhaitée de l'expérience mais dans ce cas, nous n'aurions pas été certain après la pause (tâche ci-dessous) que le programme ce soit réellement terminé. Une autre solution aurait été d'ajouter quelques secondes à la pause. | ||
| + | |||
| + | - name: "Exp en cours ..." | ||
| + | pause: | ||
| + | seconds: "<nowiki>{{ exp_duration }}</nowiki>" | ||
| + | |||
| + | L’exécution du script se met en pause pendant la durée de l'expérience. | ||
| + | |||
| + | - name: "Kill de l'application" | ||
| + | shell: pkill while | ||
| + | |||
| + | Le programme de lecture série est stoppé. | ||
| + | |||
| + | - name: "Récupération des noms des résultats" | ||
| + | shell: (cd /home/pi/<nowiki>{{ servernames }}</nowiki>/res; find . -maxdepth 1 -type f) | cut -d'/' -f2 | ||
| + | register: files_to_copy | ||
| + | |||
| + | - name: "Copie des résultats sur le serveur" | ||
| + | fetch: | ||
| + | src: /home/pi/<nowiki>{{ servernames }}</nowiki>/res/<nowiki>{{ item }}</nowiki> | ||
| + | dest: /home/antoine/pfe_results/<nowiki>{{ servernames }}</nowiki>/<nowiki>{{ ansible_host }}</nowiki>/ | ||
| + | flat: yes | ||
| + | with_items: "<nowiki>{{ files_to_copy.stdout_lines }}</nowiki>" | ||
| + | |||
| + | On va venir ici rapatrier les résultats sur le serveur. Comme la commande fetch ne peut copier qu'un seul fichier et non tous les fichiers d'un dossier, il faut commencer par récupérer la liste des fichiers que l'on vient stocker dans une variable (files_to_copy) accessible dans tout le script. La tâche qui suit se charge d'effectuer le fetch dans une boucle qui parcourt l'ensemble des fichiers de résultats. | ||
| + | |||
| + | - name: "Suppression du dossier sur le noeud" | ||
| + | shell: rm -rf /home/pi/<nowiki>{{ servernames }}</nowiki> | ||
| + | |||
| + | Finalement, nous pouvons supprimer le dossier concernant l'expérimentation. | ||
| + | |||
| + | === Programme C : lecture, compilation et flashage === | ||
| + | |||
| + | Pour ce que nous avions à faire, un langage de haut niveau n'était pas une nécessité, nous avons donc opté pour le C. Nous l'avons déjà évoqué mais pour rappel ce programme agira comme un démon et viendra scruter régulièrement (tous les 10s pour le moment) le dossier "toflash" pour savoir si une expérimentation doit se faire ou non. Pour ne pas alourdir cette page de plus de 300 lignes de codes, nous allons plutôt décrire les différentes étapes qu'effectue le programme. | ||
| + | |||
| + | Le main() est une simple boucle while infinie dans la quelle on retrouve une fonction check_files() suivi d'un sleep de 10 secondes. | ||
| + | |||
| + | La fonction check_files() ouvre dans un premier temps le dossier "toflash" puis va parcourir l'ensemble des fichiers qu'il contient. Pour chaque fichier, nous créons une structure regroupant l'ensemble des données du fichier YAML. | ||
| + | |||
| + | typedef struct node { | ||
| + | char *ip; | ||
| + | char *sensors[MAX_SENSORS]; | ||
| + | int n_sensors; | ||
| + | } Node; | ||
| + | |||
| + | typedef struct experiment { | ||
| + | int exp_id; | ||
| + | int n_nodes; | ||
| + | char *date; | ||
| + | char *file; | ||
| + | char *duration; | ||
| + | char *name; | ||
| + | char *arch; | ||
| + | char *dir; | ||
| + | Node nodes[MAX_NODES]; | ||
| + | } Experiment; | ||
| + | |||
| + | Cette structure est remplie par la fonction read_file() qui elle même va appeler pour chaque ligne du fichier la fonction process_line() qui va se charger réellement de compléter la structure. Ça se complique un peu pour la ligne des nœuds. Pour celle-ci, nous avons choisi de créer une autre structure qui contiendra les informations d'un nœud et le nom de ses capteurs. Il faut donc vérifier à chaque fois s'il faut ajouter un nouveau noeud à la liste ou bien simplement ajouter un capteur à un nœud existant. Cette manière de regrouper sera utile lors du déploiement des binaires. | ||
| + | |||
| + | Lorsque la structure est remplie, on peut maintenant procéder à l'analyse de ses données avec la fonction process_exp(). L'élément déterminant est la date de l'expérimentation. Si le timestamp de celle-ci est inférieur ou égal à la date et heure actuelle, la fonction continue et dans le contraire elle retourne 1 et la structure est libérée en mémoire puis on passe au fichier suivant s'il y en a un. | ||
| + | |||
| + | Dans le cas où le déploiement doit s'effectuer, on commence par regarder l'architecture des capteurs et on lance la compilation via le bon conteneur Docker grâce à la fonction system() qui à l'avantage d'être bloquante. Nous avons conscience que cette fonction n'est pas toujours recommandée mais pour cet usage elle est suffisante. Viens ensuite l'étape où nous allons via SSH créer un dossier avec un fichier sur tous les noeuds en indiquant la liste des capteurs concernés. Cette information sera utile pour le programme de lecture série afin de faire la correspondance entre le nom et lé périphérique dans /dev. Cette opération n'est pas assez générique pour être faite avec Ansible vu que le fichier sera différent. Finalement, process_exp() va lancer le script Ansible mais cette fois de manière asynchrone en utilisant la fonction fork(). En effet, nous ne pouvons pas nous permettre d'attendre la fin de l'expérimentation, celle-ci pouvant être très longue. | ||
| + | |||
| + | === Programme C : lecture et enregistrement des données d'un ou plusieurs ports séries === | ||
| + | |||
| + | On utilise une fonction générique appelé read_file_by_line() qui va lire le fichier qu’on lui indique et mettre chaque ligne dans une case d’un tableau de caractère indiqué lui aussi. | ||
| + | Cette fonction est utilisé pour lire config_raspberry.txt mais aussi pour config_experimentation.txt. Ensuite, il reste à récupérer les ports de chaque capteurs qui doivent être lu. pour cela on utilise la fonction get_ports_to_read() qui utilisent les deux tableaux de lignes créés précédemment et faire la correspondance entre les deux. | ||
| + | On prend un capteur à lire puis on regarde dans la liste du fichier des ports séries si ce capteur est présent. Si celui-ci l’est, on l’indique dans un troisième tableau de sortie qui contients les ports à lire lors de cette expérimentation. On fait de même avec tous les capteurs qui sont demandés pour l'expérimentation. | ||
| + | Une fois la liste des ports séries connus et donc le nombre à lire, on peut créer autant de threads que nécessaire. | ||
| + | |||
| + | |||
| + | void * start(void * sensorAndPort){ | ||
| + | int pt = set_serial((SensorAndPort *) sensorAndPort); | ||
| + | save_data(pt, ((SensorAndPort *)sensorAndPort)->sensor); | ||
| + | reset_serial(pt); | ||
| + | pthread_exit(NULL); | ||
| + | } | ||
| + | Grâce à la bibliothèque pthread.h, on va créer un thread ( ou processus léger) en utilisant la fonction pthread_create(). Celle-ci prend en paramètre la fonction start() ci-dessus qui va se charger de lancer plusieurs fonctions. Premièrement set_serial() qui va se charger de modifier le comportement des liaisons séries : | ||
| + | int set_serial(SensorAndPort* sensorAndPort){ | ||
| + | char *device = sensorAndPort->port; | ||
| + | printf("device : %s\n",device); | ||
| + | int pt = open(device, O_RDWR | O_NOCTTY | O_SYNC); // retourne une erreur si le terminal n'est connecté à rien (pas de STM32 ni de Arduino dans notre cas) | ||
| + | if(pt == -1){ | ||
| + | create_error_file(sensorAndPort->sensor, "impossible de se connecter au port série, veuillez vérifier le microprocesseur et la raspberry"); | ||
| + | perror("in set_serial(...) - open"); | ||
| + | pthread_exit(NULL); | ||
| + | } | ||
| + | //ioctl(pt, I_SRDOPT, RMSGD); | ||
| + | tcgetattr(pt, &old); | ||
| + | tcgetattr(pt, &tty); | ||
| + | |||
| + | cfsetispeed(&tty,B9600); // la valeur du baudrate est fixé à 9600 baud | ||
| + | cfsetospeed(&tty,B9600); | ||
| + | |||
| + | tty.c_cc[VMIN] = 1; // Un caractère doit avoir été reçu dans le buffer pour que la fonction read() retourne quelque chose | ||
| + | tty.c_cc[VTIME] = 10; // Une valeur est fixé pour le time-out : à la fin de celui-ci read() retourne une valeur quoiqu'il arrive | ||
| + | |||
| + | tty.c_cflag |= CLOCAL; | ||
| + | tty.c_cflag |= CREAD; | ||
| + | cfmakeraw(&tty); // passage de la liaison série en mode non canonique et suppression des fioritures pour les utilisateurs d'un terminal classique | ||
| + | |||
| + | sleep(1); // nécessaire pour que le flush soit fait | ||
| + | if(tcflush(pt, TCIFLUSH)==-1){ | ||
| + | perror("in set_serial(...) - tcflush"); | ||
| + | pthread_exit(NULL); | ||
| + | } | ||
| + | if(tcsetattr(pt, TCSANOW, &tty)==-1){ | ||
| + | perror("in set_serial(...) - tcsetattr"); | ||
| + | pthread_exit(NULL); | ||
| + | } | ||
| + | if(cfgetispeed(&tty)!=B9600) | ||
| + | { | ||
| + | perror("in set_serial(...) - cfgetispeed"); | ||
| + | pthread_exit(NULL); | ||
| + | } | ||
| + | return pt; | ||
| + | } | ||
| + | |||
| + | Ensuite, elle va lancer la fonction save_data() et reset_serial(). Cette dernière est utilisé en fin de lecture pour rétablir les paramètres de la liaison série tel qu’ils étaient avant le programme. | ||
| + | La fonction save_data() va créer le fichier avec les valeurs du capteurs qui sont reçues. Une fois le fichier de sortie créé, une boucle infinie est créée dans laquelle on lit caractère par caractère la liaison série. Chaque caractère est immédiatement ajouté au fichier. | ||
| + | Lorsque le signal d’arrêt du programme est reçu, la boucle infinie est quittée, le fichier de sortie est fermée puis la communication série est fermée et enfin le thread est arrêté. | ||
| + | |||
| + | === Commit 40 === | ||
| + | |||
| + | '''Intitulé :''' "Spring : ajouts mineurs" | ||
| + | |||
| + | * Ajout de l'architecture des capteurs dans le fichier d'expérimentation YAML | ||
| + | * On ne peut maintenant sélectionner que des nœuds de même architecture pour une expérience | ||
| + | * Ajout du nom du répertoire où se trouve le fichier à compiler | ||
| + | * Vérification des fichiers pour avertir si un fichier est déjà nommé de la même manière lors de l'upload d'un nouveau fichier | ||
| + | * Passage de l'application sur le port 80 | ||
| + | |||
| + | = Annexes = | ||
| + | |||
| + | '''''Ferions-nous pas une partie un peu plus générale sur des sujets qui ont moins leur place dans les rapports hebdomadaires ?''''' | ||
| + | |||
| + | Exemples : | ||
| + | |||
| + | * Détail de la classe de configuration de Spring Security | ||
| + | * Détail de l'architecture du projet | ||
| + | * Parler de Thymeleaf | ||
| + | |||
| + | === Fonctionnement du projet Spring Boot === | ||
| + | |||
| + | La gestion du routage des pages internet et de l'affichage des pages internet est géré par le fichier WebMvcConfig.java. Il gère les différents appels de l'utilisateur par les méthodes POST ou GET aux pages internet, ou aux actions de boutons. | ||
| + | Ce fichier permet également d'envoyer des informations pour que Thymeleaf les utilise et affiche des éléments dynamiquement. | ||
| + | |||
| + | Ensuite, on utilise SecurityConfig.java pour gérer les accès aux pages de données en fonction du rôle des utilisateurs. | ||
| + | |||
| + | {{Alert_error|A continuer + schema}} | ||
| + | |||
| + | = Documents Rendus = | ||
| + | |||
| + | * Gitlab : https://archives.plil.fr/aduqueno/PFE_IMA5_2018_2019_P06 | ||
| + | * Rendu intermédiaire : [[Fichier:PFE_06_Rapport_Intermediaire.pdf]] | ||
| + | * Rendu intermédiaire (slides) : [[Fichier:Slides_decembre_pfe06.pdf]] | ||
| + | * Rendu final: [[Fichier:PFE06_Final.pdf]] | ||
Version actuelle datée du 26 février 2019 à 17:14
Sommaire
- 1 Présentation générale
- 2 Préparation du projet
- 3 Réalisation du Projet
- 3.1 Premier semestre
- 3.1.1 Commit 1 et 2
- 3.1.2 Commit 3
- 3.1.3 Commit 4
- 3.1.4 Commit 5
- 3.1.5 Commit 6 et 7
- 3.1.6 Commit 8
- 3.1.7 Commit 9
- 3.1.8 Commit 10
- 3.1.9 Commit 11
- 3.1.10 Commit 12
- 3.1.11 Commit 13 et 14
- 3.1.12 Commit 15
- 3.1.13 Commit 16
- 3.1.14 Commit 17
- 3.1.15 Commit 18
- 3.1.16 Commit 19 et 20
- 3.1.17 Commit 21
- 3.1.18 Commit 25
- 3.1.19 Commit 26
- 3.1.20 Commit 27
- 3.1.21 Commit 28
- 3.2 Second semestre
- 3.2.1 Commit 29, 30 & 31
- 3.2.2 Commit 32
- 3.2.3 Commit 33
- 3.2.4 Commit 34
- 3.2.5 Commit 35
- 3.2.6 Commit 36
- 3.2.7 Commit 37
- 3.2.8 Docker
- 3.2.9 Script Ansible
- 3.2.10 Programme C : lecture, compilation et flashage
- 3.2.11 Programme C : lecture et enregistrement des données d'un ou plusieurs ports séries
- 3.2.12 Commit 40
- 3.1 Premier semestre
- 4 Annexes
- 5 Documents Rendus
Présentation générale
Conception et développement d'un système de gestion d'un réseau de capteur.
Description
Notre projet s'inscrit dans le cadre d'un projet de recherche à l'IRCICA sur un réseau de capteurs à large échelle (100 noeuds). Face à un réseau de cette ampleur, il est intéressant de développer une solution de maintenance à distance de ce réseau. Il sera bien plus aisé pour les chercheurs de tester leurs hypothèses en déployant rapidement leurs logicielles sur tout ou une partie des noeuds disponibles grâce à des fonctionnalités telles que la sélection d'une partie du réseau ou encore la mise à jour d'un ensemble de capteurs de même type / architecture.
Objectifs
L'objectif de notre travail consiste pour cela à développer simultanément le front-office et le back-office. La partie front sera réalisée en utilisant les technologies web classiques. La partie back-end sera constituée d'un ensemble de webservices en différents langages permettant la communication réseau et la gestion d'une base de données de noeuds et capteurs. Il faudra y développer des services classiques comme la gestion des utilisateurs et des services spécifiques (compilation du code source, téléchargement à distance du logiciel sur les noeuds). La partie front-end aura vocation à être utilisée par des utilisateurs externes au projet et devra donc être ergonomique et facile de compréhension. Elle devra également être fonctionnel et modifiable facilement.
Préparation du projet
Cahier des charges
Choix techniques : matériel et logiciel
Matériel
- Un Serveur dédié accueillant l'ensemble des services
- Un réseau de capteurs orchestré par des Raspberry Pi
Logiciel
- Ansible pour faciliter le déploiement des binaires sur les noeuds
- La plateforme Java EE pour la partie back-end couplé au framework Spring
- Une base de données PostgreSQL dans un premier temps pour assurer la persistance des données
- Une partie front-end moderne basée sur le framework Vue.js et sur un framework CSS tel que Bootsrap, Semantic UI ou Foundation pour ne citer que les plus connus
Liste des tâches à effectuer
- Comparaison et documentation sur les frameworks web de création d'interface (Angular, React, Vue ...)
- Documentation sur Spring et Java EE en général
- Configuration des routes du projet Spring (racine, connexion dans un premier temps)
- Création d'une interface utilisateur (front-end)
- Page de connexion pour commencer
- Implémentation d'un gestionnaire d'utilisateurs
- Création d'une base de données pour gérer les noeuds
- Implémentation du service d’envoi des fichiers de mise à jour
Calendrier prévisionnel
Réalisation du Projet
Premier semestre
Comme pour tout début de projet, nous avons passé une bonne partie de cette semaine à nous documenter et à évaluer des solutions potentielles. Le monde du front-end évoluant rapidement, il n'est pas toujours facile de s'y retrouver et de faire les choix adéquats. En l'occurrence, nous avons comparé les trois solutions qui sont Angular, React et Vue pour concevoir une interface web dynamique et moderne. Notre choix s'est finalement porté sur le framework Vue.js pour les raisons suivantes :
- Une prise en main rapide : sans même avoir suivi un cours spécifique à Vue.js, le choix pertinent des mot-clés aide la compréhension
- Des performances supérieures à ses concurrents sur bien des aspects
- Sa légèreté principalement causée par son fonctionnement par plugins
Concernant le framework CSS, nous avons fait simple et avons choisi Bootstrap, un standard du web depuis quelques années et qui reste d'actualité face à des alternatives en vogue telles que Foundation ou Semantic UI. Les classes proposées par ces feuilles de styles se démarquent quasi-exclusivement par la pâte graphique qu'elles apportent et non par les technologies employées qui sont identiques.
Avec ces outils en main, nous avons commencé par créer la page sur laquelle l’utilisateur arrivera s'il n'est pas déjà enregistré, la page de connexion. Rien de particulier sur cette page, un champ pour le login et un pour le mot de passe. Nous allons tout de même ajouter un peu de dynamisme en affichant un message d'erreur en d'échec de la connexion pour mauvais login ou mot de passe.

En parallèle, nous nous sommes intéressés à Spring et de manière plus générale à Java EE. Pour pratiquer et prendre ce vaste écosystème en main, nous avons créé quelques projets avec Spring comme une API REST basique ou encore un controller plus classique capable de servir des pages web statiques. Une fois cette étape de découverte effectuée, nous sommes rentrés dans le vif du sujet.
L'idée dans un premier temps et de concevoir le gestionnaire d'utilisateurs et de prouver son fonctionnement en affichant le login de la personne enregistrée sur une page d'accueil. Pour ce faire, nous avons parcouru quelques projets existants sur Internet afin d'avoir une idée de la structure globale des projets de plus grande taille et également pour identifier les outils que nous allons devoir utiliser. En cette fin de première semaine, nous avons un bon aperçu des bibliothèques et frameworks que nous allons utiliser. A titre d'exemple, nous pensions devoir implémenter nous même le système de session et donc gérer les cookies émis et reçus mais il s'est avéré que Spring dispose d'un framework nommé Spring Security qui fournit des fonctionnalités d’authentification et d'autorisation pour les applications web. Les objectifs de la semaine suivante seront de se renseigner sur ce framework, de pratiquer l'utilisation d'une base de données et finalement d'associer ces travaux pour stocker des utilisateurs dans la base et permettre l'accès à une page sécurisée au moyen d'un formulaire de connexion.

Durant cette deuxième semaine nous avons décidé de reprendre les bases de Spring pour mieux comprendre le fonctionnement des dépendances utilisées. Notamment, nous nous sommes concentrés sur la communication avec une base de données en ProgreSQL via la Java Persistence API (ou JPA) couplée à l'interface Java Database Connectivity (JDBC) qui permet justement de communiquer avec une base de données, quelque soit le type (MySQL, PostgreSQL). Plus précisément, JPA permet de s'affranchir des créations de tables, de l'ajout et des modifications dans celles-ci. Il est également possible de faire des requêtes en JPQL, un langage proche de SQL mais orienté objet. Ce qu'il faut retenir de tout ça c'est que cette API va nous permettre de définir des classes vu comme des entités dans le projet et qui serviront à créer et remplir une table de données.
Grâce à ces recherches que nous avons effectuées, nous avons maintenant une meilleur idée du squelette du projet. Ainsi, pour un projet comme le nôtre il sera nécessaire d'avoir :
- Pour la base de données :
- une classe par table de données
- une classe qui permet à la JPA d’interagir avec la première classe décrite comme une table
- un fichier application.properties pour indiquer au projet la localisation de la BDD et les identifiants pour y accéder
- De manière général pour un projet Spring Boot :
- une classe pour gérer les routes de notre site Web (et donc les requêtes, qu'elles soient de type GET ou POST)
- le fichier pom.xml dans le cas de l'utilisation de Maven pour spécifier la liste des dépendances
- des fichiers de ressources comme des .html pour afficher les informations nécessaires à l'utilisateur
- une classe Application qui permet de lancer l'application depuis le projet (il sera ultérieurement utile d'utiliser une exportation en Jar ou War pour utiliser le projet de manière indépendante)
Pour la suite du projet il est également nécessaire d'intégrer le framework Spring Security qui permet justement de gérer l'accès à différentes pages. Il est possible d'utiliser ce framework sans base de données mais il serait compliquer dans ce cas d'assurer la persistance en mémoire des utilisateurs et des rôles qui leur sont associées. Il va donc être important de faire interagir le framework Spring Security avec la base de données.
Commit 1 et 2
Intitulé : "Projet Spring Boot avec gestion de base données simple et interface web pour l'ajout d'utilisateurs avec affichage des clients ajoutés"
Ce commit utilise les connaissances que nous avons acquis sur l'utilisation des bases de données. Ce projet utilise l'outil de gestion d'automatisation de production Maven et a les dépendances suivantes :
- Spring Boot
- JPA pour la gestion des bases de données externes, dans notre cas
- Thymeleaf, un moteur de template
Il permet d'accéder à une page d'accueil qui demande à un utilisateur (quelconque pour le moment mais par la suite il devra être Admin) d'ajouter des utilisateurs à la base de données. Lorsque le bouton est pressé, les informations (pseudo et mot de passe) sont passés dans le corps d'une requête POST. Coté Java, une méthode permet de gérer les requêtes POST de cette page. Pour le moment, nous créons un objet "Customer" en lui affectant le pseudo et le mot de passe rentré par l'utilisateur. Grâce ) la méthode save fournie par notre objet CustomerRepository, nous faisons persister ces informations en base de données. Enfin, nous effectuons une redirection sur la page du formulaire avec un paramètre "ok" pour avertir du bon enregistrement. Ainsi, quand le navigateur effectuera son GET, il ajoutera "?ok" à la destination permettant donc à la template Thymeleaf grâce à une condition d'afficher un message.
Pour le commit 2, nous avons souhaité vérifier si le pseudo entré dans le formulaire n'est pas déjà présent dans la base de données. Pour ce faire, nous avons au niveau du traitement du POST ajouté quelques lignes qui vont faire une requête à la BDD. Si le résultat est "null", tout se passe comme précédemment. Dans le cas contraire, la redirection est effectué sur le formulaire avec comme paramètre "?error". Une autre condition dans la vue permet de gérer ce cas d'erreur.
Commit 3
Intitulé : "Restructuration du site web avec une page d'accueil, de login et d'ajout d'utilisateur et ajout de Spring Security pour l'instant pas opérationnel"
Nous avons implanté la possibilité d'ajouter des utilisateurs avec le rôle Admin pour l'instant. En se rendant sur la page "registration", il est ainsi possible d'ajouter un utilisateur avec un mot de passe. Le serveur vérifie que le pseudo de l'utilisateur n'existe pas avant de l'ajouter. Un message permet d'indiquer à l'administrateur si l'utilisateur a bien été ajouté ou s'il existe déjà.
Les pages ont également été remaniées afin de parfaire l'expérience de la navigation. Spring Security a également été ajouté même si pour le moment il ne fonctionne pas. En effet, on indique au framework que la page login est celle à utiliser pour vérifier l'utilisateur. On indique également que seul un utilisateur avec le rôle Admin peut se connecter à la page d'ajout d'utilisateurs.
Enfin, grâce à des requêtes JPQL on précise quels sont les paramètres de la base de données à utiliser pour identifier l'utilisateur qui essaie de se connecter. L'enregistrement d'utilisateurs fonctionne mais pour l'instant l'entrée du rôle "ADMIN" est dupliquée ce qui sera à corriger.
Commit 4
Intitulé : "Front-end : page de login et page d'accueil"
La page de login n'a pas changé depuis la semaine, elle a juste été ajoutée au Git. Néanmoins, nous avons travaillé sur une ébauche de la page de d'accueil, la page qui s'affichera après que l’utilisateur se soit enregistré.


Dans l'ordre, on y voit un header en haut de la page qui permettra de se déconnecter ainsi qu'un autre lien qui affichera une page de configuration avec notamment la possibilité pour un Admin de d'ajouter un utilisateur et de lui affecter un rôle. Plus bas, il s'agit d'un tableau ou chaque ligne représente un nœud avec ses informations. Il ne s'agit ici que d'un exemple, tant pour le choix des informations qui seront affichées que pour le contenu actuel des lignes. Ce tableau utilise le plugin DataTables pour jQuery et offre des fonctionnalités prêtes à l'usage comme le tri par colonne, la recherche ou encore la sélection de ligne. A ce propose, pour le moment quand des lignes sont sélectionnées ou désélectionnées, un message s'affiche dans la console avec le contenu de la ligne, montrant ainsi qu'il est possible de les recueillir.
La seconde partie de cette page concerne l'upload d'un fichier. Il sera possible prochainement de déposer un fichier dans la zone ou de cliquer dessus pour choisir un fichier dans l'explorateur. La barre de progression montrera après l'appui sur un bouton le pourcentage déjà transféré. Ce bouton n'est pas encore présent mais sera très probablement situé au dessous de la zone d'upload.
L'objectif sera de communiquer le fichier au serveur non pas seul mais avec des métadonnées (liste des nœuds concernés), ce qui fait une potentielle difficulté pour cette étape.
Commit 5
Intitulé : "Spring Security Opérationnel"
Dans l'état actuel du projet, tout le monde peut se créer un compte et se connecter au site avec et la page d'accueil affiche le pseudo de l'utilisateur. Lorsque l'utilisateur n'est pas connecté, toutes les requêtes le renvoient vers la page de login. D'un point de vu quantité de lignes, peu de changements majeurs ont été apportés par rapport au commit 3. En effet, les dysfonctionnements étaient plutôt causés par des éléments de configuration et plus précisément ces 2 points :
- La classe Customer doit pour être reconnu comme un utilisateur par Spring Security posséder un attribut "active" de type entier valant 0 ou 1.
- Ensuite, un changement a eu lieu dans la dernière version de Spring Security. Le mot de passe d'un utilisateur doit être par défaut haché avec Bcrypt dans la base de données. Apporter une telle sécurité nous paraissait futile durant cette phase d'apprentissage du framework mais finalement, il s'est avéré que de laisser des mots de passe en clair demande plus de configuration. Nous avons donc utilisé Bcrypt.
Pour terminer cette partie consacrée à la gestion des utilisateurs il va falloir travailler sur les points suivants :
- Fixer un utilisateur admin en BDD
- Autoriser la création de comptes seulement aux admins
- Créer un rôle utilisateur avec moins de privilèges (création de comptes)
Commit 6 et 7
Intitulé : "Upload d'un fichier"
On continue toujours parallèlement le développement de la partie front. Ce commit intègre la possibilité d'envoyer un fichier unique associé à une liste de nœuds via une requête POST. Après avoir pris connaissance des événements écoutables au niveau de l'action de drag & drop, nous avons fait en sorte d'afficher le nom du fichier dans le cadre une fois celui-ci déposé. Dans une optique d'interactivité, nous avons fait en sorte que la bordure de la zone s'épaississe quand un fichier survole la zone. Pour stocker les données qui seront envoyées, nous avons utilisé l'objet FormData qui permet de construire un ensemble de paires clé / valeur qui représenteront les données que nous enverrons. L'avantage étant que cet objet peut être envoyé via la méthode send() de l'objet XMLHttpRequest. Ainsi au moment de l’événement "drop", nous stockons le nom du fichier et l'objet "File" qui sera converti en binaire à l'envoi. Lorsque l'utilisateur déposent plus d'un fichier dans l'espace prévu, un pop-up d'avertissement apparaît pour indiquer qu'un seul fichier ne peut être transféré.
Nous avons ensuite ajouté la possibilité de cliquer sur cette zone pour choisir le fichier dans l'explorateur. Pour ce faire, nous avons rendu invisible via le CSS un input de type file. En JS, nous observons l’événement "click" sur la zone de dépôt puis nous simulons un clic sur le input invisible faisait apparaître la fenêtre de l'explorateur. Un autre événement "change" sur l'élément input permet de recueillir le fichier et ses infos.
Il a fallu également s'attaquer aux quelques cas d'usage particuliers comme lorsque que l'utilisateur dépose ou choisi un nouveau fichier. Pour ce cas, nous avons fait le choix de remplacer le fichier existant par le nouveau.
Avant de procéder à l'envoi, il faut récupérer la liste des nœuds sélectionnés et pour ce faire, nous avons créé un "Set" qui sera passé intégré à notre instance de FormData grâce la méthode append() de cet objet.
Enfin, pour procéder à l'envoi, il suffit de cliquer sur le bouton en bas de page. Si aucun nœud n'a été sélectionné ou si aucun fichier n'a été fourni, un pop-up apparaîtra pour stipuler l'erreur. En revanche si tout se passe bien, la requête POST peut être envoyée. Dernière petite fonctionnalité, XMLHttpRequest nous permet de récupérer le nombre d'octets total à transmettre ainsi que le nombre déjà transmis ce qui est parfait pour intégrer une barre de progression. Une fois le transfert opéré, un message apparaît et la page est rechargée.

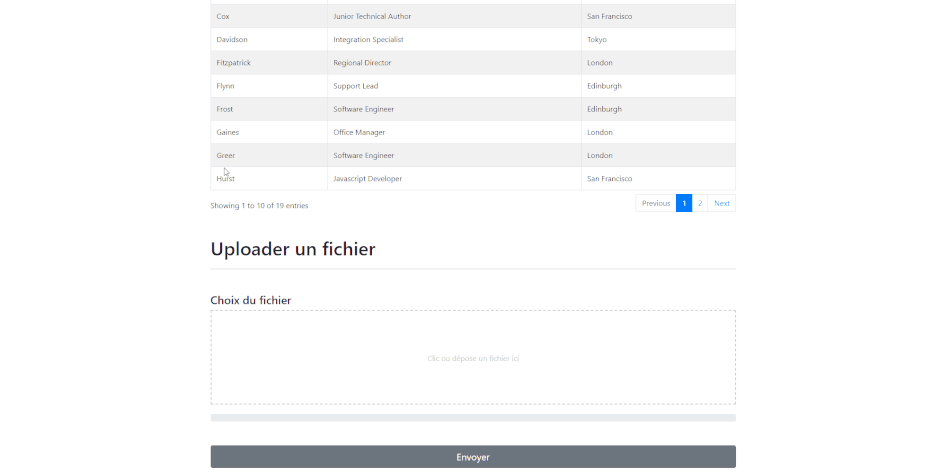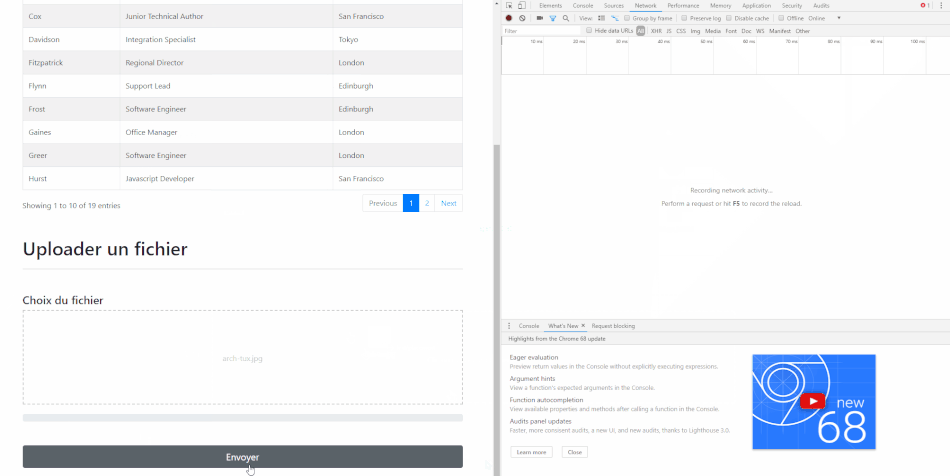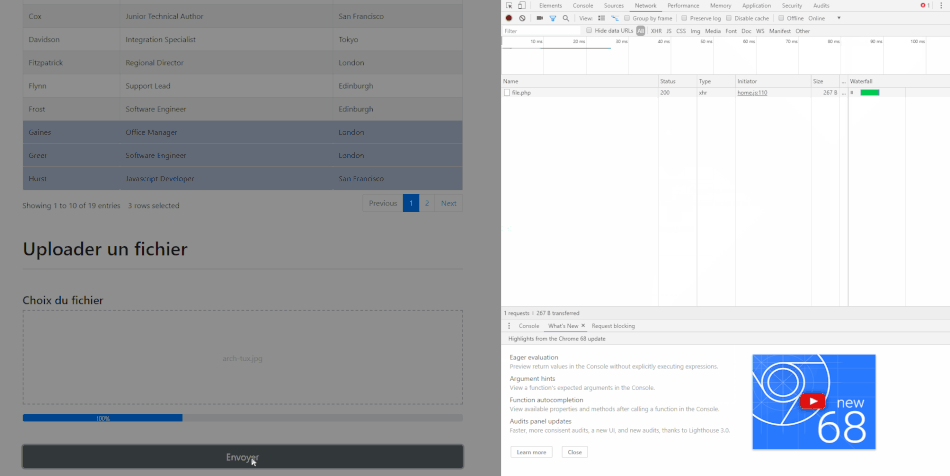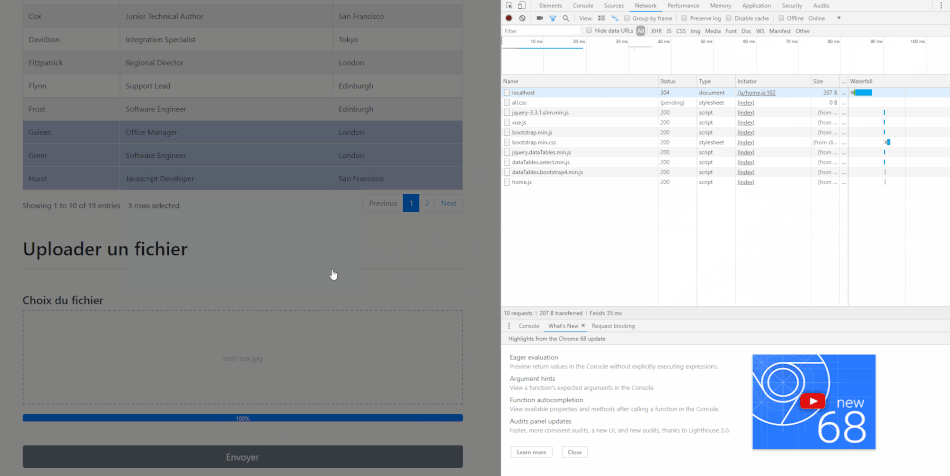{kind=link}
Commit 8
Intitulé : "Optimisation de la communication avec la BDD"
Pour ce commit, nous nous sommes concentré uniquement sur la base de données et ses interactions avec Spring. Premièrement, grâce au fichier data.sql il est possible d'ajouter des entrées au lancement du serveur. Le problème étant qu'ensuite, lorsqu'on ajoute un utilisateur depuis le site internet, Spring commence par l'id '1' pour l'utilisateur alors qu'il est déjà utilisé vu que des utilisateurs ont été entrés dans la base de données au lancement. Pour corriger ce problème, il est nécessaire de modifier la manière dont Hibernate va générer les id. En fait, on précise dans notre classe "Customer" que la génération est en mode automatique alors qu'il faut en fait la paramétrer.
Malgré toutes les tentatives sur les différents type de génération, nous ne sommes pas parvenu à changer dynamiquement la valeur initial de l'id. Nous avons donc choisi d'utiliser une méthode setId() qui va être appelée en même temps que setPassword() et setPseudo(). Nous utilisons la méthode count() déjà implémenter dans JpaRepository (et donc CrudRepository). Celle-ci permet de connaître le nombre d'entrées dans la base de données à chaque fois que la requête "registration" est émise. L'assignation de l'id est donc dynamique.
L'erreur qui dupliquait le champ "ADMIN" a également été corrigée. Plutôt que de créer un nouvel utilisateur à chaque requête vers "registration", on recherche le rôle "ADMIN" dans la table rôle et assigne la ligne trouvé à l'utilisateur.
Enfin, nous avons ajouté un utilisateur par défaut : pseudo : user / password : user, et un administrateur par défaut : pseudo : admin / password : admin.
Remarque : il est obligatoire de stocker le password haché dans le fichier data.sql pour que Spring puisse l'utiliser (en effet, depuis Spring Boot 5.0, il est obligatoire d'encoder le mot de passe).
Commit 9
Intitulé : "Routage du site"
Nous avons implémenté la distinction entre un utilisateur classique et un administrateur. Les pages auxquelles peut accéder chaque rôle sont donc différentes : seul l'administrateur peut accéder à la page "registration"; les deux utilisateurs doivent se connecter pour accéder aux différentes pages du site. L'administrateur peut désormais préciser quel rôle aura l'utilisateur ajouté
Les templates sont également codés pour n'afficher que les informations dédiées au rôle qui est connecté au site internet.
Commit 10
Intitulé : "Intégration du front au projet"
Ce commit consiste en l'intégration de la partie front au projet. Pour que les templates puissent utiliser les ressources dont elles ont besoin (CSS et JS), nous avons créé un dossier static contenant deux autres dossiers JS et CSS pour lesquels nous avons autorisé l'accès à tout le monde dans la configuration de Spring Security. Pour la page de login, aucun changement majeur si ce n'est la présence d'un message d'erreur qui s'affiche lorsque que le compte n'existe pas. Son apparition ou non est gérée dans la template Thymeleaf grâce à une condition sur le paramètre "erreur" de l'URL.
La page d'accueil a elle aussi été mise à jour. Seul les liens "déconnexion" et "paramètres" de la barre de navigation ont été changés. Des tests sur mobile, nous ont révélé quelques soucis d'adaptation du contenu, il faudra veiller à régler ces petits défauts d'affichage. Il serait intéressant également de travailler sur la template "registration" consacrée à l'ajout d'utilisateurs. Enfin, il faudra être capable au niveau du controller Spring de récupérer le fichier envoyé depuis l'interface via la requête POST.
Commit 11
Intitulé : "Sauvegarde des fichiers envoyés"
Ce commit ajoute l'enregistrement du fichier uploadé depuis l'interface web. Ce fichier se retrouve stocker dans un répertoire nommé <pseudo>_<timestamp> qui lui même est dans le dossier files. Ceci permet d'avoir un dossier unique pour chaque envoi de fichier par l'utilisateur tout en gardant une trace de son nom pour d'éventuels futurs besoin. Techniquement, la sauvegarde du fichier s'effectue en copiant par bloc de 1024 octets le binaire contenu dans la requête vers sa destination au moyen des flux Java. Pour la suite nous avons envisagé la création d'un programme annexe daemon dont le but serait de scruter la présence de nouveaux fichiers et de les transférer sur les nœuds concernés. Cette liste de nœuds sera dès le prochain commit incluse dans le dossier du fichier. On peut ensuite imaginer l'utilisation d'Ansible pour faciliter le déploiement du binaire sur les nœuds.
Commit 12
Intitulé : "Amélioration du front-end"
Nous avons ajouté une page permettant de visualiser tous les utilisateurs enregistrés sous la forme d'un tableau avec leur ID, leur pseudo et leur rôle. Cette liste n'est accessible qu'aux administrateurs.
Ajouter images
Commit 13 et 14
Intitulé : "UI : modifications mineures"
- Changement de quelques textes
- Mieux adapté aux mobiles : quelques ajustements sur le CSS ont été faits pour améliorer l'expérience sur les appareils mobiles.
- Ajout des alertes pour la page d'ajout des utilisateurs : une alerte s'affiche si le pseudo est déjà utilisé.
- Corrections orthographiques
Commit 15
Intitulé : "Passage de pseudo à email pour les utilisateurs"
Les utilisateurs sont maintenant caractérisés par leur email et non plus par leur pseudo suite à la demande de nos encadrants. Quelques ajustement au niveau des formulaires ont du être faits.
Commit 16
Intitulé : "Ajout d'une classe qui contiendra les paramètres d'une mise à jour si l'utilisateur souhaite la stocker"
Il nous a également été demandé de revoir le système permettant d'uploader des fichier depuis l'interface. L'idée est de séparer l'upload du déploiement et ainsi de pouvoir garder un historique des mises à jour qui ont été faites par chaque utilisateur afin qu'il puisse facilement réitérer ces précédentes actions.
Commit 17
Intitulé : "Implémentation de l'ajout de maj"

Nous avons désiré ajouter la possibilité d'enregistrer les paramètre d'une mise à jour; c'est à dire les noeuds connectés, le nom de la mise à jour, sa date d'exécution et le fichier binaire à téléverser. Nous avons donc implémenter une nouvelle classe Maj.java ainsi que son dépôt MajRepository.java qui va permettre de créer une nouvelle table maj. La table maj a en fait le même comportement que la table de rôle : elles possèdent toutes les deux une jointure multiples associé à la table customer.
Ensuite, nous avons écrit une page HTML basique permettant de tester cette classe maj et son bon fonctionnement en ce qui concerne les ajouts en BDD et la liaison à l'utilisateur qui l'a créé. Par la suite, nous avons pour objectif de faire évoluer la gestion des utilisateurs par une gestion par groupes. En effet, il y a plusieurs groupes de recherche dans un laboratoire mais chaque individu d'un même groupe doit avoir accès aux mises à jour du groupe. Il faudra donc créer une classe Group.java qui sera en jointure avec la table customer et la classe maj. Ainsi les mises à jour seront visibles par tous les utilisateurs d'un même groupe de recherche.
Commit 18
Intitulé : "Page home restructurée et fonctionnelle"
Nous avons enlevé le tableau des noeuds sur la page d'accueil. Elle ne comprend maintenant plus que l'espace permettant d'uploader des fichiers sur le serveur.
Commit 19 et 20
Intitulé : "Mise à jour front et sauvegarde d'une configuration"
Intitulé : "Choix du fichier pour la sauvegarde d'une configuration"
Nous avons créé une nouvelle page "Paramétrer une mise à jour" découpée en deux sections. La première est un historique des mises à jour que l'utilisateur a décidé de sauvegarder. Il aura la possibilité de sélectionner l'une d'entre-elle et de relancer son déploiement. La seconde partie concerne justement la création d'une mise à jour. L'utilisateur sélectionne les noeuds concernés, entre un nom pour cette configuration, sélectionne le fichier dans la liste, entre la date (éventuellement l'heure ?) à laquelle il veut que la mise à jour soit effectuée et enfin il choisit via les deux boutons s'il veut sauvegarder cette configuration ou seulement l'appliquer sans la sauvegarder.
Ajouter images
Le bouton "Lancer la mise à jour" n'a pour l'instant aucun impact mais nous avons réfléchi au fonctionnement de la partie back-end pour mettre en place cette action. Lors de l'appuie, nous allons créer un fichier dans un dossier prévu pour les mises à jour, supposons un qu'il s'appellera "todo". Ce fichier contiendra l'ensemble des métadonnées qui ont été entrées par l'utilisateur et pour limiter l'espace disque le chemin vers le fichier à déployer. Ce fichier pourra être dans un format de représentation des données tels que JSON ou YAML bien que cela ne soit pas forcément nécessaire. Un autre programme (en Java par exemple) se chargera de scruter ce dossier pour voir si des mises à jour sont dans l'attente d'être faites.
Commit 21
Intitulé : " Ergonomie du site"
Suite aux différentes remarques d'un de nos encadrants, nous avons revu quelques éléments de la partie front-end. Il s'agit principalement d'un changement au niveau du header où le bouton pour se déconnecter est maintenant plus visible sur la droite. Nous avons également profité pour faire un peu de nettoyage et d'organisation dans les fichiers.
Commit 25
Intitulé : "Fichier de configuration YAML"
Dans le but de ne jamais devoir modifier le code source ou encore de devoir modifier la base de données, nous avons mis en place un fichier de configuration au format YAML qui permet dans l'état actuel des choses de créer le premier utilisateur ADMIN de l'application en renseignant son email et son mot de passe. Les lignes qui suivent sont consacrées à l'établissement de la liste des nœuds qui seront visibles depuis l'interface.
adminEmail: pfe@pfe.fr
adminPassword: pfepfe
nodes:
- name: AT-001
ip: '85.10.201.246'
arch: ARM
- name: AT-002
ip: '85.10.201.247'
arch: ARM
- name: AT-003
ip: '85.10.201.248'
arch: ARM
- name: ATTTT-004
ip: '85.10.201.249'
arch: ARM
On constate ici un objet nodes comprenant lui même une liste d'autres objets décrivant les informations relatives aux noeuds (nom, ip, architecture). La présence de ce fichier YAML est obligatoire pour garantir le fonctionnement de l'application. Sa lecture s'effectue au sein d'une classe possédant une méthode init() avec une annotation @PostConstruct qui lui permet de s’exécuter au démarrage du programme après toutes les inutilisations opérées en interne et qui sont nécessaires. Afin de parser ce fichier, nous avons utilisé la bibliothèque SnakeYAML qui possède la particularité intéressante (sûrement comme d'autres) de faire correspondre une classe avec un YAML. On aurait ici pour illustrer, une classe YAMLConf par exemple avec comme attributs String adminEmail, String adminPassword et List<NodeYAML> nodes. Il faudrait ensuite créer la classe NodeYAML de la même façon. Avec les getters/setters qui vont avec, on dispose donc d'un objet Java représentant notre fichier YAML.
Commit 26
Intitulé : "Modifications front-end"
A nouveau, nous avons effectué quelques changement en terme d'apparence. Le header se retrouve un peu plus resserré vers le centre et est maintenant pourvu d'un logo permettant de revenir à la page d'accueil. A ce propos, une vraie page d'accueil a fait son apparition car jusqu'à présent il s'agissait de la page d'upload. Cette nouvelle vue accueille selon le rang de l'utilisateur les fonctionnalités auxquelles il a accès avec une courte description.
Ajouter images
Commit 27
Intitulé : "Changement pour la configuration du réseau"
Comme nous l'avions vu dans le commit 25, la configuration du réseau se faisait au moyen d'un fichier YAML à venir déposer à la racine de l'application. Seulement, après discussion, nous avons trouvé plus judicieux de proposer cette fonctionnalité depuis l'interface web pour limiter le plus possible les interactions directes avec le serveur. De plus, cela permet à tous les administrateurs de changer cette description des noeuds (il conviendra de rediscuter avec nos encadrants d'un rang spécial éventuellement). L'upload de ce fichier s'effectue sur la page "Paramétrer une mise à jour" où un champs permet de sélectionner le fichier voulu. Un exemple est également présent juste en dessous pour montrer la syntaxe qu'il faut adopter.
nodes:
- name: AT-001
ip: '85.10.201.246'
arch: ARM
- name: AT-002
ip: '85.10.201.247'
arch: ARM
- name: AT-003
ip: '85.10.201.248'
arch: ARM
- name: ATTTT-004
ip: '85.10.201.249'
arch: ARM
Une fois le bouton "Envoyer" pressé, la modification du réseau est visible directement dans le tableau des noeuds situé plus bas.
Ajouter images
Commit 28
Intitulé : "Bouton "Lancer la mise à jour" fonctionnel"
La page "Paramétrer une mise à jour" est maintenant fonctionnelle dans son intégralité. En effet, le bouton "Lancer la mise à jour" envoie maintenant une requête POST au serveur. Dans le cas d'une mise à jour anonyme (sans sauvegarde en BDD), toutes les informations relatives à la mise à jour sont envoyées. Dans le cas d'une mise à jour sauvegardée, seul le nom est envoyé via la requête. Coté back-end, deux nouvelles routes sont donc apparues permettant de gérer justement ces deux cas de figure. Pour le moment, les deux méthodes de ces routes se contentent de créer un fichier YAML dans le dossier toflash avec les paramètres de la mise à jour. Comme nous l'avions évoqué plus tôt, un second programme se chargera par la suite de scruter ce dossier afin de vérifier si des mises à jour doivent être effectuées.
Second semestre
Commit 29, 30 & 31
Intitulé : "Ajout des groupes de travail"
Intitulé : "Modifications mineures de méthodes"
Intitulé : "Modifications mineures"
Il existe désormais une gestion des utilisateurs et des mises à jours par groupes de travail. En effet, notre idée est que dans un laboratoire, il existe plusieurs groupes de recherche. Ainsi, il est nécessaire que un utilisateur d'un groupe de travail puisse avoir accès aux mises à jours des autres utilisateurs du même groupe. Pour cela nous avons donc créé une classe et une table "Team" (le mot-clef "group" est réservé en PostgreSQL). Celle-ci possède deux jointures multiples : une avec "Customer" pour lister les utilisateurs présents dans le groupe. La deuxième jointure est avec "Update" et remplace la jointure multiple dans "Customer" : en effet désormais les mises à jours sont par groupe et non plus par utilisateur. Dorénavant lorsqu'on accède à une "Team" on peut connaitre les utilisateurs de ce groupe et savoir les mises à jours réalisés (i.e. sauvegardé) par les utilisateurs.
A faire : il reste à ajouter un groupe par défaut pour le premier utilisateur. Nous ajouterons également la possibilité de créé de nouveaux groupes et de spécifier lors de la création d'un utilisateur, le groupe auquel il appartient.
Commit 32
Intitulé : "Nouvelle manière de paramétrer le réseau"
Jusqu'à présent, la configuration de réseau s'effectuée sur la page consacrée aux mises à jours et l'utilisateur devait uploader un fichier YAML représentant le réseau. Mais suite à notre soutenance intermédiaire, nous avons opté pour une configuration plus didactique directement depuis l'interface. L'utilisateur peut créer autant de noeuds qu'il le souhaite et y ajouter un ou plusieurs capteurs. L'interface lui permet également de revenir sur un noeud créé en le modifiant ou en le supprimant. Lors de l'appuie sur le bouton du dessous, une requête POST sera envoyée avec comme corps un objet JSON regroupant toutes les données. De cette façon, quiconque peut modifier le réseau sans avoir à connaitre les spécificités d'un langage de sérialisation comme le JSON ou le YAML.
A faire : il faudra s'occuper de la partie back-end pour traiter le JSON et modifier la base de données en conséquence. De plus, avec l'apparition des capteurs, il faudra modifier le contenu du tableau qui permet la sélection des noeuds lors de la création d'une mise à jour.
Commit 33
Intitulé : ajout de l'interface pour ajouter des groupes
Pour compléter le travail réalisé lors du commit 29, 30 et 31, nous avons ajouté modifiant l'interface utilisateur pour prendre en compte les groupes de travail. Sur la page registration.html, qui permet d'ajouter de nouveaux utilisateurs, quelques modifications ont été faite pour entrer en cohérence avec l'ajout des groupes de travail. En effet, lors de la création d'un utilisateur, il est désormais nécessaire de lui fournir un groupe de travail pour pouvoir l'ajouter. Pour pouvoir créer ce groupe, un formulaire est présent plus bas sur la même page.
Commit 34
Intitulé : Possibilité de voir les groupes et leurs mises à jours
Ce commit corresponds également à la mise en oeuvre des groupes de travail puisque sur la page all.html qui permettait d'afficher les utilisateurs ainsi que leur rôle, il est désormais possible de visualiser les groupes de travail avec les mises à jours qui y sont faites ainsi que les identifiants des utilisateurs appartenant au groupe de travail.
Commit 35
Intitulé : "Backend : configuration du réseau"
La page /registration commençait à ne plus être cohérente avec le reste du site, c'est pourquoi nous avons effectué quelques changements sur la partie front-end de manière à mieux structurer et mettre en valeur les deux sections : ajout d'un utilisateur et ajout d'un groupe.
Lors du commit 32, nous avions imaginé une nouvelle manière de paramétrer le réseau. Cette fonctionnalité est maintenant intégrée dans le haut de la page /update. Lorsque le bouton "Terminer" est pressé, si des nœuds ont été renseignés, la page envoie une requête POST au serveur avec comme corps du JSON. Du coté du controller, l'ensemble du corps est parsé grâce à l'objet ObjectMapper de la bibliothèque Jackson. Il permet de faire correspondre un fichier JSON avec un ou plusieurs objets Java. Dans notre cas, ObjectMapper s'attend à trouver une liste de NodeJSON composé des attributs name, ip, arch et d'une liste de SensorJSON avec comme seul attribut pour le moment, name. On peut ensuite parcourir cette liste de noeuds créée et enregistrer les entrées dans la base de données.
Comme nous venons de le voir, nous faisons maintenant la distinction entre les noeuds et les capteurs. Il faut donc modifier la page de création des mises à jours pour les faire apparaître. Un double foreach dans la template Thymeleaf associé a suffit pour multiplier les lignes des noeuds possédant plusieurs capteurs.
Commit 36
Intitulé : Ajout du fichier qui tournera sur la Raspberry
Les Raspberry représentent les noeuds du réseaux de capteurs dans notre projet. Ce sont elles qui font faire l’interface entre les capteurs d’une part, et le serveur d’autre part. La manière dont nous avons conçu notre système est que serveur va lancer un programme sur la Raspberry qui va se charger de récupérer les valeurs des capteurs et ses valeurs seront ensuite transféré jusqu’au serveur sous la forme de fichiers.
Nous avons choisi de réaliser ce programme en C. Premièrement, c’est un langage que nous maîtrisons bien, ensuite, il nous permet de rester bas niveau ce qui correspond bien pour la communication série avec les capteurs.
Le programme utilise deux fichiers différents en entrée. Le premier “config_raspberry.txt” contient la correspondance entre chaque port série et le nom du capteur qui lui est associé. Par exemple “temperature_1=/dev/ttyACM0” signifie que le capteur de temperature numéro 1 est sur le port série linux /dev/ttyACM0. Cela va permettre de créer un fichier de sortie par nom de capteur ce qui sera plus facile à utiliser par le serveur pour afficher les valeurs à l’utilisateur. Le deuxième fichier est “config_experimentation.txt” qui est simplement un fichier qui liste les capteurs pour lesquels les données doivent être récupérés. Ce fichier est généré par Ansible est ajouter dans le dossier avant que le serveur lance l’exécution du programme.
En sortie du programme, un fichier différent est créé pour chaque capteurs dans le dossier res. Les fichiers sont sous la forme “result_exp_mouvement_capteur.txt”. Ces fichiers sont écrits en temps réel par le programme dans chaque thread et ne sont pas modifiés par rapport aux caractères récupérés sur la liaison série. En effet, lors de la réceptions des octets provenant du capteurs aucun traitement n’est fait (retour à la ligne, virgule, espace, etc.). Le choix a été fait de laisser les codeurs du programme sur le microprocesseur de faire le code en conséquence et d’ainsi pouvoir y ajouter leur propre délimiteurs.
Pour ce programme nous utilisons différents outils :
- la bibliothèque termios.h qui permet de modifier les caractéristiques des ports séries comme la gestion des caractères spéciaux, le baudrate, le blocage ou non de la fonction read, etc.
- la bibliothèque pthread.h que nous utiliserons pour créer un thread par communication série.
- deux fichiers de configuration : config_raspberry.txt et config_experimentation.txt qui permettent de mettre en lien de les ports séries et les capteurs à utiliser dans l'expérimentation.
Afin de mener à bien une communication avec plusieurs capteurs, ce programme est multithread : il y a un processus par communication avec une liaison série. Dans notre système on suppose que un capteur correspond à un microprocesseur et donc à une liaison série. Pour ce faire, nous utilisons la bibliothèque pthread.h qui nous permet de créer un processus à partir d’une fonction.
Ensuite, le programme est dans une boucle de lecture infinie et ne s'arrête donc jamais par lui-même. C’est le serveur qui se charge de lui indiquer quand s'arrêter en lui envoyant un signal SIGKILL. Ce signal est pris en charge par le programme et il se charge de fermer correctement les liaisons séries, les fichiers ainsi que d’arrêter les threads proprement avant de finir complètement.
Enfin, la bibliothèque termios.h est la plus utilisé puisque c’est elle qui nous permet de nous interfacer avec les liaisons série. Cette bibliothèque est relativement bas niveau puisqu’elle nécessite plusieurs opérations binaires pour modifier le comportement des liaisons séries. En effet, grâce à cette bibliothèques on peut avoir accès à toutes les caractéristiques de la liaison ciblé mais aussi en modifier le comportement.
Pour notre projet, nous avons besoin d’avoir une liaison série sur laquelle on récupère les valeurs tel qu'elles arrivent ce qui n’est pas le cas par défaut sous linux. De nombreuses fioritures sont en effet ajoutés pour le confort des utilisateurs comme l’affichage des lettres tapés par l’utilisateur dans le terminal par exemple. Pour se défaire de ce problème on utilise la fonction cfmakeraw() qui va fixer la valeurs de plusieurs “flags” (bits avec une signification précise) dans la structure termios. Ensuite la fonction setispeed() et setospeed() nous permettent de fixer le baudrate à 9600 pour les liaisons série. Cette bibliothèque nous permet finalement de changer le fonction de la fonction read(). Il existe en effet deux modes différents : canonique et non-canonique. Par défaut, la lecture est canonique, c’est à dire que la lecture est faite par ligne, celles-ci séparés par des retours chariot “\n”. Cela signifie que lors d’un read() on ne peut pas lire plus loin qu’un retour chariot. Nous changeons donc ce mode (toujours grâce à cfmakeraw()) en non-canonique ce qui nous permet d’avoir une vraie lecture octet par octet et d'accéder à deux variables : VMIN et VTIME. La variable VMIN indique combien d’octets doivent avoir été reçu depuis le dernier read (octets dan le buffer) avant que celui-ci ne puisse retourner le résultat. La variable VTIME quand à elle est un time-out, c’est à dire que c’est compte à rebour qui décompte à chaque fois que la fonction read() est lancé. Lorsqu’il arrive à 0, la fonction read() retourne quoiqu’il arrive. Ainsi on a toujours une lecture bloquante (on attendant un seul octet dans notre programme) mais avec un compte à rebour, ainsi chaque thread peut regarder si un signal d’arrêt de programme a été envoyé par le serveur.
Lors de l’implémentation de notre programme nous avons rencontré beaucoup de problème avec ces variables et la lecture bloquante de manière générale. Pour faire les tests nous avons travaillé sous linux et les variables ne semblent pas être prises en compte quoiqu’il arrive : la lecture n’attends pas d’avoir reçu au moins 1 octet et le compte à rebour n’est pas utilisé du tout. Cela n’est pas le cas lorsque le programme est implémenté sur la Raspberry ou le fonctionnement décrit dans le manuel de termios est bien respecté.
Commit 37
Intitulé : "Modifications mineures"
Sur la page des expérimentations (/update), nous avons supprimé, car peu utile, le bouton permettant de lancer une expérimentation de manière anonyme sans enregistrement en BDD. Sur cette même page, nous avons ajouté dans le formulaire de création de la mise à jour un champ permettant de renseigner la durée de l'expérimentation et nous avons modifié celui pour la date en y ajoutant l'heure.
Lorsque une mise à jour est lancée ou relancée depuis la page, le serveur va vérifier la cohérence de la date et la modifier dans le cas ou celle-ci se trouve dans le passé en y mettant la date actuelle du serveur.
Docker
Les débuts
Lorsqu'une expérimentation est lancée, un fichier qui lui est propre est créé dans le dossier "toflash". Un programme annexe en cours d'écriture se charge d'exploiter ce fichier pour compiler les sources puis flasher les différents appareils. Mais selon l'architecture des dispositifs, il faut choisir la toolchain de compilation adaptée. Nous avons commencé par écrire un Dockerfile permettant la compilation d'un programme pour ARM. L'idée à terme serait d'avoir une image pour chaque architecture ce qui permet une maintenance plus facile en évitant d'avoir plusieurs versions de GCC.
Un Dockerfile se trouve dans le répertoire /home/pifou/compiler/arm_compiler et l'image se crée avec la commande :
docker build -t arm_compiler .
Pour pouvoir compiler notre porgramme, il faut créer un conteneur avec cette image de cette façon :
docker run --rm -v /home/pifou/exp:/exp -e SRC_NAME="main.c" -e SRC_DIR="exp1" arm_compiler
L'option --rm permet de supprimer le conteneur une fois la compilation terminée, le volume (-v) spécifie le dossier où se trouve les sources sur la machine hôte ainsi que le dossier de réception du binaire. On affecte ensuite deux valeurs pour les variables d'environnements SRC_NAME et SRC_DIR avec l'option -e pour respectivement donner le nom du fichier à compiler et dans quelle dossier de /exp il se situe. Pour le moment, le cas des projets avec Makefile n'est pas géré. Nous avons l'idée pour généraliser le fonctionnement mais nous ne savons pas comment détecter le fichier de sortie produit.
Le Dockerfile se présente comme ceci :
FROM debian:latest RUN apt-get update RUN apt-get install -y python2.7 python-pip gcc-arm-none-eabi && pip install mbed-cli WORKDIR /arm COPY ./start.sh /arm RUN chmod +x ./start.sh ENTRYPOINT ./start.sh
Ce Dockerfile était au départ prévu pour gérer les projets Mbed d'où la présence de paquets supplémentaires. Concrètement, à la création le conteneur possédera un dossier /arm dans lequel un fichier bash sera copié depuis la machine hôte pour ensuite être exécuté grâce à la directive ENTRYPOINT. Ce fichier start.sh contient les commandes nécessaires pour compiler le fichier. Par la suite, c'est lui qui fera la différence entre un projet à fichier unique, un zip avec Makefile ou même une adresse de dépôt git.
Suite
Finalement, nous avons décidé que cette image soit celle qui compile des projets Mbed. Pour ce faire, nous avons dans l'image importé un projet exemple qui servira de base pour construire le binaire. Le fichier à compiler vient donc remplacer le main.cpp d'exemple et on peut ensuite compiler le projet. Pour accélérer le processus, nous procédons à la compilation des sources Mbed à la création du conteneur donc une fois, au build de l'image.
Le Dockerfile change légèrement pour devenir :
FROM debian:latest RUN apt-get update RUN apt-get install -y python2.7 python-pip gcc-arm-none-eabi && pip install mbed-cli WORKDIR /arm RUN mbed import https://github.com/ARMmbed/mbed-os-example-blinky && \ cd mbed-os-example-blinky && \ mbed compile -t GCC_ARM -m NUCLEO_F401RE && \ rm main.cpp && \ cd .. COPY ./start.sh /arm RUN chmod +x ./start.sh ENTRYPOINT ./start.sh
Au niveau du script Bash, quelques lignes sont nécessaires pour produire le binaire :
#!/bin/bash echo "Compilation de : " $SRC_NAME cp /exp/$SRC_DIR/$SRC_NAME /arm/mbed-os-example-blinky/main.cpp cd ./mbed-os-example-blinky mbed compile -t GCC_ARM -m NUCLEO_F401RE cd ./BUILD/NUCLEO_F401RE/GCC_ARM mv mbed-os-example-blinky.bin out.bin cp out.bin /exp/$SRC_DIR/
Script Ansible
Les débuts
Ansible est un utilitaire écrit en Python permettant via le protocole SSH de gérer et configurer des ensembles d'ordinateurs qui seront dans notre cas les noeuds du réseaux, des Raspberry Pi. Le script Ansible que nous avons écrit sera lancé et paramétré par le programme C. Dans le code ci-dessous, le programme de lecture série est pour le moment remplacé par un programme (while) qui tourne en boucle et ne fait rien.
Le lancement du script s'effectue grâce à la commande suivante qui n'est qu'un exemple de ce que le programme C pourrait exécuter.
ansible-playbook /etc/ansible/roles/test.yml -i /etc/ansible/exp_42.hosts -e "servernames=exp_42 exp_duration=3600 binary_dir=admin_1550420007"
Cette commande prend en argument un script YAML (comme celui dessous) et accepte plusieurs options comme -i pour donner le fichier d'inventaire contenant les IPs des nœuds ou -e pour créer des variables qui seront accessibles dans le playbook.
---
- hosts: "{{ servernames }}"
tasks:
- name: "Création du dossier de résultats"
file:
path: /home/pi/{{ servernames }}/res
state: directory
recurse: yes
On commence par indiquer le fichier hosts sur lequel appliquer ce script. On crée ensuite la première tâche qui aura pour effet de créer un dossier exp_42 avec dedans un autre dossier res si l'on garde l'exemple vu plus haut.
- name: "Copie du fichier de lecture série"
copy:
src: ~/pfe/while
dest: /home/pi/{{ servernames }}/while
On copie l’exécutable qui viendra produire les résultats par lecture série.
- name: "Copie du binaire pour le(s) capteur(s)"
copy:
src: ~/pfe/files/{{ binary_dir }}/out.bin
dest: /home/pi/{{ servernames }}/out.bin
On copie le binaire produit par le conteneur Docker sur le nœud.
- name: "Lancement du programme de lecture série"
command: /home/pi/{{ servernames }}/while
async: 3000000
poll: 0
Il manque ici, avant de lancer le programme de lecture série, toute la partie qui concerne le flashage des capteurs mais celle-ci arrivera un peu plus tard. Cette tâche ci lance donc le programme de manière asynchrone pendant une durée arbitraire suffisamment longue. Nous aurions pu mettre directement la durée souhaitée de l'expérience mais dans ce cas, nous n'aurions pas été certain après la pause (tâche ci-dessous) que le programme ce soit réellement terminé. Une autre solution aurait été d'ajouter quelques secondes à la pause.
- name: "Exp en cours ..."
pause:
seconds: "{{ exp_duration }}"
L’exécution du script se met en pause pendant la durée de l'expérience.
- name: "Kill de l'application"
shell: pkill while
Le programme de lecture série est stoppé.
- name: "Récupération des noms des résultats"
shell: (cd /home/pi/{{ servernames }}/res; find . -maxdepth 1 -type f) | cut -d'/' -f2
register: files_to_copy
- name: "Copie des résultats sur le serveur"
fetch:
src: /home/pi/{{ servernames }}/res/{{ item }}
dest: /home/antoine/pfe_results/{{ servernames }}/{{ ansible_host }}/
flat: yes
with_items: "{{ files_to_copy.stdout_lines }}"
On va venir ici rapatrier les résultats sur le serveur. Comme la commande fetch ne peut copier qu'un seul fichier et non tous les fichiers d'un dossier, il faut commencer par récupérer la liste des fichiers que l'on vient stocker dans une variable (files_to_copy) accessible dans tout le script. La tâche qui suit se charge d'effectuer le fetch dans une boucle qui parcourt l'ensemble des fichiers de résultats.
- name: "Suppression du dossier sur le noeud"
shell: rm -rf /home/pi/{{ servernames }}
Finalement, nous pouvons supprimer le dossier concernant l'expérimentation.
Programme C : lecture, compilation et flashage
Pour ce que nous avions à faire, un langage de haut niveau n'était pas une nécessité, nous avons donc opté pour le C. Nous l'avons déjà évoqué mais pour rappel ce programme agira comme un démon et viendra scruter régulièrement (tous les 10s pour le moment) le dossier "toflash" pour savoir si une expérimentation doit se faire ou non. Pour ne pas alourdir cette page de plus de 300 lignes de codes, nous allons plutôt décrire les différentes étapes qu'effectue le programme.
Le main() est une simple boucle while infinie dans la quelle on retrouve une fonction check_files() suivi d'un sleep de 10 secondes.
La fonction check_files() ouvre dans un premier temps le dossier "toflash" puis va parcourir l'ensemble des fichiers qu'il contient. Pour chaque fichier, nous créons une structure regroupant l'ensemble des données du fichier YAML.
typedef struct node {
char *ip;
char *sensors[MAX_SENSORS];
int n_sensors;
} Node;
typedef struct experiment {
int exp_id;
int n_nodes;
char *date;
char *file;
char *duration;
char *name;
char *arch;
char *dir;
Node nodes[MAX_NODES];
} Experiment;
Cette structure est remplie par la fonction read_file() qui elle même va appeler pour chaque ligne du fichier la fonction process_line() qui va se charger réellement de compléter la structure. Ça se complique un peu pour la ligne des nœuds. Pour celle-ci, nous avons choisi de créer une autre structure qui contiendra les informations d'un nœud et le nom de ses capteurs. Il faut donc vérifier à chaque fois s'il faut ajouter un nouveau noeud à la liste ou bien simplement ajouter un capteur à un nœud existant. Cette manière de regrouper sera utile lors du déploiement des binaires.
Lorsque la structure est remplie, on peut maintenant procéder à l'analyse de ses données avec la fonction process_exp(). L'élément déterminant est la date de l'expérimentation. Si le timestamp de celle-ci est inférieur ou égal à la date et heure actuelle, la fonction continue et dans le contraire elle retourne 1 et la structure est libérée en mémoire puis on passe au fichier suivant s'il y en a un.
Dans le cas où le déploiement doit s'effectuer, on commence par regarder l'architecture des capteurs et on lance la compilation via le bon conteneur Docker grâce à la fonction system() qui à l'avantage d'être bloquante. Nous avons conscience que cette fonction n'est pas toujours recommandée mais pour cet usage elle est suffisante. Viens ensuite l'étape où nous allons via SSH créer un dossier avec un fichier sur tous les noeuds en indiquant la liste des capteurs concernés. Cette information sera utile pour le programme de lecture série afin de faire la correspondance entre le nom et lé périphérique dans /dev. Cette opération n'est pas assez générique pour être faite avec Ansible vu que le fichier sera différent. Finalement, process_exp() va lancer le script Ansible mais cette fois de manière asynchrone en utilisant la fonction fork(). En effet, nous ne pouvons pas nous permettre d'attendre la fin de l'expérimentation, celle-ci pouvant être très longue.
Programme C : lecture et enregistrement des données d'un ou plusieurs ports séries
On utilise une fonction générique appelé read_file_by_line() qui va lire le fichier qu’on lui indique et mettre chaque ligne dans une case d’un tableau de caractère indiqué lui aussi. Cette fonction est utilisé pour lire config_raspberry.txt mais aussi pour config_experimentation.txt. Ensuite, il reste à récupérer les ports de chaque capteurs qui doivent être lu. pour cela on utilise la fonction get_ports_to_read() qui utilisent les deux tableaux de lignes créés précédemment et faire la correspondance entre les deux. On prend un capteur à lire puis on regarde dans la liste du fichier des ports séries si ce capteur est présent. Si celui-ci l’est, on l’indique dans un troisième tableau de sortie qui contients les ports à lire lors de cette expérimentation. On fait de même avec tous les capteurs qui sont demandés pour l'expérimentation. Une fois la liste des ports séries connus et donc le nombre à lire, on peut créer autant de threads que nécessaire.
void * start(void * sensorAndPort){
int pt = set_serial((SensorAndPort *) sensorAndPort);
save_data(pt, ((SensorAndPort *)sensorAndPort)->sensor);
reset_serial(pt);
pthread_exit(NULL);
}
Grâce à la bibliothèque pthread.h, on va créer un thread ( ou processus léger) en utilisant la fonction pthread_create(). Celle-ci prend en paramètre la fonction start() ci-dessus qui va se charger de lancer plusieurs fonctions. Premièrement set_serial() qui va se charger de modifier le comportement des liaisons séries :
int set_serial(SensorAndPort* sensorAndPort){
char *device = sensorAndPort->port;
printf("device : %s\n",device);
int pt = open(device, O_RDWR | O_NOCTTY | O_SYNC); // retourne une erreur si le terminal n'est connecté à rien (pas de STM32 ni de Arduino dans notre cas)
if(pt == -1){
create_error_file(sensorAndPort->sensor, "impossible de se connecter au port série, veuillez vérifier le microprocesseur et la raspberry");
perror("in set_serial(...) - open");
pthread_exit(NULL);
}
//ioctl(pt, I_SRDOPT, RMSGD);
tcgetattr(pt, &old);
tcgetattr(pt, &tty);
cfsetispeed(&tty,B9600); // la valeur du baudrate est fixé à 9600 baud
cfsetospeed(&tty,B9600);
tty.c_cc[VMIN] = 1; // Un caractère doit avoir été reçu dans le buffer pour que la fonction read() retourne quelque chose
tty.c_cc[VTIME] = 10; // Une valeur est fixé pour le time-out : à la fin de celui-ci read() retourne une valeur quoiqu'il arrive
tty.c_cflag |= CLOCAL;
tty.c_cflag |= CREAD;
cfmakeraw(&tty); // passage de la liaison série en mode non canonique et suppression des fioritures pour les utilisateurs d'un terminal classique
sleep(1); // nécessaire pour que le flush soit fait
if(tcflush(pt, TCIFLUSH)==-1){
perror("in set_serial(...) - tcflush");
pthread_exit(NULL);
}
if(tcsetattr(pt, TCSANOW, &tty)==-1){
perror("in set_serial(...) - tcsetattr");
pthread_exit(NULL);
}
if(cfgetispeed(&tty)!=B9600)
{
perror("in set_serial(...) - cfgetispeed");
pthread_exit(NULL);
}
return pt;
}
Ensuite, elle va lancer la fonction save_data() et reset_serial(). Cette dernière est utilisé en fin de lecture pour rétablir les paramètres de la liaison série tel qu’ils étaient avant le programme. La fonction save_data() va créer le fichier avec les valeurs du capteurs qui sont reçues. Une fois le fichier de sortie créé, une boucle infinie est créée dans laquelle on lit caractère par caractère la liaison série. Chaque caractère est immédiatement ajouté au fichier. Lorsque le signal d’arrêt du programme est reçu, la boucle infinie est quittée, le fichier de sortie est fermée puis la communication série est fermée et enfin le thread est arrêté.
Commit 40
Intitulé : "Spring : ajouts mineurs"
- Ajout de l'architecture des capteurs dans le fichier d'expérimentation YAML
- On ne peut maintenant sélectionner que des nœuds de même architecture pour une expérience
- Ajout du nom du répertoire où se trouve le fichier à compiler
- Vérification des fichiers pour avertir si un fichier est déjà nommé de la même manière lors de l'upload d'un nouveau fichier
- Passage de l'application sur le port 80
Annexes
Ferions-nous pas une partie un peu plus générale sur des sujets qui ont moins leur place dans les rapports hebdomadaires ?
Exemples :
- Détail de la classe de configuration de Spring Security
- Détail de l'architecture du projet
- Parler de Thymeleaf
Fonctionnement du projet Spring Boot
La gestion du routage des pages internet et de l'affichage des pages internet est géré par le fichier WebMvcConfig.java. Il gère les différents appels de l'utilisateur par les méthodes POST ou GET aux pages internet, ou aux actions de boutons. Ce fichier permet également d'envoyer des informations pour que Thymeleaf les utilise et affiche des éléments dynamiquement.
Ensuite, on utilise SecurityConfig.java pour gérer les accès aux pages de données en fonction du rôle des utilisateurs.
A continuer + schema
Documents Rendus
- Gitlab : https://archives.plil.fr/aduqueno/PFE_IMA5_2018_2019_P06
- Rendu intermédiaire : Fichier:PFE 06 Rapport Intermediaire.pdf
- Rendu intermédiaire (slides) : Fichier:Slides decembre pfe06.pdf
- Rendu final: Fichier:PFE06 Final.pdf