IMA5 2018/2019 P42 : Différence entre versions
(→Réalisation du Projet) |
(→Semaine 19&20) |
||
| Ligne 584 : | Ligne 584 : | ||
==Semaine 19&20== | ==Semaine 19&20== | ||
| + | |||
| + | Lors de la semaine 19, je me suis notamment intéressé à l'amélioration de l'extension web réalisée, ainsi que la mise en place du réseau de neurones. Les améliorations de l'extension dispose des points suivants : | ||
| + | |||
| + | * Obtention des scrollHeight et scrollWidth, afin d'obtenir la taille réelle de la page, et non seulement de la fenêtre visible. J'ai remarqué dans les données enregistrés que parfois, la taille renvoyée était bien inférieur à la position x ou y du curseur de la souris. | ||
| + | |||
| + | * Le point précédent permet de générer des pourcentages représentant la position du curseur par rapport à la page. Par exemple, si le curseur est aux positions (100, 100) d'une page dont la taille est de (1000, 1000), nous pourrons représenter sa position par (0.1,0.1), ce qui permet de normaliser les données pour le réseau de neurones entre 0 et 1 (normalisation nécessaire). | ||
| + | |||
| + | J'ai également pu mettre en place mon réseau de neurones, à la fois sur tensorflow et sur Keras. J'ai choisi de le réaliser en utilisant les deux frameworks en raison du fait que Keras permet la mise en place très rapide du réseau tandis que Tensorflow demande une connaissance plus détaillée et offre ainsi une plus grande maîtrise sur les paramètres du modèle. Sous Keras, le modèle est défini en une dizaine de lignes tandis que mon code utilisant tensorflow dispose de plus de 300 lignes de code : | ||
| + | |||
| + | [[Fichier:LSTM keras.png|500px]] | ||
| + | |||
| + | Mon architecture est composée de deux couches de LSTMs composés de 128 couches cachés chacune, dans une configuration many-to-many : c'est à dire que le réseau va prendre une séquence en entrée et générer une séquence en sortie. Ces couches sont suivis d'une couche dense disposant d'une unique sortie de dimension 2 (une dimension pour l'axe des abscisses et une pour l'ordonnée), retournant un nombre situé entre 0 et 1 représentant le pourcentage de la position du curseur par rapport à la page. | ||
| + | En écrivant ces lignes, je remarque que je n'ai pas prévu une entrée pour la taille de la page, que j'ajoute dès que possible en parallèle à la dernière couche LSTM et en entrée de la couche dense. | ||
| + | |||
| + | Sous Keras, l'entraînement est simple : il suffit de récupérer le dataset et de le diviser en trois sub-dataset : training, validation et test, puis d'appeler la fonction model.fit() sur le modèle créé. Sous Tensorflow, l'entraînement est plus manuel et requiert une compréhension plus avancée de la phase d'entraînement, allant de la définition et du calcul de la perte, jusqu'à la maîtrise du nombre de threads utilisés par l'entraînement. | ||
| + | |||
| + | Enfin, nous avons décidés de se lancer définitivement dans la mise en place de l'algorithme de parallélisation des crawlers en utilisant le reinforcement learning. J'ai pu lire deux papiers de recherches décrivant une démarche permettant de paralléliser les crawlers sur différents threads. | ||
| + | Connaître et comprendre leur approche me permettra de mettre en place l'architecture nécessaire à une parallélisation sur plusieurs machines. Les deux papiers m'ayant parus utiles sont les suivants : | ||
| + | * [https://arxiv.org/pdf/1602.01783.pdf| Papier original de l'A3C] | ||
| + | * [https://arxiv.org/abs/1705.04862| Amélioration du papier précédent] | ||
| + | |||
| + | Enfin, la semaine 19 à été conclus par l'execution avec succès de l'algorithme SARSA sur 500 épisodes (!), après m’être occupé du problème lié aux processus zombies. Le résultat permet clairement d'observer une tendance au fur et à mesure de l’exécution. Cependant, je trouve que ce n'est pas assez, en raison du fait que l'espace des états-actions est assez large, et 500 épisode n'est pas assez conséquent pour visiter toutes les paires d'état-action. Normalement, la parallélisation sur plusieurs machines devrait permettre de visiter d'avantage d'états et d'expérimenter d'avantage d'actions dans un temps réduit. | ||
| + | L'architecture de ma vision de l'A3C adaptée à plusieurs machines est la suivante : | ||
| + | |||
| + | [[Fichier:A3C multiple machines architecture.png|600px]] | ||
=Documents Rendus= | =Documents Rendus= | ||
Version du 17 février 2019 à 13:14
Sommaire
- 1 Présentation générale
- 2 Préparation du projet
- 3 Réalisation du Projet
- 4 Documents Rendus
Présentation générale
Description
Les empreintes de navigateur sont un moyen pour traquer les utilisateurs sans leur consentement, et sans laisser de traces, mais peuvent être également utilisés pour détecter des bots ou pour lutter contre la fraude. Les empreintes sont directement produits par les navigateurs et sont distribués par ces derniers sans autorisation préalable. Des contre-mesures contre le traçage d'empreintes de navigateur existent, notamment pour contourner les contrôles de sécurité contre les bots ou les fraudeurs. Il est ainsi question d'appliquer les avancées récentes de l'apprentissage automatique afin d’augmenter l’efficacité du fingerprinting ainsi que de détecter des cas d'incohérence ou de fraude. La collecte de données et la validation se fera à travers le site web http://amiunique.org .
Objectifs
L'objectif du projet est de mettre en place un algorithme utilisant les techniques du Reinforcement Learning (RL), afin de permettre à des bots informatiques, basés sur Pupetteer et Chrome Headless, ou d'autres technologies, de passer outre les défenses des sites web actuels. Il est ainsi question de permettre à notre bot, a travers un apprentissage basé sur des actions suivis de récompenses, d'apprendre par lui-même les actions nécessaires afin de s'éviter la détection.
Préparation du projet
Cahier des charges
Choix techniques : matériel et logiciel
Il n'y a aucun matériel particulier à utiliser dans le cadre de ce projet. Il serait néanmoins utile d'avoir accès à un ordinateur disposant d'une puissance calcul conséquente. Les langages de programmation utilisés seront les suivants :
- Javascript pour la mise en place du bot
- Python pour la mise en place des algorithmes de RL
Enfin, nous travaillerons tout au long de notre documentation dans l'environnement OpenAI (Python), qui propose de nombreuses ressources adaptés au Reinforcement Learning.
Liste des tâches à effectuer
Dans le cadre du projet, il est nécessaire de développer des connaissances avancés dans le domaine du Reinforcement Learning, qui constitue une branche à part du Machine Learning. Il est également nécessaire de développer une connaissance de l'état de l'art en terme de défense contre les bots informatiques. Enfin, dans l'objectif de répondre aux buts du projet, nous appliquerons nos connaissances en Reinforcement Learning, en choisissant et adaptant l'algorithme le plus approprié à notre problème. Il est également nécessaire de mettre en place en environnement d'entraînement factice afin de permettre à notre bot de procéder à son apprentissage, sans risquer un bannissement de l'adresse IP depuis laquelle le bot agit.
Calendrier prévisionnel
Nous tenterons dans un premier temps, idéalement dans le premier mois, de se documenter dans les domaines suivants :
- La théorie du Reinforcement Learning et l'implémentation des algorithmes
- L'état de l'art en terme de détection des bots
- L'état de l'art en terme d'implémentation de bots informatiques
Durant les mois suivants (Mi-Octobre 2018 - Décembre 2018), les objectifs seront :
- Mise en place de l'environnement d'expérimentation des bots implémentés
- Mise en place des algorithmes à utiliser
- Amélioration des algorithmes mise en place.
Enfin, les derniers mois seront consacrés aux tests et aux comparaisons entre différentes techniques utilisés.
Réalisation du Projet
Semaine 1
La première semaine à permis de mettre au clair les objectifs du projet et de définir le moyen de procéder afin d'atteindre notre but, à savoir : l'utilisation d'algorithmes de Reinforcement Learning afin de rendre notre bot indétectable.
Ainsi, j'ai pu me pencher en grande majorité sur l'état de l'art actuel en terme de détection de bots informatique. En extrayant les informations récupérés pour chaque sessions, plusieurs règles peuvent être déterminés et mènent à une détection plus ou moins probable du bot :
- [BLOG OR BOT](http://cs229.stanford.edu/proj2017/final-reports/5240610.pdf) Détection de bots informatique basés sur les mouvements de la souris et des touches utilisées. Cette solution produit un taux de 99.7% de TPR (True positive Rate) et seulement 0.2% de FPR (False Positive Rate).
- La durée de la session : une session est définie du moment qu'un agent accède au site internet (détecté par son IP, ou son empreinte) jusqu'à l'inactivité (?) de celui-ci.
- Le nombre de requêtes réalisés : un utilisateur normal tend à réaliser un nombre de requête significativement inférieur au nombre de requêtes réalisés par un bot.
- Le pourcentage de requêtes HTML : à définir
- Le nombre de requêtes sans la présence du header http referer : le header http referer contient l'adresse de la page précédente visité, menant à la page actuelle (par la présence d'un lien). Cet en-tête n'est pas défini dans le cas ou la resource précédente est représentée par une URI de type data ou si un différent de protocoles de sécurité existe entre les pages(de HTTPS à HTTP). Un pourcentage important de bots tendent à ne pas définir cet en-tête, ou a ne pas le définir correctement. A noter que les humains peuvent également désactiver cet en-tête.
- Pourcentage d'images récupérés : les bots tendent à ignorer les images.
- Pourcentage de requêtes PDF : Les bots tendent à les demander en totalité tandis que les humains tendent à selectionner leur utilisation.
- Utilisation du header HEAD : Le header HEAD est *parfois* (?) utilisé par les bots afin d'obtenir moins de données du site web. Le header HEAD permet de demander au site les headers qu'il aurait renvoyé dans le cas d'une requête GET classique. Un humain tend à ne presque jamais passer par la requête HEAD.
- Pourcentage d'erreurs 4xx : Les bots tendent à disposer de ce pourcentage plus élevé, en raison du fait qu' un bot tend à tenter d'accéder à des ressources sans en connaitre le contenu.
- Demande du robots.txt : un humain ne demande pas le robots.txt
- Pourcentage de requêtes HTTP sequentielles : les humains tendent à disposer d'un pourcentage plus élevés en raison d'une demande moindre pour des ressources de type script, images, doc...
- Standard deviation of requested page's depth. <--- Pas compris, a developper
- Adresse IP : Une utilisation intensive d'une adresse IP disposant des précédents attributs est douteuse.
J'ai également pu me renseigner sur l'état de l'art en terme de technologie utilisée dans la mise en place de bots : Chrome Headless est devenue la norme afin de mettre en place des bots ayant le moins de chance de détection. Un environnement headless représente un environnement sans GUI. Chrome headless est ainsi une "variante" du navigateur chrome, sans interface utilisateur, et ainsi, plus axée pour le testing automatisé, le développement de bots destinés au web crawling, ou toute sorte d'application ou la présence d'un GUI n'est pas requise. Puppeteer est la librairie Node officielle utilisant Chrome Headless afin d'exploiter le contenu de pages web.
Enfin, je poursuis mon étude des algorithmes de Reinforcement Learning : j'ai pu voir jusqu'à présent les algorithmes utilisés en Dynamic Programming. Ces algorithmes nécessitent la connaissance préalable de toute la MDP (Markov Decision Process), à savoir, une connaissance de toutes les valeurs associée à une action prise. Un environnement proche de la réalité bénéficie très rarement de cet avantage. En général, nous cherchons à déterminer les meilleures actions en explorant plusieurs différentes paires état-actions, qui risquent de présenter un meilleur avantage sur le long terme.
Semaine 2
J'ai pu, durant cette semaine, continuer mon apprentissage du reinforcement learning, des algorithmes, formules et notions associés. J'ai ainsi passé en revu la majorité des algorithmes utilisés dans l'état de l'art, à l'exception des algorithmes introduisant des réseaux neuronaux en raison du fait que cette approche ne pourra être considérée que dans le cas de limitation avérés des approches classiques.
J'ai également pu définir le problème et établir un modèle basique en termes de reinforcement learning, à discuter au cours de la semaine 3 avec mes tuteurs :
- But : Éviter la détection du bot par les systèmes de détection présents.
- Agent : Dans notre cas, un controlleur externe est plus approprié en raison du fait que la tache du bot doit correspondre uniquement à celle prédéfinie. Nous devons également pouvoir dimensionner la solution à plusieurs bots.
- Environnement : Le bot, controllé par l'agent, et son environnement, soit, la liste des sites web à explorer ?
- Action :
* Changement d'adresse IP * Varier le nombre de requêtes dans un même site web * Variation des mouvements de la souris et keystrokes * Variation de la durée de la session * Varier les headers HTTP * Varier le pourcentage d'images et de documents récupérés * Varier le taux de requêtes HTTP séquentielles. * Varier l'user agent * Varier la liste des plugins * Une action pour éviter de cliquer sur les liens cachés ? * Varier le délai de navigation entre deux pages
- États :
* Possibilité de définir les états par les sites web à visiter. * Possibilité de définir les états sur les hyperliens visités dans un même site web. * Etat terminal : soit le bot est bloqué, soit nous avons parcours la liste des sites web à visiter.
- Gains : (A développer)
* +1 Dans le cas d'un site crawlé sans détection. (Le taux de non-detection sera sûrement élevé, on ne prendre donc rarement en compte les gains négatifs. Solution : discounting factor si on décide de partir sur un gain positif) * -1 Dans le cas de détection. * 0 dans le cas d'une navigation dans un même site web sans détection.
- Politique d'action :
* Définies par notre algorithme dans le cas de l'utilisation des policy gradient methods. * Sinon, on cherche a minimiser la détection, donc optimiser les paramètres permettant de ne pas se faire détection.
Quels sont les possibles algorithmes suites aux conditions précédentes ?
Il est préférable de partir sur un algorithme off-policy dans le cas où nous n'utilisons pas les algorithmes de policy gradient, en raison du fait que nous désirons maximiser l'exploration et l'amélioration de différentes politiques d'actions. Il est également préférable de choisir un algorithme offline afin de mettre à jour les paramètres du modèle seulement à la fin de l'épisode.
- One-step auto-critic algorithm dans le cas ou un épisode correspond au parcours d'un site web, sinon, actor-critic algorithm with eligibility traces.
- REINFORCE with baseline.
- Q-learning car off-line.
- Semi-gradient TD(0)
Semaine 3
Cette semaine à été consacrée à la mise en place de l'environnement de test sous OpenAI Gym. OpenAI Gym est un toolkit permettant le développement et le test d'algorithmes de reinforcement learning. Il a été mis en place dans le but de standardiser les environnements de test, afin de simplifier l'implémentation des algorithmes issues de papiers de recherche. Notre modèlisation est finalement la suivante :
- Un site web est représenté par des features. Soit, la présence de fingerprinting, le fait que le site web bloque les bots ou pas, la présence d'un security provider qui peu être expliqué simplement par un serveur gérant la sécurité d'une multitude de sites web. Un site web dispose également d'un compteur de visite.
- Le security provider est représenté par un numéro, une note, qui va régir ses performances en terme de bloquage. Le security provider bloquera les bot dans un premier temps selon le nombre de fois que l'IP visite le site, ou bien le nombre de fois que l'user agent est apparu.
- Les états sont représentés par les features des sites web, un état contiendra les sites web ayant été visités entre 0 et 50 fois, dont le security provider à été visité entre 50 et 100 fois, disposant de fingerprinting et bloquant les bots.
- Les actions quant à eux correspondent à la visite d'un état particulier, au changement d'IP et au changement d'UA dans un premier temps. Nous aurons ainsi un nombre d'actions correspondant au nombre d'états + 2. Les actions seront à revoir par la suite car ce nombre limite les performances des algorithmes.
- Le bot est représenté par ses caractéristiques classiques, soit, son IP et son user agent en premier lieu. Ces caractéristiques seront améliorés par la suite pour mieux correspondre à la réalité.
L'environnement est développé en python, et disponible sur ce répo git : https://github.com/naifmeh/smartbot
Semaine 4
La semaine 4 à été consacrée à tester différents algorithmes sur la première version de l'environnement.
Nous testons notre environnement sur les algorithmes SARSA, Q-Learning et l'actor-critic (policy gradient methods). Les résultats dans le cas des deux premiers algorithmes sont prometteurs. A noter que dans cette première configuration, nous gardons le même set de sites web pour l'ensemble des épisodes. Las paramètres sont : 1000 steps par épisode, step size de 0.5 et espilon à 0.1 :
- SARSA en introduisant un faible reward négatif dans le cas de visite d'un état sans site web

- Q-learning dans la même configuration :

- Actor-Critic :

A noter également que les gains sont faibles en raison du fait que nous introduisons un gain négatif dans le cas du parcours d'un état vide de sites web.
Semaine 5
La semaine 5 à permis d'écrire de nouveaux algorithmes de RL, ainsi que de réaliser une petite présentation de l'avancement à l'INRIA, où nous avons pu discuter du modèle, des limitations de celui-ci, ainsi que des possibles améliorations. J'ai pu mettre en place les algorithmes n-step SARSA et SARSA(lambda). Le premier introduit une mise à jour des paramètres du modèle en plein épisode, ce qui permet à notre algorithme de mieux généraliser au fur et à mesure des épisodes.
En limitant le gain négatif en cas de visite d'un état vide à -0.1, en introduisant un gain de 5 en cas de crawl réussi, et en réinitialisant la liste de sites web à chaque épisode, nous obtenons de biens meilleurs résultats car l'algorithme est toujours confronté à de nouvelles situations. La configuration précédente introduisait un overfitting, les algorithmes s'adaptaient simplement à la configuration d'une mếme série de sites web. Nous remarquons que les algorithmes Q-Learning et SARSA, qui mettent à jour les paramètres du modèle uniquement à la fin de l'épisode, retournent des résultats très mitigés, tandis que l'actor critic, le n-step SARSA et le SARSA(lambda) montrent des belles performances :
- N-Step SARSA :


- SARSA(lambda) :

- Actor-Critic :

Après discussion lors de la présentation, nous avons pu mettre en avant les limitations du modèle : il est ainsi très difficile, dans le monde réel, de déterminer si un site web utilise le fingerprinting, à quel security providers plusieurs site appartiennent, et d'autres caractéristiques clés de notre modèle.
Ainsi, nous avons décidé de réaliser un second modèle utilisant comme états les configuration du bot. Chaque état correspond ainsi à une configuration précise du bot, à savoir, un user-agent, un proxy, le fait que le bot utilise ou non le header REFERER, ou le header HEAD, le taux de chargement des images et documents, qui va influer sur le temps de chargement des pages, que l'on cherche a minimiser.
Semaine 6
La semaine de pause m'a permis de mettre en place le nouveau modèle, toujours dans un environnement factice, utilisant comme états les configuration du bot. Comme annoncé, les états sont représentés par :
- L'user-agent
- Le proxy
- L'utilisation du header REFERER
- L'utilisation du header HEAD
- Le taux de chargement des images
- Le taux de chargement des documents (PDFs, etc...)
Les actions quant à eux sont les suivantes :
- Changer l'UA
- Changer le proxy
- Changer le referer
- Changer le header HEAD
- Changer de site web
- Augmenter/Diminuer le taux de chargement d'images
Les résultats pour les algorithmes QLearning et SARSA sont représentés par les graphiques suivants :
- QLearning pour un épisode de 1000 étapes. Le gain maximal est de 3000 car les rewards sont fixés à 3 pour un crawl réussi :

Le barplot, qui est plus explicite :

Nous pouvons ainsi voir que l'algorithme parvient à progresser et à se stabiliser aux alentours de 60% de crawls réussis (en ne comptant les sites non crawlés durant l'épisode.
- Sarsa dans les même configurations que précédemment :

Le barplot :

Les résultats sont similaires à précédemment, à l’exception que dans le cas de l'algorithme SARSA, nous commençons les premiers épisodes avec un reward très négatif. Cela peut s'expliquer par le fait que SARSA soit un algorithme on-policy et suivra ainsi une même policy tout le long de l’exécution tandis que le QLearning, étant off-policy, privilégieras l'exploration.
A première vue, ce modèle paraissait être le plus apte à être reproduit dans un cas réel. Cependant, après test avec les différents algorithmes implémentés jusque la, les résultats en ressortant sont très mitigés : nous retrouvons un taux de réussite qui progresse jusqu'à 60% en moyenne et dans les 80% dans le meilleur des cas. Nous souhaitons un système qui soit plus fiable et ne présente pas une variance aussi importante. La raison du non fonctionnement de ce modèle est notamment le nombre très élevés d'états générés, qui est de l'ordre de 10^6, et du nombre d'actions (car je considère les combinaisons d'actions élémentaires également), à 10^3. Ces modèles introduisant un nombre élevé d'état nécessitent des algorithmes de RL plus poussés: les algorithmes de Deep Reinforcement Learning (DRL) sont plus appropriés, mais nécessitent une puissance de calcul élevée. Nous implémenterons ces algorithmes lorsque notre modèle sera assez fiable.
Au vu des mauvais résultats, nous changeons une nouvelle fois de modèle et passons à un modèle plus simple, que nous améliorerons par la suite. Les états de ce modèle introduisent quelques caractéristiques de sites web facilement extraites, ainsi que deux caractéristiques du bot :
- Le fait que le site web bloque les bots
- Le fait que le site web utilise du fingerprinting
- L'intervalle de visite d'un site
- L'intervalle d'utilisation d'un UA
- L'intervalle d'utilisation d'un proxy
Les actions quant à eux sont représentés par :
- Choix d'un UA
- Choix d'un proxy
- Choix d'un site web
- Ne rien faire (maintenir la configuration)
J'ai également mis en place un crawler utilisant Puppeteer et Chrome Headless, afin de pouvoir récupèrer des informations détaillés sur certains proxies, à partir de la page : [[1]] .
L'objectif pour la semaine prochain est d'introduire notre modèle dans le cas réel et de le déployer sur les serveurs pour un test.
Semaine 7
L'objectif pour cette semaine était de finaliser le modèle précédent et de le tester, pour ensuite mettre en place le test en conditions réelles. J'ai pu finaliser le modèle, qui montre des des résultats assez mitigés une nouvelle fois. Nous pensons cependant que les raisons des résultats mitigés restent en grande partie dû au fait que nous sommes dans une modélisation, qui reste assez lointaine des conditions réelles. Nous pensons également qu'en modifiant un peu le dernier modèle, nous pouvons tester en conditions réelles. Les états sont légèrement modifiés pour contenir des informations plus détaillés sur les sites web :
- Le site vérifie-t-il le taux de chargement de documents ?
- Le site utilise-t-il le fingerprinting ?
- Le site vérifie-t-il la taille de l'écran ?
- Nombre de visites du site ? (Du coté du bot, plus c'est elevé, plus on privilégie le changement)
- Le site bloque-t-il les bots ?
- Le site verifie-t-il les plugins ?
- Le site analyse le pattern de la souris/clavier ?
- Le site vérifie les IPs/UAs ?
- Nombre de fois que notre IP à été utilisée
- Nombre de fois que notre UA à été utilisée
Du coté d'un épisode, un changement est a noter : un épisode est considéré comme toutes les visites de liens d'un même domaine, jusqu'à la fin de ceux-ci, ou le blocage.
Les actions ne changent pas. Nous ajoutons simplement l'action d'ajouter/supprimer un plugin.
Je suis ainsi en train d'écrire le programme de test. Le langage de choix est le Javascript sous NodeJS, en raison du fait que le crawler utilisera Chrome Headless et Puppeteer, et ce dernier ne dispose que d'une API en javascript. Il est ainsi plus raisonnable d'éviter de jongler entre les langages. Ne connaissant pas ce langage, je suis actuellement en train de parcourir la documentation du langage ainsi que la documentation de l'API.
Semaine 8
Cette semaine à été consacrée à l'écriture du code permettant de tester notre modèle en temps réel. Comme annoncé lors de la précédente semaine, le langage utilisé sera le Javascript sous NodeJS. La raison du choix de Javascript porte sur le fait que toutes les librairies permettant de réaliser des crawlers sont écrites en Javascript (à l'éxception de certaines d'entre eux). Ne connaissant absolument pas le langage et ses particularités, j'ai dû prendre quelques jours afin de me documenter et apprendre sur le langage au fur et à mesure que j'écrivais le programme principal. J'ai ainsi pu découvrir l'asynchronisme de Javascript, en utilisant la syntaxe ES6 (async/await), disponible depuis Node v7.0, et en évitant le plus possible les callbacks. L'asynchronisme est un atout dont nous pouvons profiter pour notre programme afin de pouvoir réduire le temps d’exécution, et notamment le temps d’exécution de la phase de pré-processing. Le gain en rapidité est fortement marqué par rapport au langage Python.
Le programme est organisé en modules et prend avantage des nombreux librairies déjà disponibles par commande npm. J'ai tenté de faire en sorte que le programme soit le plus modulaire possible, en divisant toutes les tâches dans différents modules réutilisables. La librairie Winston me permet de gérer les logs d'éxecution, tandis que j'utilise Chaï et Mocha pour les tests unitaires.
Description du fonctionnement du programme
- Phase de pré-processing :
La phase de préprocessing me permet de générer les différents attributs de chaque site web à crawler, ainsi qu'a générer les différents liens que notre bot visitera. Dans le premier cas, durant le temps de mettre en place le script, je dispose déjà d'une base de donnée de plus de 10000 sites web dont les attributs sont déterminés, et qui m'a été fournie par Antoine. Cette liste est stockée dans un document mongodb. J'ai ainsi mis en place un module me permettant de récupérer les différents éléments de la collection. Je dispose également d'un fichier csv fourni encore une fois par Antoine, déterminant si le site web utilise le fingerprinting, ou bloque les bots. La génération des liens se fait simplement en générant le sitemap du site web et en choisissant un nombre limité de liens. La phase de pré-processing permet ainsi de combiner les trois opérations précédentes, à savoir, la lecture de la BDD, la lecture et l'interpretation du fichier csv, et la génération du site map, en un objet javascript contenant les attributs suivants pour chaque site web :
{ 'hostname': {
urls: ['url1', 'url2'],
hostname: 'hostname',
fingerprinting : boolean,
screen_size: boolean,
block_bots: boolean,
mouse_pattern: boolean,
plugins: boolean,
ua_proxy: boolean,
visits: integer,
uas: [{'ua1':integer}, {'ua2': integer}],
ips: [{'ip1':integer}, {'ip2': integer}]
},
'hostname2':....
}
Nous obtenons ainsi un objet JSON contenant plusieurs objets JSON dont les attributs sont représentés par des booléens. True pour un attribut vérifié, false pour le contraire. Le choix des objets JSON est important car il nous sera plus facile à sérialiser dans le cas où nous souhaiterons interrompre le programme et repartir du même endroit.
Nous générons également les états, qui ont été définis la semaine précédentes et qui seront surement modifiés encore une fois par la suite pour disposer de plus d'attributs. Actuellement, nous nous retrouvons avec 31800 états, ce qui est acceptable et laisse de la marge pour l'ajout d'autres états.
- Épisode :
Une étape fait partie d'un épisode. Le nombre d'épisodes sera défini à l'avance. Pour le moment, nous définissons un épisode comme le crawl d'un site web et de l'ensemble de ses urls. L'épisode se termine soit pas le bloquage du bot, soit par la visite de toutes les urls disponibles.
Le diagramme d'exécution pour un épisode est le suivant :

L'écriture du programme est encore en cours. Les actions n'ont pas encore été codés et la sérialisation n'a toujours pas été abordée. Le but de la semaine qui vient est ainsi de clore ces derniers points.
Semaine 9
Cette semaine, comme la semaine dernière, à été consacrée à la suite de l'écriture du programme principal. L'environnement réel est presque prêt :
- Les actions sont mises en places et testés.
- Les sites webs disponibles sont bien récupérés de la base de donnée sous Mongo DB, puis complétés par les informations sur le blocage contenus dans le fichier csv.
- Les états sont définis et générés.
- Les méthodes comptabilisant l'utilisation des proxy, et des user agents sont écrites et utilisent des listes doublement chainés afin de pouvoir récupérer le prochain proxy ou user agent lorsque notre algorithme décide de changer ces derniers paramètres.
- La fonction permettant de calculer les gains de notre agent est prête et prend en compte le nombre d'actions, le fait que le bot soit bloqué ou non, et le nombre d'actions inutiles, soit, les actions qui ne changent rien au bot.
Le grand ajout de cette semaine est la fonction permettant de détecter si notre bot à été bloqué ou non. En effet, contrairement à certaines croyances, le fait qu'une requête renvoi un code HTTP de type 4xx ou 5xx n'est pas le seul indicateur de blocage. La détection d'un blocage avec certitude est complexe, il est possible qu'un site détecte le bot mais ne choisisse de la bloquer que quelques pages visitées plus tard. Le site peut simplement être hors ligne au moment de la visite. Le bot peut également être considéré comme bloqué si un captcha s'affiche. CloudFlare, quant à lui, fournit un script permettant de detecter un bot lors d'une petite attente avant le chargement de la page. Le but principal de CloudFlare est cependant centré sur le blocage d'attaques DDOS, mais il se trouve qu'il permet également de bloquer les bots. Ma technique afin de pouvoir détecter le blocage est de mettre en place une regex qui va chercher les occurrences du mot "captcha" dans le code source de la page, ainsi que certains mots me permettant de déterminer si un script de CloudFlare est utilisé. J'ai pu remarqué que les sites contenant un captcha disposaient d'une occurrence du mot "captcha" proche ou supérieure à 10 tandis que CloudFlare utilise une phrase générique dans tout ses scripts, comme affiché sur l'image suivante :

Je cherche ainsi les occurences du mot cloudflare ainsi que des phrases génériques présentes dans leurs scripts. Si ces termes reviennent un nombre de fois prédéfini, je considère que le bot est détecté.
J'enregistre également un screenshot de la page visitée. J'ai également remarqué que lorsque le bot est bloqué, la page contient bien moins de contenu, et l'image de la page générée est de très petite taille. En général, elle fait moins de 150 Ko. Je vérifie ainsi cette propriété également.
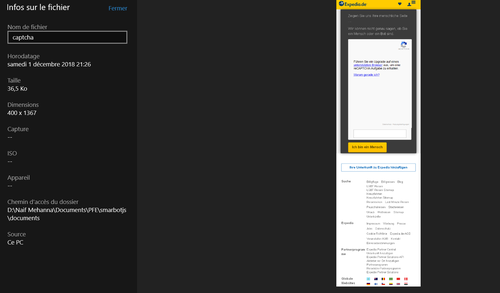
Le site d'Expedia.de affiche un captcha pour une image de 37 Ko
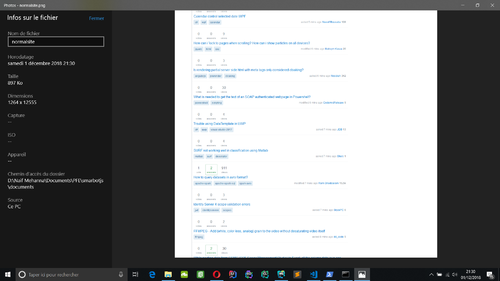
StackOverflow ne bloque pas le bot, et dispose d'une taille de +800 Ko


Enfin, afin de savoir avec certitude (on garde quand même un doute) si le bot à été bloqué, nous vérifions si plusieurs des techniques précédentes ont été utilisés.
Le but pour la prochaine semaine est ainsi de pouvoir tester le programme.
Semaine 10 & 11
La semaine 10, faute de temps et en raison de la présence de plusieurs DS, n'a pas permis d'avancer particulièrement sur le projet. Cependant, durant mon temps libre, j'ai pu finaliser l'écriture des fonctions principales du programme principal, à savoir, l'algorithme de Reinforcement Learning (SARSA), ainsi que les fonctions intermédiaires permettant de réaliser une étape, et de mettre à jour les paramètres de l'algorithme. Le crawler à également été complété avec l'ajout de plusieurs caractéristiques telles que la simulation de webdriver, la simulation de plugins ainsi que le chargement ou non des ressources CSS et documents de la page web. J'ai, dans le même temps, tenté de corriger la plupart des erreurs survenant durant l'exécution, telles que les interruptions des crawls et l'arrêt total de l'algorithme. Un exemple d'erreur qui survenait était lors de l'interruption du chargement des ressources : le crawler indiquait que les requêtes étaient déjà interceptés et arrêtait le crawl. J'ai pu régler ce soucis en activant les interceptions de requêtes avant la lancement du crawl.
La semaine 11 à été plus productive. J'ai pu mettre en place les fonctions de plotting, qui me permettront de visualiser les performances de mon modèle. Pour cela, j'utilise le module NodeJS Plotly, qui dispose d'une API simple et stable. Pour le moment, j'ai mis en place uniquement la fonction permettant de tracer les rewards en ligne. Il me faut également implémenter celle permettant de tracer les barplots. J'ai réglé la plupart des soucis rencontrés lors de l'execution du programme :
- J'ai tenté de reproduire le fonctionnement du DefaultDict en python, qui est pratique pour implémenter le tableau d'action-values Q. Le defaultdict permet de ne pas renvoyer d'erreur lors de l'accès à une valeur non existante, mais renvoi à la place une valeur initiale spécifiée. L'implémentation en Javascript est la suivante (spécifications ES6) :
class DefaultDict {
constructor(defaultInit) {
return new Proxy({}, {
get: (target, name) => name in target ?
target[name] :
(target[name] = typeof defaultInit === 'function' ?
new defaultInit().valueOf() :
defaultInit)
})
}
}
- Les pages web qui ouvraient une boite de dialogue requierant une action ne retournaient jamais en raison du await. Placer un timeout dans l'objet d'initialisation de puppeteer ne faisait effet que lorsque le site ne renvoyait aucune réponse HTTP. Afin de contourner ce soucis, j'ai mis en place un timeout de 30 secondes, qui renvoi une erreur récupérée dans un bloc try..catch et qui permet de retourner une réponse générique. Ce timeout est annulé si le programme fonctionne normalement.
- J'enregistre dans un fichier les rewards ainsi que les Q-values à chaque itération, ce qui me permet de ne pas perdre la progression de l'apprentissage en attente de l'écriture de fonctions de sérialisation fonctionnant pour l'ensemble du programme.
J'ai pu exécuter le programme sur 50 épisodes avant son interruption par une erreur sur laquelle je me penche actuellement. Le tracé n'est pas représentatif de la progression du bot en raison du fait que le nombre d'étapes par épisode varie pour chaque site web. Il me faut ainsi plutôt prendre en compte le pourcentage de bloquage par épisode, à la place du reward brut.

Le tracé précédent n'est pas représentatif de la progression et sera remplacé par un graphique plus représentatif.
Update du dimanche 16/12: J'ai pu modifier les paramètres de traçage et remplacer les rewards par un pourcentage de bloquage. Le résultat est le suivant :

Nous pouvons clairement apercevoir une tendance : au fur et à mesure des épisodes, nous avons tendances nous faire moins détecter et ainsi, moins bloqué. Cette tendance reste cependant à confirmer sur un nombre plus élevé d'épisodes. Je ne peux exécuter entièrement l'algorithme depuis chez moi en raison de restrictions liés à mon réseau internet qui bloque un bon nombre de pages.
J'ai également écrit le rapport de mi-projet ainsi que réalisé les slides de soutenance.
Semaine 12 + Vacances (13&14)
Durant la semaine 12, qui est celle de la soutenance, j'ai du me concentrer d'avantage sur la finalisation de mon rapport et la préparation de la présentation. Cependant, à la suite de ma soutenance, j'ai pu me pencher d'avantage sur un problème dans mon algorithme : les proxies récupérés étants des proxies gratuits, venant de free-proxy.net, ils sont de mauvaise qualité et sont très rapidment blacklistés, ou non fonctionnels. Une des solutions serait d'utiliser le prochain proxy fonctionnel dans la base de donnée et de rafraichir celle-ci à chaque fin d'épisode, mais cette opération augmentera considérablement le temps d'execution de notre programme. Antoine à ainsi pu envoyer une demande à Apify afin de nous fournir des proxies de qualité gratuitement dans des fins de recherche. En attendant, je me suis penché sur une solution qui était envisagée en début de projet, soit, d'utiliser plusieurs serveurs différents pour nos crawlers.
J'ai ainsi pu écrire un programme sous nodeJs utilisant une connexion websockets en utilisant la librairie ws (pour websockets). Ainsi, l'agent choisissant l'action de changer d'IP devra ouvrir une connexion websocket avec le serveur distant, transmettre la configuration du bot sous format JSON, cette action lançant ainsi le crawl par le bot correctement configuré. La réponse est ainsi retournée et la connexion websocket est fermée. La suite du traitement de cette réponse se déroule normalement, de la même manière que si le crawl avait été effectué sur la machine actuel.
Un exemple de données transmise (en orange), et retournée (en noir) est disponible ci-dessous :

Il manque maintenant simplement à intégrer cette action au programme principal, en remplaçant l'utilisation de proxies par la connexion à des serveurs distants. J'ai également commencé à me documenter sur les GAN (generative adversarial networks) afin de générer un pattern de souris qui puisse berner les sites web utilisant cette technique de détection.
Semaine 15
J'ai pu terminer l'écriture de l'algorithme en utilisant une liaison websockets permettant de lancer un nombre indéfini de crawlers à travers différents serveurs. Les tests se sont montrés concluants et je n'ai pas pu remarquer d'erreurs particulières lors de l’exécution. Les crawlers s’exécutant dans une machine virtuelle, il est nécessaire de désactiver l'environnement sandbox sous Puppeteer, sous peine de voir le crawler crasher à chaque page visitée. Pour ce faire, il suffit de spécifier l'argument --no-sandbox lors du lancement de puppeteer.
J'ai également placé une récompense négative sur chaque utilisant d'un crawler externe, afin d'éviter tout abus d'utilisation et de faire en sorte que l'algorithme ne choisisse cette action que lorsqu'il est nécessaire.
J'ai également pu ajouter les algorithmes n-step sarsa, et je travaille actuellement sur l'actor-critic. Ce dernier est pour moi un des algorithmes les plus importants à tester car il permet de déterminer la meilleure politique d'action, plutôt que d'associer des valeurs à des actions-états. Cependant, son écriture est plus complexe que prévu : les estimateurs de politiques et de valeurs-états étant représentés par des réseaux de neurones, il est difficile de retranscrire le code dont je dispose en Python, vers Javascript, en utilisant TensorflowJS, qui est bien moins complet que la version Python de l'API en raison des restrictions liés à l'environnement d’exécution (absence de multi-threading, utilisation de WebGL pour le GPU, etc...).
J'ai également réécris l'attribution des observations aux états avec des conditions qui permettent d'éviter un overflow du tableau préalablement défini.
Coté représentation de données, j'ai mis en place des barplots qui peuvent parfois porter d'avantages d'informations, afin de représenter les pourcentages de bloquage.
Le but pour la semaine prochaine serait d'obtenir des machines virtuelles au sein de l'INRIA afin de déployer mes crawlers et d’exécuter le programme. L’exécution de 100 épisodes peut prendre jusqu'à 8 heures, donc les tests des différents algorithmes risque de prendre énormément de temps.
J'ai également poursuivi ma documentation sur les modèles générateurs sans pour autant en faire une priorité pour le moment.
Semaine 16
Durant cette semaine, la priorité à été de lancer l'algorithme dans l'environnement réel. Dans un premier temps, je disposais d'une machine virtuelle au sein de l'INRIA, qui me permettait de lancer un serveur websocket, lançant le crawler à chaque requête. Nous avons tout d'abord eu un soucis avec le réseau interne de l'INRIA. Nous avons dû autoriser un port en local, afin que mon PC et la machine virtuelle puissent communiquer. L’exécution du programme étant assez lente, je n'ai pu l’exécuter que pendant 30 épisodes avant de devoir rentrer. Ces 30 épisodes ont cependant permis de déterminer une tendance positive.
Nous avons ensuite décidés de tester avec d'avantage de machines virtuelles. Cependant, j'ai rencontré quelques problèmes qui ont pris la journée à résoudre : certaines machines virtuelles n'étant pas dans le même réseau local, la communication entre elles étaient impossible. Nous avons donc dans un premier temps ouvert le port 80 sur une VM afin qu'elle puisse autoriser les connexion entrantes. J'ai ensuite pu obtenir trois autres machines virtuelles dans le même réseau local. Avant de lancer le programme, ayant écrit l'algorithme dans un environnement sous Windows (en raisons de restrictions liés à tensorflow), j'ai dû faire la transition vers Debian. J'ai rencontré quelques soucis, notamment, le fait que tout mes fichiers textes contenant la configuration du programme représentaient les sauts de lignes par '\n' en lieu et place d'un véritable newline.
Afin d'éviter de repartir de 0 à chaque fois, j'enregistre toutes les Q-values à chaque épisode dans un fichier et les récupère lors d'une réexecution du programme.
J'ai également pu écrire un programme qui m’envoie un mail à chaque changement dans le fichier contenant les résultats de l'algorithme (les retours cumulés ainsi que les Q-values). Ce programme tourne pendant 24 heures et se termine par lui même.
J'ai finalement lancé le programme avec trois crawlers avant de quitter l'INRIA. J'ai reçu des emails pendant approximativement cinq heures avant un arrêt des envois. Le processus lié à l'envoi des emails n'étant pas lié au processus de l'algorithme, je doute que la VM ait subie un redémarrage, ou encore, que les deux processus aient tentés d'accéder en même temps au fichier, provoquant une erreur. J'ai cependant les données d’exécution sur une cinquantaine d'épisodes, sur une base de sites webs différents que celle de mon expérimentation sur 30 épisodes.
.png)
Le tracé représente le pourcentage de blocage (ordonnés) sur un épisode en fonction des épisodes. A noter que l'échelle des ordonnées n'est pas représentatives des valeurs réelles, j'ai effectué un smoothing sur les valeurs avant de les tracer afin d'obtenir la tendance globale.
Nous pouvons clairement observer que les crawlers se font de moins en moins détecter au fur et à mesure que le nombre d'épisodes augmente.
Semaine 17 & 18
Durant cette semaine, nous avons continué les tests en environnement réel, cependant, l'une des machines, qui contenait l'instance principale de mon programme ne fonctionnait plus lors de mon retour. Ainsi, nous avons commencé à creuser dans les raisons qui poussent les machines à soit arrêter mon programme, soit s'éteindre : Antoine à émit l'hypothèse que cela peut être dû à un très gros trafic WS, en raison du fait que ma communication avec les autres crawlers ne s’effectue qu'uniquement par Web Sockets. Cependant, je penche d'avantage sur un soucis de mémoire. Nous pourrons en savoir plus dès que les machines seront relancés.
En attendant, j'ai décidé de lancer mon programme depuis mon instance AWS. Nous avions cependant des réserves la dessus car les IPs des instances virtuelles EC2 sont généralement mal vues par les security providers de certains sites web. Je dispose personnellement d'une instance t2.micro, qui dispose de caractéristiques telles que 1G de RAM et 8G de HDD. La distribution linux installée occupe plus de 5G et mon image docker occupe les 90% d'espace restant. Docker utilise près de 80% de la RAM. Mon instance n'était donc pas assez puissante pour faire tourner mon programme.
Lors de la remise en place des machines, j'ai pu analyser les logs de mon programme et déduire les causes des arrêts: comme je m'en doutais, la mémoire était en cause en raison d'un bug connu de Puppeteer (pas si connu que ça vu que je n'en avais jamais entendu parler). Lors de la fermeture du navigateur headless en effectuant un browser.close(), Puppeteer, par moment, laisse des processus zombies qui tournent en fond. Sachant que mon programme ouvre et ferme des milliers d'instances de chrome headless, nous avons un nombre bien plus important d'instances zombies qui restent ouverts, et qui consomment un infime pourcentage de la mémoire, qui s'accumulent au fur et a mesure, jusqu'a provoquer un overflow.
En cherchant sur les solutions de résolution de ce soucis, j'ai découvert que je pouvais le limiter, mais pour le moment, je n'ai pas pu le supprimer entièrement. Une des solutions pour supprimer entièrement ce soucis est de récupérer les PID des instances zombies et d'envoyer un SIGKILL, cependant, en effectuant cette action, mon programme est terminé également. Ainsi, comme solution temporaire, j'empêche simplement une partie de ces instances inutiles de se lancer à la base.
Pour le moment, mon algorithme dispose de 3 algorithmes dont je veux évaluer les performances sur mon environnement :
- Sarsa
- N-step Sarsa
- QLearning
Cependant, ces 3 algorithmes correspondent à une classe d'algorithmes en RL que l'on appelle Value Based Methods et qui complètent une autre classe de méthodes basés sur la politique (Policy based methods), tels que les algorithmes REINFORCE et Policy Gradient. La première classe exploite d'avantage les méthodes de Monte-Carlos et le dynamic programming tandis que la seconde classe cherche à directement optimiser la politique de notre environnement. Cette dernière méthode est d'avantage appropriée pour les environnements continus tels que le notre, où la meilleur politique est à déterminer continuellement, plutôt que d'associer une valeur à chaque action.
Cependant, au vu des bons résultats des deux méthodes dans des environnements adaptés, les chercheurs se sont demandés comment associer ces deux méthodes et ainsi obtenir une performance plus élevée et assurer leur convergence. C'est de la que sont nés la classe d'algorithme que l'on appelle Actor-Critic, qui sont basés sur deux réseaux de neurones basiques :
- Le critique, qui mesure à quel point l'action choisie était réussie (value-based)
- L'acteur qui contrôle la manière dont notre agent se comporte (policy-based)
Les algorithmes basés sur l'actor-critic sont essentiels en RL, étant à la base des algorithmes de l'état de l'art tels que PPO (Proximal Policy Optimization). Il est également à noter que les meilleurs résultats en deep RL sur les jeux d'Atari ou de NES64 ont été obtenus par les méthodes d'actor-critic.
Ainsi, une partie de cette semaine à été consacrée à la finalisation de l'écriture de l'algorithme A2C (Advantage Actor Critic), avec un unique agent (on pourra l'étendre à plusieurs agents en parallèle). La difficulté de l'implémentation résidait dans le fait que j'utilise Tensorflow.JS, tandis que ma première implémentation était faite sous Tensorflow (Python). Les différences entre Tf.Js et Tf sont conséquentes: lorsque le second détient une approche en graphes, le premier privilégie une approche séquentielle, basée sur Keras. En python, il est commun d'initier le graph, d'initier des placeholders, une sorte de buffer pour des matrices vides, là ou des matrices sont requises, puis lors de l’exécution, de fournir les valeurs à ces placeholders. Sous tf.js, l'approche est différente, car tout est à construire à la suite et les valeurs sont à fournir dès l’exécution. Nous notons également de nombreuses différences dans les fonctions présentes dans une API et pas dans l'autre.
Ainsi, lors de la semaine 17, j'ai pu bien avancer dans l'écriture de l'algorithme, mais je disposais d'un problème à résoudre au niveau de la matrice d'entrée : j'utilise le oneHot encoding, qui permet de transcrire un état en une matrice composés de 0 et de 1.

Cependant, j’initialisais la valeur d'entrée (mon état) en utilisant la fonction tf.input(), que je considérait analogue au placeholders en Python, et qui renvoyait un SymbolicTensor tandis que le premier paramètre de tf.oneHot() n'accepte que des types tf.Tensor. Ne trouvant pas de solutions, j'ai ouvert un fil sur StackOverflow, qui m'a permis d'y voir plus clair.
Ainsi, lors de la semaine 18, j'ai pu finaliser mon algorithme et tester celui-ci pendant un petit moment, sur une quarantaine d'épisodes (pas suffisant, mais la VM ne disposait pas de GPU, donc j'ai du l’exécuter sur mon PC, et donc l'arrêter lors de mon départ), dont je présenterai les résultats par la suite.
En attendant l’exécution des algorithmes, qui pour notion, tournent pendant 24h pour 200 épisodes, Antoine et moi avons décidés qu'il était judicieux de commencer à travailler sur la partie optionnelle du projet : la génération d'une séquence de souris similaire à celle d'un humain, afin d'éviter la détection d'un bot basé sur ce critère. Ainsi, la procédure de réalisation est la suivante :
- Écriture d'une extension chrome/firefox permettant de récupérer les données utilisés pour l’entraînement.
- Mise en place de l'architecture du réseau de neurone utilisé.
- Implémentation et entraînement
La semaine 17 à permis de commencer l'écriture de l'extension, et ainsi, de me documenter sur les façons d'en écrire une, et de commencer à discuter de l'architecture du réseau de neurones. Nous avions dans un premier temps penchés pour l'utilisation de Generative Adversarial Networks (GAN) pour l’entraînement : la compréhension de l'architecture GAN est simple. Elle se compose de deux réseaux de neurones qui sont des adversaires : l'un, le générateur, va générer des données, et le second, le discriminateur, va chercher à déterminer si ces données proviennent d'un set d'entraînement (donc des données réelles), ou ce sont des données générés par le générateur. Le résultat du discriminateur, va ensuite être utilisé afin de tweeker les paramètres du générateur afin que sa prochaine génération soit meilleure, jusqu'à ce que le discriminateur ne puisse plus différencier une donnée générée d'une donnée provenant du set d'entraînement.
Mathématiquement parlant, le générateur va tenter d'approximer la distribution de probabilité du set d’entraînement. Cette partie sera développée dans le rapport.

Cependant, en y réfléchissant d'avantage et en étudiant cette méthode (C-RNN-GAN: Continuous recurrent neural networks with adversarial training), j'ai pensé que nous pouvions faire bien plus simple qu'une architecture GAN. L'idée principale est de pouvoir observer la page, et de générer une séquence de coordonnées vers une cible. Ainsi, en séparant ces deux taches :
- Dans un premier temps, nous observons la page et nous en reportons des features.
- Dans un second temps, en utilisant ces features, nous générons une *séquence* de coordonnées.
La première tache est facilement résolue en utilisant un CNN (Convolutional Neural Network), qui sont particulièrement adaptés aux tâches de traitement d'image et permettent d'extraire des features de manière relativement simple. De plus, l'état de l'art met en avant de nombreuses architecture qui tendent à utiliser de moins en moins de ressources (i.e MobileNet). La seconde tâche peut être résolue en utilisant des RNN (Recurrent Neural Networks) qui introduisent la notion de temps et ainsi de séquences liés entre elles dans le temps, soit, une sortie est directement dépendantes des sorties précédentes.
Ainsi, je voyais deux choix d'architecture : soit une architecture séparant les deux tâches, en l’occurrence, un CNN simple, et un RNN utilisant les données précédentes afin de générer la séquence, soit une architecture CNN-RNN qui englobe tout à la fois. Le type de RNN que j'ai décidé de choisir est le LSTM, qui permet de prendre en compte des données qui remontent bien plus dans le temps, et d'introduire la notion d'oubli. (Il existe trois types de RNN, le RNN simple, le LSTM et le GRU) Ainsi, dans un premier temps, j'ai étudié l'architecture CNN-LSTM, que plusieurs papiers introduisaient :
- CONVOLUTIONAL, LONG SHORT-TERM MEMORY,FULLY CONNECTED DEEP NEURAL NETWORKS
- Show and Tell: A Neural Image Caption Generator
- Learning CNN-LSTM Architectures for ImageCaption Generation

Les deux derniers papiers introduisent l'utilisation du CNN-LSTM dans le cadre de la génération de descriptions pour une image passée en entrée. Cette application est relativement proche de mon but : la génération d'une description correspond simplement à une génération d'une séquence de mots connectée entre eux par leur positions dans la phrase. Mon but est similaire, seulement que les mots sont replacés par des coordonnées. J'ai pu extraire quelque phrases relativement importantes dans la compréhension des papiers précédents et de la phase d’entraînement de ce type d'architecture. Quelque questions étaient ainsi levés après lecture :
- Que représente exactement la sortie du CNN ?
- Combien de cellules LSTM doivent être présentes dans le LSTM ? Doit-on plutôt partir sur une approche many-to-many ou one-to-many ?
- Si nous choisissons un nombre fixés de cellules, et une approche many to many, la sortie de chacune de ces cellules correspondra à une prédiction ou la prédiction correspond simplement à la dernière cellule ?
- Dans le cas où chaque cellule prédit un élement de la séquence, pourquoi les papiers précédents spécifient "As words are predicted, we feed the current predicted sentence back into the LSTM in order to generate the next word" ? Cela ne contraste-t-il pas avec la citation suivante : "Each next hidden state in the LSTM emits a prediction for the next word" ?
Ces questions devront trouver une réponse si nous décidons de partir sur cette architecture.
Lors de la semaine 18, j'ai pu présenter mes hypothèses et discuter de la viabilité de l'architecture. Antoine s'est opposé à l'utilité d'interpréter visuellement l'image, alors que nous disposons du code HTML et de la position du bouton a cliquer, ce qui est une objection légitime. Cependant, je voulais que le crawler agisse comme un être humain : un être humain observe la page, le cortex visuel transmet l'information vue au cerveau, celui-ci l'interprète et renvoi ainsi l'action à effectuer. Nous nous sommes finalement accorder pour commencer par un LSTM simple, qui prendra ainsi en entrée la coordonnée cible et générera une séquence de coordonnées, et ainsi, par la suite si le temps le permet, introduire l'interprétation visuelle.
Une fois fixés sur l'architecture, j'ai pu continuer à développer l'extension qui permettra de récupérer les données d’entraînement. L'extension permet de récupérer un cycle de souris (un cycle correspond aux coordonnées jusqu'à un clic), de prendre un screenshot de la page, récupérer son contenu HTML et des informations concernant le viewport, et d'enregistrer le tout en passant par une API REST. L'architecture est la suivante :

L'extension à été terminée le vendredi 1 février.
Finalement, j'ai pu exécuter quelques algorithmes durant un certain nombre d'épisodes, dont voici les résultats :
- QLearning : (sur 80 épisodes)

- N-step SARSA : (sur 190 épisodes)

A noter que tout les algorithmes tournent dans les même conditions et avec la même base de données de sites webs. Nous pouvons ici remarquer le comportement erratique du N-Step SARSA comparé à son homologue SARSA de la semaine 16, qui lui même performe moins bien que le QLearning. Il manque cependant les résultats de l'A2C, qui viendront dès son exécution.
Je pense également à paralléliser les crawlers en utilisant l'algorithme A3C, pour Asynchronous Advantage Actor Critic, qui, comme son nom l'indique, permet de paralléliser les agents, tout en utilisant la même base pour le choix des actions (les même réseaux de neurones pour l'acteur et la critique).
Semaine 19&20
Lors de la semaine 19, je me suis notamment intéressé à l'amélioration de l'extension web réalisée, ainsi que la mise en place du réseau de neurones. Les améliorations de l'extension dispose des points suivants :
- Obtention des scrollHeight et scrollWidth, afin d'obtenir la taille réelle de la page, et non seulement de la fenêtre visible. J'ai remarqué dans les données enregistrés que parfois, la taille renvoyée était bien inférieur à la position x ou y du curseur de la souris.
- Le point précédent permet de générer des pourcentages représentant la position du curseur par rapport à la page. Par exemple, si le curseur est aux positions (100, 100) d'une page dont la taille est de (1000, 1000), nous pourrons représenter sa position par (0.1,0.1), ce qui permet de normaliser les données pour le réseau de neurones entre 0 et 1 (normalisation nécessaire).
J'ai également pu mettre en place mon réseau de neurones, à la fois sur tensorflow et sur Keras. J'ai choisi de le réaliser en utilisant les deux frameworks en raison du fait que Keras permet la mise en place très rapide du réseau tandis que Tensorflow demande une connaissance plus détaillée et offre ainsi une plus grande maîtrise sur les paramètres du modèle. Sous Keras, le modèle est défini en une dizaine de lignes tandis que mon code utilisant tensorflow dispose de plus de 300 lignes de code :

Mon architecture est composée de deux couches de LSTMs composés de 128 couches cachés chacune, dans une configuration many-to-many : c'est à dire que le réseau va prendre une séquence en entrée et générer une séquence en sortie. Ces couches sont suivis d'une couche dense disposant d'une unique sortie de dimension 2 (une dimension pour l'axe des abscisses et une pour l'ordonnée), retournant un nombre situé entre 0 et 1 représentant le pourcentage de la position du curseur par rapport à la page. En écrivant ces lignes, je remarque que je n'ai pas prévu une entrée pour la taille de la page, que j'ajoute dès que possible en parallèle à la dernière couche LSTM et en entrée de la couche dense.
Sous Keras, l'entraînement est simple : il suffit de récupérer le dataset et de le diviser en trois sub-dataset : training, validation et test, puis d'appeler la fonction model.fit() sur le modèle créé. Sous Tensorflow, l'entraînement est plus manuel et requiert une compréhension plus avancée de la phase d'entraînement, allant de la définition et du calcul de la perte, jusqu'à la maîtrise du nombre de threads utilisés par l'entraînement.
Enfin, nous avons décidés de se lancer définitivement dans la mise en place de l'algorithme de parallélisation des crawlers en utilisant le reinforcement learning. J'ai pu lire deux papiers de recherches décrivant une démarche permettant de paralléliser les crawlers sur différents threads. Connaître et comprendre leur approche me permettra de mettre en place l'architecture nécessaire à une parallélisation sur plusieurs machines. Les deux papiers m'ayant parus utiles sont les suivants :
Enfin, la semaine 19 à été conclus par l'execution avec succès de l'algorithme SARSA sur 500 épisodes (!), après m’être occupé du problème lié aux processus zombies. Le résultat permet clairement d'observer une tendance au fur et à mesure de l’exécution. Cependant, je trouve que ce n'est pas assez, en raison du fait que l'espace des états-actions est assez large, et 500 épisode n'est pas assez conséquent pour visiter toutes les paires d'état-action. Normalement, la parallélisation sur plusieurs machines devrait permettre de visiter d'avantage d'états et d'expérimenter d'avantage d'actions dans un temps réduit. L'architecture de ma vision de l'A3C adaptée à plusieurs machines est la suivante :

Documents Rendus
- Git du test : https://github.com/naifmeh/smartbot
- Git du crawler en conditions réelles: https://github.com/naifmeh/smartbotjs
- Rapport intermédiaire de PFE (le 17/12 à 20:31) : Rapport de mi-projet
- Soutenance intermédiaire (le 18/12 à 21:50): Slides de soutenance intermédiaire