IMA4 2017/2018 P44
Sommaire
- 1 Projet IMA4 : Reconnaissance d'objets via traitement d'images
- 2 Analyse du projet
- 3 Préparation du projet
- 4 Réalisation du Projet
- 4.1 Feuille d'heures Janvier
- 4.2 Janvier: Séance 1.0
- 4.3 Janvier: Séance 1.1 - 15/01/18
- 4.4 Janvier: Séance 1.2 - 17/01/18
- 4.5 Janvier: Séance 1.3 - 18/01/18
- 4.6 Janvier: Séance 2.0 - 22/01/18
- 4.7 Janvier: Séance 2.1 - 24/01/18
- 4.8 Janvier: Séance 2.2 - 25/01/18
- 4.9 Janvier: Séance 3.0 - 29/01/18
- 4.10 Janvier: Séance 3.1 - 31/01/18
- 4.11 Feuille d'heures Février
- 4.12 Février : Séance 1 - 07/02/18
- 4.13 Février : Séance 2 - 14/02/18
- 4.14 Février : Séance 3 - 21/02/18
- 4.15 Feuille d'heures Mars
- 4.16 Mars : Séance 1 - 07/03/18
- 4.17 Mars : Séance 2 - 14/03/18
- 4.18 Mars : Séance 3 - 21/03/18
- 4.19 Mars : Séance 4 - 28/03/18
- 4.20 Feuille d'heures Avril
- 4.21 Avril : Séance 1 - 04/04/18
- 4.22 Avril : Séance 2 - 11/04/18
- 4.23 Avril : Séance 3 - 18/04/18
- 4.24 Avril : Semaine de l'Open German
- 5 Documents Rendus
Projet IMA4 : Reconnaissance d'objets via traitement d'images
Description
L’Association de Robotique de Polytech Lille a pour but principal de participer à la RoboCup, compétition internationale de robotique, dans la Logistic League. Pour l'instant une machine de production (MPS) est identifiée par un AR Tag (QR Code). Le but de ce projet est de réussir à identifier une machine par une autre façon, sans utiliser les tags, mais en identifiant les structures de production qui sont positionnées sur chaque MPS. Il y en a 5 types:
- une Base Station à 3 tours de stockage pour chaque couleur de base ;
- une Cap Station à un rail de dépôt pour l’ajout de bases ;
- une Delivery Station à 3 voies de stockages pour les produits finis ;
- une Ring Station à 2 structures pneumatiques de dépose de cap ;
- une Storage Station à 1 structure en étagère assez haute.





Chaque machine à 2 types de côté: actif, large où le robot interagit ou ignorés, étroit où il n'y aura pas d’interaction.
On a la liberté du choix du moyen de vision: une ou deux caméras (stéréo vision), une Kinect, un scanner laser, une Intel SR300 ... mais il faudra veiller à choisir un système efficace et robuste.
Ce sujet permettra d'aborder les notions de développement logiciel en C et Python, du framework robotique ROS, mais également le travail en équipe et pourquoi pas la participation à une compétition internationale de robotique en avril (Open German à Magdebourg, Allemagne).
Objectifs
L'objectif principal de notre projet est donc d'analyser le plus rapidement possible et avec une fiabilité maximale face à quelle machine de production le robot se situe. Il faudra donc trouver une caractéristique unique pour chaque machine de production afin de les différencier le plus rapidement possible. Et si ce n'est pas possible (si 2 machines sont trop semblables) pouvoir comparer l'image vue par le robot avec les caractéristiques visuelles générales de chaque MPS. Ainsi la storage station est facilement identifiable par sa taille mais les autres MPS semblent relativement semblables aux premiers abords. Une analyse en détail de leurs dimensions va nous permettre d'évaluer s'il serait possible de les différencier facilement. Par exemple la cap station pourrait être identifiée par son rail. On pourrait également s'appuyer sur les différences de profondeur de certaines zones des MPS pour les différencier, grâce au capteur infra rouge notamment .
Lors de la compétition 3 minutes maximum sont allouées à la phase d'exploration.
Il s'agira de reconnaissance spécifique: identifier une MPS en particulier sur une image.
Analyse du projet
Positionnement par rapport à l'existant
Il y a de nombreux projets et de plus en plus de projets sur la reconnaissance d’objets par traitement d’image, notamment dans la recherche. Ces projets sont le plus souvent axés sur un axe industriel , comme pour ce projet. Ou sur une utilisation dans la vie quotidienne: robot humanoïdes, reconnaissances d’objets de formes basiques (cubes …) comme dans certaines compétitions de robotique. Comme ce sera le cas pour nous, grand nombre de ces projets ne fonctionnent que dans des conditions particulières: un nombre d’objets limité et un environnement connu. En effet il est très difficile de programmer un robot pour qu’il puisse reconnaître tous les objets existants. Une difficulté importante pour la reconnaissance d’objets sont les variations: de luminosité, de taille de l’objet, de son orientation … De nombreuses applications de détection d’objets sont développées sur l'OS ROS.
Analyse du premier concurrent
L’API CLOUD VISION de Google permet de comprendre le contenu d'une image en intégrant de puissants modèles de machine learning dans une API facile à utiliser. Cloud Vision classe les images rapidement dans des milliers de catégories (par exemple, "bateau", "lion", "tour Eiffel"). L’avantage de la solution présentée par notre projet et de pouvoir reconnaître les objets plus précisément, en effet il ne s’agit pas de savoir que c’est juste une MPS comme pourrait le faire cette API mais de préciser de quelle MPS il s’agit. L’avantage de CLOUD VISION est qu’il peut concerner un domaine plus large et est plus applicable à différentes compétitions. En effet l'API Vision s'appuie sur la puissance de la fonctionnalité de recherche de Google Images pour trouver des entités thématiques, elle permet donc par exemple de reconnaître des logos.
Analyse du second concurrent
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4029636/ Ce projet s’appuie sur une Kinect comme nous pouvons envisager de le faire. La Kinect est ici utilisée pour reconnaître les contours de l’objet. Le projet réalisé par Carlos Astua, Ramon Barber, Jonathan Crespo, et Alberto Jardon décrit dans cet article met en avant la difficulté à reconnaître un objet en fonction de la position du robot.
Scénario d'usage du produit ou du concept envisagé
Après des semaines d'intense préparation le Robotino de l'association de robotique de Polytech Lille est prêt à entrer en piste pour l'épreuve de Logistique de la Robocup 2018. Il s'agit d'une compétition en 1 contre 1 où l'objectif est de marquer le plus de points en un temps imparti. Sa première mission et celle qui fait référence à notre projet est la phase d'exploration: il va devoir analyser les 14 machines de production présentes sur la piste (emplacement et orientation aléatoire) pour définir leur type. Chaque équipe est associée à 7 MPS. Le robotino va donc se déplacer face à chaque MPS et l'analyser par le traitement d'image pour repérer de quelle type de machine il s'agit. Pour repérer ces machines et leur position il a un temps imparti de 3 minutes.
Réponse à la question difficile
Comment communiquer avec la Caméra?
Il nous faut un moyen de communication qui nous permette d'une part de récupérer ce que voie la caméra, de pouvoir le traiter et de pouvoir comparer ces informations avec ce que nous savons sur les MPS.
Le plus difficile est de trouver comment traiter les informations récupérée via la caméra. Cela sera rendu possible par l'utilisation d'une RaspberryPi alimentée par le robotino.
Préparation du projet
Cahier des charges
L'objectif est de permettre au Robotino de différencier 5 machines de production connues d'avance dans le cadre d'un challenge de robotique. Les caractéristiques principales de l'environnement sont également connues d'avance. Pour cela nous possédons les modélisations en 3D des MPS au format WRL (juste ici https://github.com/robocup-logistics/full-size-models/tree/master/mps). L'objectif est donc de pouvoir sur place la MPS située face au robot avec les informations que nous connaissons sur les 5 types de MPS, au moyen d'une kinect vraisemblablement.
L'objectif final est que notre projet fonctionne de la manière suivante :
- Récupérer l'image vue par la caméra(profondeur)
- Extraire les contours
- Comparer avec les contours connus des MPS
- Si il y a correspondance à plus de 70%, envoyer l'id de la machine au Robotino
- Sinon se placer sur un autre côté de la machine puis retour étape 1.
Pour cela nous devrons:
- Créer plusieurs vues des différentes MPS à partir des modélisations 3D à notre disposition
- Extraire les contours de ces images(formes, nombre de formes, placement)
- Si après avoir analysé les 4 faces de la MPS il n'y a aucune correspondance à plus de 70%, faire la moyenne des correspondances pour les 4 faces pour chaque MPS et choisir celle qui a le taux de correspondance le plus élevé (*)
Remarques:
- Si une machine a déjà été reconnue autant de fois qu'elle se trouve sur le terrain (information connue préalablement) on effectuera pas de comparaison avec les images de celle-ci puisque c'est inutile (optimisation du temps)
- Si a un moment donné, il y a le même taux de correspondance pour 2 MPS après l'analyse des 4 phases, envoi des 2 ID au Robotino. A la fin de l'analyse on pourra déduire le vrai ID puisqu'on connaît le nombre de MPS de chaque type présentes sur le terrain.
- (*) Sauf si le taux de correspondance est inférieur à 40% on envoie "on ne sait pas".
Choix techniques : matériel et logiciel
Pour le choix du moyen de prise d'image:
- la stéréo vision (utilisation de 2 caméras) nécessite l'acquisition d'au moins 2 images de l'objet à mesurer de 2 points de vues différents. Après la prise de vue de la MPS les coordonnées d'image (couple stéréoscopique) des points à mesurer sont déterminées sur chaque des images puis mises en concordance. Pour déterminer les dimensions de l'objet il est nécessaire détalonner le système de mesure. Problématique: étant donné la taille du robot par rapport à celle des MPS, sera-t-il possible de prendre les 2 images de l'objet en laissant le robot immobile face à la MPS (en plaçant les 2 caméras à des endroits différents du robot) ? Si ce n'est pas possible il faudra donc que le robot se déplace par rapport à la MPS, ce qui rendrait le processus de reconnaissance plus long.
- la kinect possède une caméra RGB ainsi qu'une caméra infrarouge, cette caméra infrarouge permet de mesurer les différences de profondeur.
Avantage: Avoir une image infrarouge avec les différences de profondeur des objet présents dans le visuel du robot pourrait nous être très utile pour différencier les différents MPS.
Problématique: la caméra RGB et la caméra infrarouge ne sont pas situées au même endroit sur la kinect, nous auront donc 2 prises de vues non superposables. Serait-il possible d'utiliser uniquement la caméra infrarouge ? Ou de synchroniser les 2 images ?
Kinect V1 - Champ de vision :
Champ de vision horizontal : 57 degrés
Champ de vision vertical : 43 degrés
Marge de déplacement du capteur : ± 27 degrés
Portée du capteur : 1,2 m – 3,5 m - la caméra Intel® RealSense™, notamment la SR300, possède tout comme la Kinect une caméra couleur, une caméra infrarouge et un émetteur infrarouge. Portée en profondeur: 0.2m à 1.5m
Kinect V2 - Champ de vision :
Champ de vision horizontal : 70 degrés
Champ de vision vertical : 60 degrés
Portée du capteur : 0,5 m – 4,5 m < br/>
Malheureusement ces caméras nécessitent une connexion en USB 3.0, ce qui n'est pas possible avec la RaspberryPi. C'est pour cela que nous souhaitons nous tourner vers le kit de développement d'Intel contenant une caméra R200 et une carte de prototypage bénéficiant elle d'un port 3.0. Notamment car les concurrents de RaspberryPi proposant une port 3.0 le font à un prix beaucoup plus élevé.
Matériel :
- Intel® RealSense™ Robotic Development Kit:
- Intel RealSense R200 Camera
- AAEON UP Board (Intel Atom™ Processor x5-Z8350, Intel HD Graphics, 4GB DDR3L-1600 memory, 32GB eMMC storage)
- USB 3.0 Type A Female to Micro USB Type B Male Adapter
- USB 3.0 Type B Male to Micro USB Type B Male Cable
- 5V 4A Power supply
https://click.intel.com/intelr-realsensetm-robotic-development-kit-2445.html
Liste des tâches à effectuer
- Connexion de la caméra à la carte
- Fonction pour récupérer l'image vue par la caméra
- Fonction permettant l'extraction des contours sur cette image
- Extraction des contours d'après les modélisations 3D à notre disposition
- Fonction de comparaison
- Connexion de la carte au Robotino
- Fonction permettant l'envoi de l'id de la machine reconnue au Robotino
- Fonction permettant l'envoi de la demande au Robotino de se déplacer pour visualiser une autre phase de la MPS
Calendrier prévisionnel
Réalisation du Projet
Feuille d'heures Janvier
| Tâches Janvier | Séance 1 | Séance 2 | Séance 3 | Total |
|---|---|---|---|---|
| Analyse du projet | 6 | 6 | ||
| Mise en place du protocole de reconnaissance | 1,5 | 3 | 4,5 | |
| Utilisation de la profondeur d'image | 2 | 2 | ||
| Solution IBM - Watson | 0,2 | 0,2 | ||
| Caméra (choix, configuration..) | 1 | 1 | 4 | 6 |
| Gestion des fichiers image (format, récupération, traitement ...) | 0,2 | 3 | 3,2 | |
| Caractéristiques carte (alimentation..) | 1 | 2 | 3 | |
| Algorithme détection lignes et bords | 1,5 | 1,5 | ||
| Wiki | 6 | 3 | 9 | |
| TOTAL | 14,9 | 10 | 10,5 | 35,4 |
Janvier: Séance 1.0
- Prise en main su sujet / mise en place du CDCF,
- Analyse concurrentielle,
- Analyse matérielle,
- Réponse aux questions difficiles/vagues.
Janvier: Séance 1.1 - 15/01/18
- Nous nous orientons vers le choix de la Kinect 360, avec la possibilité de combiner Kinect, ROS et Raspberry.
- Mise en place de la méthode pour reconnaître une MPS:
- le robot se met “face” à la MPS
- si reconnaissance de la MPS avec un pourcentage de concordance correct
- communication au Robotino de l'id de la machine
- sinon analyse d'une autre face de la MPS
- on associe/compare alors les probabilités obtenues pour la 1ère face avec celles de la 2ème
- si on a toujours pas un pourcentage de concordance assez élevé
- analyse d'une 3ème face et ainsi de suite…
- fin au bout de 4 faces repérées
- Mise à jour du wiki
- Mise en place d'un document partagé pour les comptes-rendus des séances et le planning horaire
Janvier: Séance 1.2 - 17/01/18
- Après réunion avec les tuteurs nous avons pu récupérer les fichiers des modélisations 3D des MPS (au format WRL)
- étant donné que toutes les MPS ont une partie basse similaire on pourra centré le traitement d'image pour la différenciation sur la partie haute.
- Amélioration du protocole de reconnaissance:
- récupération de la surface de l'objet grâce au fichier .WRL
- récupération des points infra-rouge de la caméra (mesure de profondeur)
- récupération d’une photo 2D prise avec la caméra
- on pourrait essayer de faire un programme qui passe un plan 3D en 2D →a t'on vraiment besoin de la couleur ? ou on se concentre surtout sur la forme des objets ?
- ainsi on pourrait faire une 1ere comparaison avec photo 2D (si gain de temps par rapport au 3D d'un point de vue traitement d'image)
- avec pourquoi pas du machine learning sur les pièces 2D
- si le taux de comparaison <70%
- on garde le taux de comparaison obtenu en mémoire
- on passe à la comparaison 3D (utilisation du machine learning ? Si oui, algorithme pour reconnaissance d’image et entrainement avec une base de données)
- si taux de comparaison toujours <70%
- même protocole avec une autre face
- si taux de comparaison >70%
- fin de l'algorithme de reconnaissance et envoie de l’ID de la MPS au robotino
Janvier: Séance 1.3 - 18/01/18
On va se baser sur de la reconnaissance d'image 2D et non 3D comme imaginé au début.
- Solution possible, mais non adapté à notre problématique, pour la reconnaissance d'image avec un outil externe:
- celui de google (https://cloud.google.com/ml-engine/)
- celui d’IBM (https://www.ibm.com/watson/services/visual-recognition/ )
- Comment placer la Kinect pour voir toute la partie haute de la MPS :
- champ de vision de la Kinect V1:
- champ de vision horizontal : 57°
- champ de vision vertical : 43°
- portée du capteur : 1,2 m – 3,5 m
- on a alors :

- on en déduit :

- avec:
- x la longueur, largeur ou hauteur de la MPS
- α le champ de vision horizontal ou vertical de la caméra
- d la distance entre le capteur et la MPS
Janvier: Séance 2.0 - 22/01/18
- Avancement sur le pseudo-code:
signal_robotino = variable envoyée par le robotino à la RaspberryPi, on considère qu’il envoie 1 pour indiquer qu’il est bien positionné face à la PMS et que l’analyse peut démarrer et 2 pour indiquer qu’il a bien changé de face
tab = tableau 5 colonnes (une pour chaque MPS) et 2 lignes (la première correspondant à l’id de la MPS et la seconde au nombre de MPS restantes à trouver), initialisé avec le nombre de MPS présentes au départ sur le terrain pour chaque type
main() {
while (signal_robotino==0) {
wait;
}
recuperer_image_camera();
extraction_contour();
comparaison_avec_donnees(MPS_a_analyser);
}
recuperer_image_camera() {
//récupère l’image vue par la camera sous un format permettant le traitement par notre programme
}
extraction_contour() {
//extraction des contours de l’image vue par la camera
//les mets dans un fichier MPS_a_analyser
}
comparaison_avec_donnees(fichier MPS_a_analyser) {
fichiers contenant les contours connus des MPS: MPS_1, MPS_2, MPS_3, MPS_4, MPS_5;
int id=0;
int taux_compare=0;
for (i=1, i++, i<5){
if (tab[i-1][1]>0) {
if (compare(MPS_a_analyser,MPS_i))>taux_compare){
taux_compare=compare(MPS_a_analyser,MPS_i);
id=i;
}
}
if (taux_compare>=70) {
envoi_robotino(id);
modifier_tab(id);
}
if(taux_compare<70) {
envoi_robotino(7);
// on lui indique qu’il doit changer de face
while (signal_robotino!=2) {
wait;
}
recuperer_image_kinect();
extraction_contour();
signal_robotino=1;
comparaison_avec_donnees(MPS_a_analyser);
}
envoi_robotino(int id) {
envoi variable id au robotino;
}
modifier_tableau(int id) {
for (i=1; i++; i<=5) {
if (id=tab[i]) {
tab[i]=tab[i]-1;
}
}
}
}
}
Il faudra penser à écrire une fonction qui vérifie bien que la caméra et la carte sont bien connectées. Il manque le tableau pour mémoriser les taux de comparaison
Janvier: Séance 2.1 - 24/01/18
- Mise à jour du wiki,
- Rendez-vous avec les tuteurs, suite auquel il faudrait :
- trouver la distance pour laquelle la Kinect voit toute la partie haute de la MPS (minimum 0,80m) et vérifier si la profondeur du laser correspond
- --> voir séance 3.1
- estimer si la Raspberry à une puissance de calcul suffisante
- --> voir séance 2.2
- On va communiquer avec le robotino via une connexion sans fil
- voir comment on alimente la Raspberry et la Kinect (avec le Robotino ?)
- ->effectivement possibilité d'alimentation grâce au Robotino, voltages à comparer pour pouvoir adapter l'alimentation.
- nous avons également discuté de l'utilisation de ROS kinetic et d'ubuntu 16.0.4
Janvier: Séance 2.2 - 25/01/18
- Recherche des caractéristiques requises pour la carte électronique.
- Objectifs
- Etre performant pour pouvoir utiliser des algorithmes de machines learning --> deep learning compatible si RAM > 128M0
- Pouvoir assurer l'alimentation de la carte
- Objectifs
- Recherche des caractéristiques de la caméra --> portée minimale pour les mesures de distance = 0,5 m (avec la kinect)
Janvier: Séance 3.0 - 29/01/18
- Affinement de notre choix matériel, nous souhaitons nous orienter vers:
- Raspberry 3 (alimentation 5V, 2.5A)
- Kinect V2 (alimentation avec adaptateur fourni ou utilisation d’un hub usb avec sa propre alimentation)
- A quelle distance de la MPS faudra-t-il placer la Kinect V2 ?
- champs vision Kincet V2 : 70,6°*60°
- dimension MPS 70cm*35cm*x
- donc pour x=70cm et alpha=70,6° on a d=60cm
- donc pour x=35cm et alpha=60° on a d=35cm
Or capteur profondeur fonctionne sur [50cm ; 450cm]
Donc on place le robot a minimum 50cm donc on fait l’hypothèse qu’on se placera toujours a 60-65 cm → recadrage d’image nécessaire pour la largeur dans ce cas
- cf. schéma séance 1.3
Janvier: Séance 3.1 - 31/01/18
- Problème de choix matériel:
- les caméras que nous pourrions utiliser nécessitent toutes une connectique en USB 3.0 alors que les cartes Raspberry ne possèdent pas de port USB 3.0
- donc nous nous orientons vers un kit de développement Intel
- qui contient une caméra SR-200 aux caractéristiques:
- format image couleur : 77*47*70 / 77*43*70 D*V*H (Diagonal, Vertical, Horizontal)
- format image IR : 70*46*59
- Nouveau calcul de la distance nécessaire entre la MPS et le Robotino:
- Couleur
- donc pour x=70cm et alpha=70° on a d=61cm
- donc pour x=35cm et alpha=70° on a d=30,5cm
- IR
- donc pour x=70cm et alpha=59° on a d=71cm
- donc pour x=35cm et alpha=59° on a d=35,5cm
- Couleur
cf. schéma scéance 1.3
- Comment détecter les bords contours d'une MPS sur l'image renvoyée par la caméra ?
- possibilité d'utiliser la librairie OpenCV qui possèdent des fonctions de traitement d'image,
- il sera nécessaire d'appliquer un filtre sur notre image avant traitement, notamment
- - Laplace
- - Sobel
- - Canny
Feuille d'heures Février
| Tâches Février | Prévisionel | Séance 1 | Séance 2 | Séance 3 | Total |
|---|---|---|---|---|---|
| Wiki | 2 | 0,25 | 0,25 | 0,5 | 1 |
| 1. Créer une banque d'image pour chaque MPS | 3 | ||||
| 2. Traitement a faire sur l'image (opencv, filtres ...) | 5 | 4 | 4 | 5 | 13 |
| 3. Récupérer les images depuis la caméra | 4 | 4 | 5 | 4 | 13 |
| 4. Comparaison avec la banque d'image | 8 | ||||
| 5. Positionnement de la camera | 2 | 2 | 2 | ||
| TOTAL | 24 | 10,25 | 9,25 | 9,5 | 19 |
Février : Séance 1 - 07/02/18
- Décomposition du code avec prévision du temps nécessaire à la réalisation
- Possibilité d'utiliser un filtre de Canny (mais le résultat dépend de la qualité de l'image donc à tester), ou un filtre de Prewitt.
- Documentation sur les fonctions findcontours et drawcontours de la librairie openCV
- Problématiques:
- avec l'extraction des contours on risque d'avoir un "dessin" trop précis (à cause des fils ...), trop de détails pour que l’algorithme de comparaison donne des résultats probants.
- on pourrait chercher à reconnaître des formes précises (carrés, rectangles) mais dans ce cas là il y aura des risques liés à l'orientation du robot par rapport à la machine
- Réunion avec les tuteurs
- caméra acquise: BlasterX Senz3D
- nécessité d'un 25 V -> 5V pour alimenter la caméra à partir du Robotino
- validation de l'utilisation des filtres
- validation de la possibilité de ne sélectionner que les points de telle à telle profondeur
Février : Séance 2 - 14/02/18
- Premières tentatives de communication avec la caméra peu concluantes:
- difficultées liées à l'utilisation d'une VM,
- au téléchargement correct de la librairie openCV,
Février : Séance 3 - 21/02/18
- Connexion avec la caméra établie (utilisation d'openCV2, python 3.4.0 et Ubuntu 16.04)
- Test des différents filtres:

(un test face à une MPS viendra bientôt remplacer celui-ci)
A noter que le filtre de Canny prend en compte 2 arguments:
- - seuil bas
- - seuil haut
Il permet d'éliminer des faux contours. En prenant en compte l'intensité du gradient et sa direction, il permet d'éliminer un pixel qui pointe vers 2 valeurs supérieure car ce n'est pas un maximum local. Ensuite il effectue un seuillage par hystérésis. On commence par sélectionner les points qui dépassent le seuil haut et on applique ensuite le seuil bas en ne conservant que les composantes connexes qui contiennent un point au-dessus du seuil haut.
En résumé: (en vert on conserve après filtrage, en orange on ne conserve pas.)

- Éléments pouvant être utiles au projet (à tester au cours des prochaines séances):
- - Extreme Points (topmost, bottommost, rightmost and leftmost)
- - cv2.getAffineTransform et cv2.warpAffine qui permettent une transformation affine
- Compte Rendu de la réunion avec les tuteurs
- -Positionnement de la caméra à définir
- prise de mesures pour la placer, et voir toute la face de la MPS:
- redressement de l'image à réaliser si on place la caméra trop en hauteur (donc inclinaison) (limité à 1m10)
- test concluant avec la caméra placée 30cm au dessus du plateau du Robotino, vers l'arrière) et distance Robotino-MPS=40cm mais d'autres placements sont possibles, en jouant sur l'inclinaison notamment.
- -Récupération de la carte
- USB déjà configuré dans le BIOS
- RAM de 4Go avec plusieurs coeurs --> penser aux threads
- -Récupération d'image possible grâce à des vidéos sur youtube (https://www.youtube.com/channel/UCB5ieBWgXVeg2ih_JMHiDrg)
- -Définir ce qui est clairement identifiable, qu’est ce qui est identique sur toutes les machines (peut être ensuite utilisé pour redresser l'image)
- -On va utiliser ROS pour :
- -faciliter la communication entre le robotino et la carte
- -récupérer les informations de la caméra (IF et image couleur) dans un même fichier
- -Positionnement de la caméra à définir
Feuille d'heures Mars
| Tâches Mars | Prévisionel | Séance 1 | Séance 2 | Séance 3 | Total |
|---|---|---|---|---|---|
| Wiki | 2 | 0,5 | 0,5 | 0,5 | 1,5 |
| 1. Créer une banque d'image pour chaque MPS | 3 | 3 | 3 | ||
| 2. Reconnaissance (Tenserflow) | 8 | 2 | 5 | 6 | 13 |
| 3. Prise en main de ROS associé a la caméra | 8 | 4 | 6 | 6 | 16 |
| TOTAL | 19 | 9,5 | 11,5 | 12,5 | 23,5 |
Mars : Séance 1 - 07/03/18
- Utilisation de blender pour visualiser les fichiers wrl et trouver des similitudes entre les MPS
- Début code pour classifier les images en utilisant TensorFlow
- Installation de ROS
- Découverte des tutoriels d'utilisation de ROS
Mars : Séance 2 - 14/03/18
- Installation de tout les paquets nécessaires (grâce au tutoriel https://github.com/IntelRealSense/librealsense/blob/master/doc/distribution_linux.md#installing-the-packages)
- Connexion avec la caméra établie
- avec le realsense-viewer on arrive bien a récupérer les informations de la caméra:
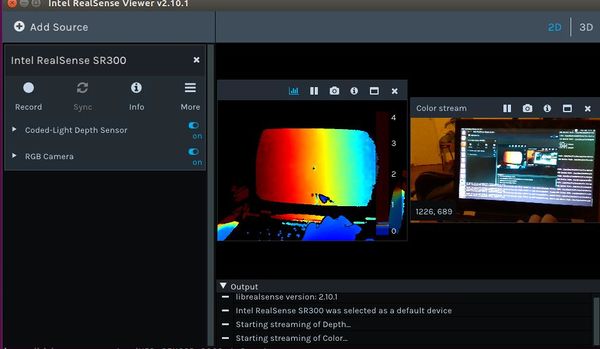
- cependant sur le terminal l'erreur "Failed to read busnum/devnum." apparaît, on obtient la même erreur lorsque l'on essaye de lancer le noeud ROS directement en ligne de commande (roslaunch realsense_ros_camera rs_camera.launch) alors que pourtant la caméra est bien reconnue:

- avec le realsense-viewer on arrive bien a récupérer les informations de la caméra:


Mars : Séance 3 - 21/03/18
Avec la librairie TensorFlow, nous avons un algorithme qui catégorise l'image envoyée en entrée avec une certaine fiabilité.
Pour cela, il faut lui donner une banque d'images pour pouvoir reconnaitre nos MPS.
Pour le moment nous n'avons que 4 MPS modélisées en 3D. Grace à un logiciel, nous avons pris 20 captures d'écran pour chaque MPS. Ce n'est pas beaucoup mais nous avons déjà de bons résultats. Cela est du au programme qui prend des images aléatoires que nous lui avons donné et qui les modifie lors de son entrainement(luminosité, recadrage, rotation de l'image ...).
- Voici quelques tests effectués :
- ligne du haut : Image envoyée à l'algorithme
- ligne du bas : |Résultat après l'exécution (plus la valeur est proche de 1, plus la réponse est fiable)
|
Image quelconque du modèle 3D MPS base |
Partie quelconque du modèle 3D de la MPS base |
Image réel d'une MPS base, prise d'une caméra, lors d'une ancienne compétition |
Image réel d'une MPS base, prise d'une caméra, lors d'une ancienne compétition, recadrée |
|
Le type de la MPS (base) a bien été reconnu. |
Le type de la MPS n'a pas été reconnu. |
Le type de la MPS (base) n'a pas été reconnu et s'est même trompé de machine alors que la fiabilité est à 1. |
Recadré, le type de la MPS (base) a bien été reconnu, avec une fiabilité élevée. |








De ces tests, nous pouvons voir la nécéssité de recadrer l'image. C'est pour cela que nous utilisons ls capteur de distance de la caméra.
Pour encore améliorer les résultats, nous prendrons des photos des MPS sur place car les modèles 3D non aucun cablage et les photos seront prises directement avec la caméra.
- On arrive maintenant à obtenir une connexion valide avec la caméra depuis ROS grâce à la commande "roslaunch realsense_camera sr300_nodelet_rgbd.launch" communiquée par nos tuteurs et non "roslaunch realsense_ros_camera rs_camera.launch" que nous avions trouvée sur les tutoriels ROS.
Mars : Séance 4 - 28/03/18
- Bases d'utilisation de ROS
- Pour exécuter un programme ROS il faut utiliser des fichiers spéciaux: les launch files. Pour lancer un launch file : roslaunch <package_name> <launch_file> qui prend en paramètre le nom du package qui contient le launch file et le launch file lui même. ROS utilise des packages pour organiser ses programmes. Un package contient:
- - dossier launch qui contient les launch files
- - dossier src qui contient les fichiers sources (c++, python ...)
- - fichier CMakeLists.txt qui contient la liste des règles cmake pour la compilation
- - fichier package.xml qui contient les informations/dépendances du package
- Pour aller dans un package: roscd <package_name>
- Tout les fichiers launch contient un <launch> tag, dans ce tag on trouve un <node> tag, dans lequel on spécifie:
- - pkg=“package_name”, nom du package qui contient le code pour le programme ROS a exécuter
- - type=“python_file_name.py”, nom du programme qu'on veut exécuter>
- - name=“node_name”, nom du node qui va launch le fichier Python
- - output=“type_of_output” ,c'est dans cette chaîne qu'on va imprimer la sortie du fichier Python.
- Comment créer un package ?
- - les packages que nous allons créer seront dans le dossier catkin_ws pour qu'ils puissent être exécutés par ROS,
- - roscd permet d'accéder au répertoire catkin_ws/devel,
- - nos packages seront a placer dans catkin_ws/src,
- - catkin_create_pkg <package_name> <package_dependecies> permet de créer un nouveau package,
- - rospack list | grep my_package permet de vérifier que le package a bien été crée.
- Tentative de création de package
- Nous avons d'abord tenté de créer un package d'après les explications juste au dessus, mais nous obtenions une erreur Invalid roslaunch XML syntax: not well-formed
- Supposant qu'il s'agissait d'un problème de mauvaise syntaxe au niveau des paramètres du fichier projet_launch_file.launch, nous avons suivi le tutoriel http://www.theconstructsim.com/ros-for-beginners/ afin de vérifier simplement que nous pouvions créer un package sans erreur avec un fichier python des plus basique. Cependant nous avons toujours le même problème d'erreur de syntaxe XML:

Feuille d'heures Avril
| Tâches Mars | Séance 1 | Séance 2 | Séance 3 | Open German | Total |
|---|---|---|---|---|---|
| Wiki | 0,5 | 0,5 | 1 | ||
| 1. Reconnaissance d'image sur la carte | 2,5 | 2 | 4,5 | ||
| 1. Reconnaissance d'image sur l'ordinateur | 4 | 50 | 54 | ||
| 2. Placement finale de la caméra | 3,5 | 0,5 | 4 | ||
| 3. Récupération des pointCloude2 | 3,5 | 2 | 5,5 | ||
| TOTAL | 9,5 | 4,5 | 4 | 51 | 68 |
Avril : Séance 1 - 04/04/18
- création de package
- Problème de la semaine dernière résolu après recopie a la main du fichier my_package_launch_file.launch, il devait s'agir de la présence d'un caractère non imprimable.
- Placement de la caméra
- choix de la position
- étude du champs de vision réel de la caméra
- Installation de TensorFlow sur la carte
- On a eu un problème car les instructions AVX ne sont pas supportées par la carte
La compétition arrive bientot donc on va se concentrer sur la partie ROS. On fera fonctionner notre programme sur un ordinateur dans un premier temps.
Avril : Séance 2 - 11/04/18
Installation de ROS (sur le deuxième PC)
Détermination de la position exacte de la caméra sur la plateforme du Robotino.
Début du script pour la reconnaissance d'image
Avril : Séance 3 - 18/04/18
- Avancement sur les scripts d’exécution de Tensorflow
- Un script de lancement pour entrainer l'algorithme de reconnaissance d'image
- Un script qui prend en entrée le nom d'une image et retourne le nom de l'objet pris sur la photo avec le pourcentage de certitude
Avril : Semaine de l'Open German
- Installation de Tensorflow (sur le deuxième PC)
- Problème de lancement de Tensorflow via ROS, ROS ne cherchait pas Tensorflow au bon endroit (certainement à cause du multi-versions Python)
- Décision de filtre final
- Tentative de filtre passthrought et voxel grid: échec. Malgré un appel et des paramétrages correspondants aux tutoriels ROS et une compilation sans erreur le filtre ne s'effectue pas.
- Filtre "à la main": tout les pointsclouds récupérés de la caméra dont la distance sur l'axe z est supérieure à la portée infrarouge de la caméra sont transformés en pixels noirs.
- Prise de différents sets d'images des MPS
- Avec caméra correctement placée sur le robot: sans filtre, 2 filtres cannys différents, sobel x, sobel y, laplacien,
- Même chose mais avec caméra à une hauteur aléatoire,
- Caméra sur le robot, proche de la MPS et filtre "à la main"
- Vidéo prise pour chaque MPS, puis découpage en images pour avoir plus de 600 images par MPS
- Ne concernant pas directement le projet
- préparation de l'inventaire
- arbitrage
- montage des robots
- Optimisation de l'algorithme de reconnaissance d'image
- Création de plusieurs algorithmes de reconnaissance d'image (changement de paramètre pour déterminer le meilleur)
- Test de reconnaissance d'image de chaque MPS avec algorithmes
- Analyse des résultats et optimisation du script de reconnaissance
Documents Rendus
Media:Rapport_final_P44_bis.pdf
https://archives.plil.fr/zbriois/PROJET_4A.git